A seção anterior ilustrou como técnicas simples de pré-processamento de dados e aprendizado supervisionado podem ser usadas para projetar um sistema de detecção de fraude de linha de base. Os resultados apresentados basearam-se em dados reprodutíveis, porém simulados. Vamos agora aplicar exatamente a mesma metodologia com dados de transações do mundo real. Por razões de confidencialidade, os dados usados nesta seção não podem ser compartilhados. Embora os resultados apresentados nesta seção não possam ser reproduzidos, eles fornecem insights sobre os desempenhos que seriam obtidos em um cenário do mundo real.
O conjunto de dados usado foi fornecido pela Worldline, e é similar em natureza aos conjuntos de dados usados nas publicações referenciadas em nossa página do ResearchGate - Colaboração conjunta: MLG ULB e Worldline.
Conjuntos de treinamento e teste¶
Mais especificamente, nossos dados do mundo real são transações de e-commerce da Bélgica de 2018. O número de transações diárias é de cerca de 400000. O número de transações fraudulentas diárias era de cerca de 1000, resultando em uma proporção de transações fraudulentas de cerca de 0,25%. O número de cartões comprometidos diariamente era ligeiramente acima de 300: cada cartão comprometido causou uma média de 3 transações fraudulentas por dia. A Fig. 1 resume essas estatísticas diariamente para o período de 2018-07-25 a 2018-08-14.
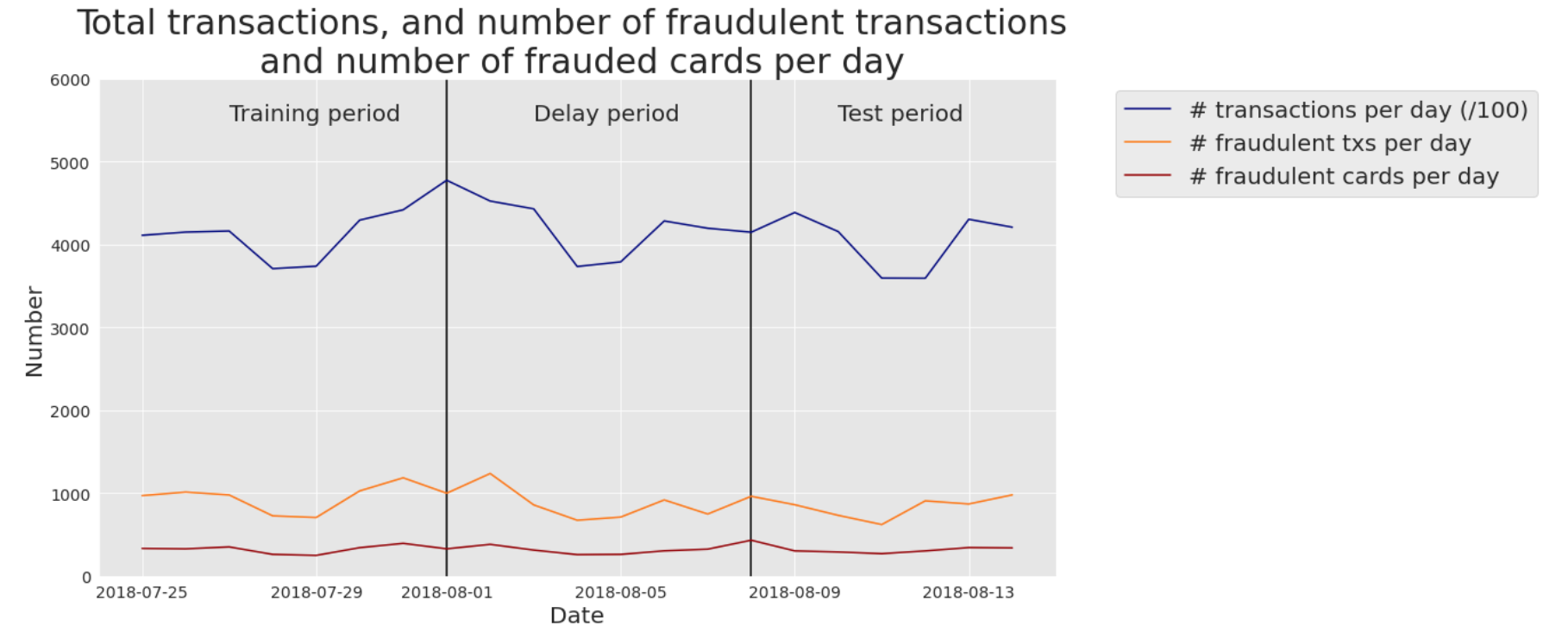
Fig. 1. Dados de transações do mundo real. Número de transações por dia (/100), transações fraudulentas por dia e cartões comprometidos por dia. Período: 2018-07-25 a 2018-08-14.
Treinamento do modelo: Árvore de decisão¶
Primeiro treinamos uma árvore de decisão de profundidade dois. A árvore resultante é mostrada na Fig. 2. Vale notar que as regras de detecção de fraude descobertas pela árvore de decisão diferem das obtidas com dados simulados. O principal padrão de fraude descoberto pela árvore (folha azul no canto inferior direito) consiste em transações que ocorreram em um terminal recentemente comprometido (TERMINAL_ID_RISK_30DAY_WINDOW>0,075) e para as quais o cliente realizou um grande número de transações nas últimas 24 horas (CUSTOMER_ID_NB_TX_1DAY_WINDOW>13,5). Essa regra de fato está relacionada a um comportamento fraudulento comum: os fraudadores geralmente tentam realizar o maior número possível de transações quando conseguem comprometer um cartão de crédito, aumentando assim o número de transações realizadas no último dia.
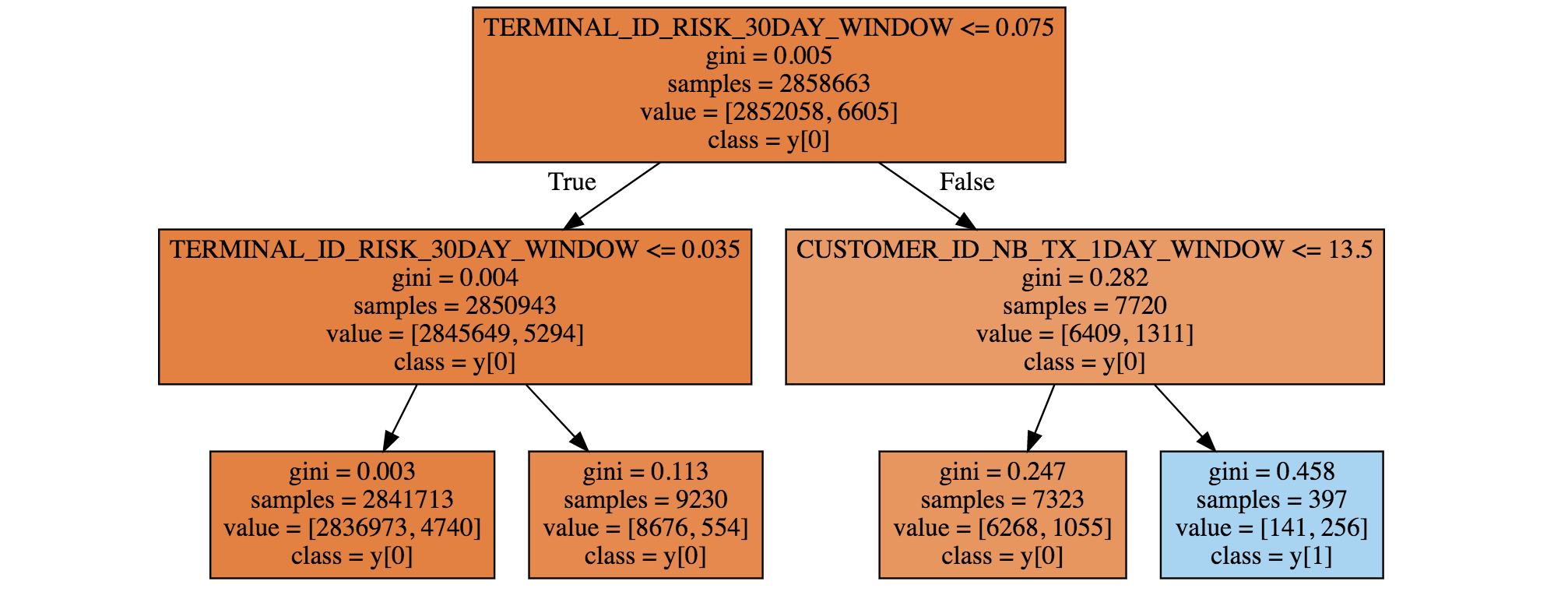
Fig. 2. Árvore de decisão de profundidade dois, obtida usando uma semana de dados do mundo real.
Desempenhos usando modelos de predição padrão¶
Em seguida, executamos os mesmos cinco algoritmos de treinamento da seção anterior: Regressão logística, árvores de decisão de profundidade dois e profundidade ilimitada, floresta aleatória e XGBoost. Os resultados de desempenho no conjunto de teste são reportados na Fig. 3.
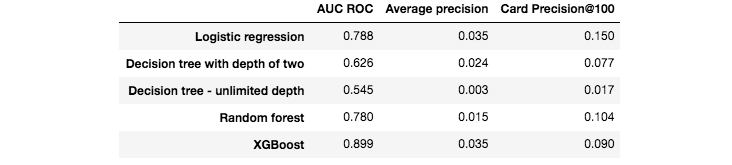
Fig. 3. Desempenhos de detecção de fraude obtidos com cinco algoritmos padrão de aprendizado de máquina no conjunto de teste.
O AUC ROC de todos os modelos é superior a 0,5, o que significa que todos têm desempenho melhor do que um classificador aleatório. Para as três métricas de desempenho, o pior modelo é a árvore de decisão com profundidade ilimitada (AUC ROC próximo de 0,5, o que significa que seu desempenho não é muito melhor que um classificador aleatório). Os melhores modelos são XGBoost e regressão logística, dependendo da métrica de desempenho escolhida. Para AUC ROC e AP, o XGBoost fornece os melhores desempenhos. Para CP@100, o melhor desempenho é fornecido pelo modelo de regressão logística.
Deve-se notar que esses resultados são preliminares e refletem apenas desempenhos obtidos em um pequeno subconjunto dos dados, sem qualquer ajuste dos parâmetros do modelo. Ainda assim, é notável que as taxas de detecção desses modelos de linha de base, em particular para XGBoost e regressão logística, estejam bem acima das de um classificador aleatório. Lembrando que a proporção de transações fraudulentas é de apenas 0,25%, a precisão de cartão@100 de um classificador aleatório deveria ser de cerca de 0,0025 (ou seja, menos de um cartão comprometido detectado por dia). Um modelo simples de regressão logística eleva a CP@100 para 0,15, o que significa que, em média, esse classificador permite detectar corretamente, a cada dia, 15 cartões comprometidos entre os 100 cartões mais suspeitos identificados pelo modelo de predição.
Além dos desempenhos de predição no conjunto de teste, também calculamos os desempenhos de predição no conjunto de treinamento. Eles são reportados na Fig. 4. Vale notar que dois modelos fornecem previsões perfeitas: a árvore de decisão com profundidade ilimitada e a floresta aleatória (AUC ROC de 1). Esses resultados também foram observados para os dados sintéticos (ver seção anterior, Desempenhos usando modelos de predição padrão), e refletem o fenômeno de sobreajuste (overfitting). Os modelos menos sensíveis ao sobreajuste são o modelo de regressão logística e a árvore de decisão com profundidade 2. Faz sentido que as métricas de treinamento de modelos baseados em árvores com profundidade ilimitada (Floresta Aleatória, Árvore de Decisão) alcancem detecção perfeita, pois durante o treinamento esses modelos dividem os dados recursivamente até obter folhas puras.
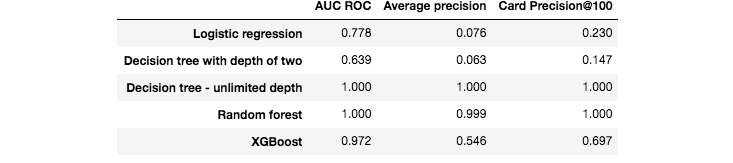
Fig. 4. Desempenhos de detecção de fraude obtidos com cinco algoritmos padrão de aprendizado de máquina no conjunto de treinamento.
Por fim, reportamos os tempos de execução, para treinamento e previsões, desses cinco modelos de predição. Os resultados são apresentados na Fig. 5. Vale notar que os tempos de execução são muito maiores do que com o conjunto de dados simulado. Em particular, os modelos de floresta aleatória e XGBoost foram executados usando um servidor com 20 núcleos. Seus tempos de execução de treinamento são, portanto, cerca de 100 vezes mais longos do que a regressão logística. O XGBoost também possui uma implementação otimizada para GPU que poderia ainda acelerar o treinamento em uma ordem de grandeza.
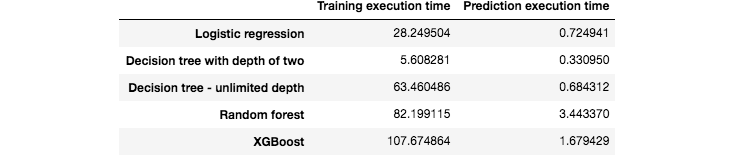
Fig. 5. Tempos de execução para o treinamento e previsões dos cinco algoritmos de aprendizado de máquina.