Esta seção tem como objetivo mostrar como um sistema simples de detecção de fraude pode ser projetado em poucos passos. Usaremos os dados simulados gerados na seção anterior e nos basearemos em uma abordagem de aprendizado supervisionado conforme descrito na seção Metodologia de linha de base - Aprendizado supervisionado do capítulo anterior. A metodologia de aprendizado supervisionado de linha de base é ilustrada na Fig. 1.
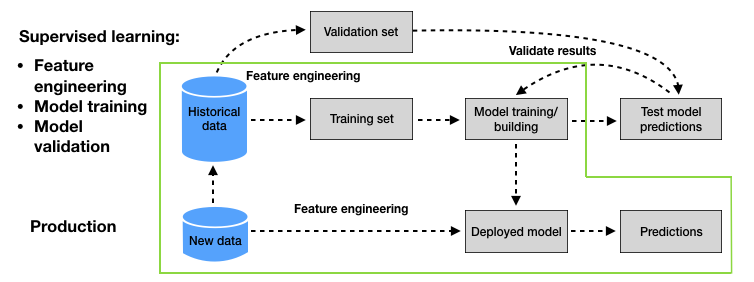
Fig. 1. Metodologia de aprendizado supervisionado de linha de base para detecção de fraude em cartão de crédito. A área verde destaca as etapas que serão implementadas nesta seção.
Por simplicidade, esta seção não abordará a parte de validação da metodologia de aprendizado supervisionado de linha de base. A parte de validação será coberta no Capítulo 5. O design de nosso sistema de detecção de fraude consistirá em três etapas principais, destacadas em verde na Fig. 1:
Definição de um conjunto de treinamento (dados históricos) e um conjunto de teste (dados novos). O conjunto de treinamento é o subconjunto de transações usado para treinar o modelo de predição. O conjunto de teste é o subconjunto de transações usado para avaliar o desempenho do modelo de predição.
Treinamento de um modelo de predição: Esta etapa consiste em usar o conjunto de treinamento para encontrar um modelo de predição capaz de prever se uma transação é legítima ou fraudulenta. Nos basearemos nesta tarefa na biblioteca Python
sklearn, que fornece funções fáceis de usar para treinar modelos de predição.Avaliação do desempenho do modelo de predição: O desempenho do modelo de predição é avaliado usando o conjunto de teste (dados novos).
Detalhamos cada uma dessas etapas no restante desta seção.
# Initialization: Load shared functions and simulated data
# Load shared functions
!curl -O https://raw.githubusercontent.com/Fraud-Detection-Handbook/fraud-detection-handbook/main/Chapter_References/shared_functions.py
%run shared_functions.py
# Get simulated data from Github repository
if not os.path.exists("simulated-data-transformed"):
!git clone https://github.com/Fraud-Detection-Handbook/simulated-data-transformed
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 63076 100 63076 0 0 99k 0 --:--:-- --:--:-- --:--:-- 0:-- --:--:-- 99k
Definição dos conjuntos de treinamento e teste¶
O conjunto de treinamento visa treinar um modelo de predição, enquanto o conjunto de teste visa avaliar o desempenho do modelo de predição em dados novos. Em um contexto de detecção de fraude, as transações do conjunto de teste ocorrem cronologicamente após as transações usadas para treinar o modelo.
Usaremos as transações de 2018-07-25 a 2018-07-31 para o conjunto de treinamento, e de 2018-08-08 a 2018-08-14 para o conjunto de teste. Uma semana de dados será suficiente para treinar um primeiro modelo de predição e avaliar seu desempenho. Posteriormente usaremos períodos maiores para treinamento e teste, a fim de avaliar como conjuntos maiores podem afetar os resultados de desempenho.
Vale notar que escolhemos nosso conjunto de teste para ocorrer uma semana após a última transação do conjunto de treinamento. Em um contexto de detecção de fraude, esse período que separa o conjunto de treinamento e o de teste é referido como o período de atraso ou atraso de feedback Dal Pozzolo et al. (2017). Ele leva em conta o fato de que, em um sistema de detecção de fraude do mundo real, o rótulo de uma transação (fraudulenta ou legítima) só é conhecido após uma reclamação do cliente ou graças ao resultado de uma investigação de fraude. Portanto, em um cenário realista, os dados anotados disponíveis para treinar um modelo e começar a fazer previsões para um determinado dia são anteriores a esse dia menos o período de atraso. Definir um período de atraso de uma semana é simplista. Pressupõe que os rótulos (fraudulento ou legítimo) de todas as transações são conhecidos exatamente uma semana após sua ocorrência. Isso não é o caso na prática, pois o atraso pode ser menor quando os clientes relatam fraudes rapidamente, ou muito maior em casos em que as fraudes permanecem não detectadas por meses. O período de atraso é, na verdade, um parâmetro na avaliação de um modelo de detecção de fraude, que pode ser ajustado durante a etapa de validação (ver Capítulo 5). Um atraso de uma semana é, como primeira aproximação, uma base razoável: pela experiência, as estatísticas geralmente mostram que a maior parte do feedback fica disponível após um atraso de uma semana.
Vamos carregar as transações de 2018-07-25 a 2018-08-14 e plotar o número de transações por dia, transações fraudulentas por dia e cartões fraudulentos por dia.
Notebook Cell
# Load data from the 2018-07-25 to the 2018-08-14
DIR_INPUT='./simulated-data-transformed/data/'
BEGIN_DATE = "2018-07-25"
END_DATE = "2018-08-14"
print("Load files")
%time transactions_df=read_from_files(DIR_INPUT, BEGIN_DATE, END_DATE)
print("{0} transactions loaded, containing {1} fraudulent transactions".format(len(transactions_df),transactions_df.TX_FRAUD.sum()))
Load files
CPU times: user 48.2 ms, sys: 50.9 ms, total: 99.2 ms
Wall time: 149 ms
201295 transactions loaded, containing 1792 fraudulent transactions
Notebook Cell
# Compute the number of transactions per day, fraudulent transactions per day and fraudulent cards per day
def get_tx_stats(transactions_df, start_date_df="2018-04-01"):
#Number of transactions per day
nb_tx_per_day=transactions_df.groupby(['TX_TIME_DAYS'])['CUSTOMER_ID'].count()
#Number of fraudulent transactions per day
nb_fraudulent_transactions_per_day=transactions_df.groupby(['TX_TIME_DAYS'])['TX_FRAUD'].sum()
#Number of compromised cards per day
nb_compromised_cards_per_day=transactions_df[transactions_df['TX_FRAUD']==1].groupby(['TX_TIME_DAYS']).CUSTOMER_ID.nunique()
tx_stats=pd.DataFrame({"nb_tx_per_day":nb_tx_per_day,
"nb_fraudulent_transactions_per_day":nb_fraudulent_transactions_per_day,
"nb_compromised_cards_per_day":nb_compromised_cards_per_day})
tx_stats=tx_stats.reset_index()
start_date = datetime.datetime.strptime(start_date_df, "%Y-%m-%d")
tx_date=start_date+tx_stats['TX_TIME_DAYS'].apply(datetime.timedelta)
tx_stats['tx_date']=tx_date
return tx_stats
tx_stats=get_tx_stats(transactions_df, start_date_df="2018-04-01")
Notebook Cell
%%capture
# Plot the number of transactions per day, fraudulent transactions per day and fraudulent cards per day
def get_template_tx_stats(ax ,fs,
start_date_training,
title='',
delta_train=7,
delta_delay=7,
delta_test=7,
ylim=300):
ax.set_title(title, fontsize=fs*1.5)
ax.set_ylim([0, ylim])
ax.set_xlabel('Date', fontsize=fs)
ax.set_ylabel('Number', fontsize=fs)
plt.yticks(fontsize=fs*0.7)
plt.xticks(fontsize=fs*0.7)
ax.axvline(start_date_training+datetime.timedelta(days=delta_train), 0,ylim, color="black")
ax.axvline(start_date_test, 0, ylim, color="black")
ax.text(start_date_training+datetime.timedelta(days=2), ylim-20,'Training period', fontsize=fs)
ax.text(start_date_training+datetime.timedelta(days=delta_train+2), ylim-20,'Delay period', fontsize=fs)
ax.text(start_date_training+datetime.timedelta(days=delta_train+delta_delay+2), ylim-20,'Test period', fontsize=fs)
cmap = plt.get_cmap('jet')
colors={'nb_tx_per_day':cmap(0),
'nb_fraudulent_transactions_per_day':cmap(200),
'nb_compromised_cards_per_day':cmap(250)}
fraud_and_transactions_stats_fig, ax = plt.subplots(1, 1, figsize=(15,8))
# Training period
start_date_training = datetime.datetime.strptime("2018-07-25", "%Y-%m-%d")
delta_train = delta_delay = delta_test = 7
end_date_training = start_date_training+datetime.timedelta(days=delta_train-1)
# Test period
start_date_test = start_date_training+datetime.timedelta(days=delta_train+delta_delay)
end_date_test = start_date_training+datetime.timedelta(days=delta_train+delta_delay+delta_test-1)
get_template_tx_stats(ax, fs=20,
start_date_training=start_date_training,
title='Total transactions, and number of fraudulent transactions \n and number of compromised cards per day',
delta_train=delta_train,
delta_delay=delta_delay,
delta_test=delta_test
)
ax.plot(tx_stats['tx_date'], tx_stats['nb_tx_per_day']/50, 'b', color=colors['nb_tx_per_day'], label = '# transactions per day (/50)')
ax.plot(tx_stats['tx_date'], tx_stats['nb_fraudulent_transactions_per_day'], 'b', color=colors['nb_fraudulent_transactions_per_day'], label = '# fraudulent txs per day')
ax.plot(tx_stats['tx_date'], tx_stats['nb_compromised_cards_per_day'], 'b', color=colors['nb_compromised_cards_per_day'], label = '# compromised cards per day')
ax.legend(loc = 'upper left',bbox_to_anchor=(1.05, 1),fontsize=20)
fraud_and_transactions_stats_fig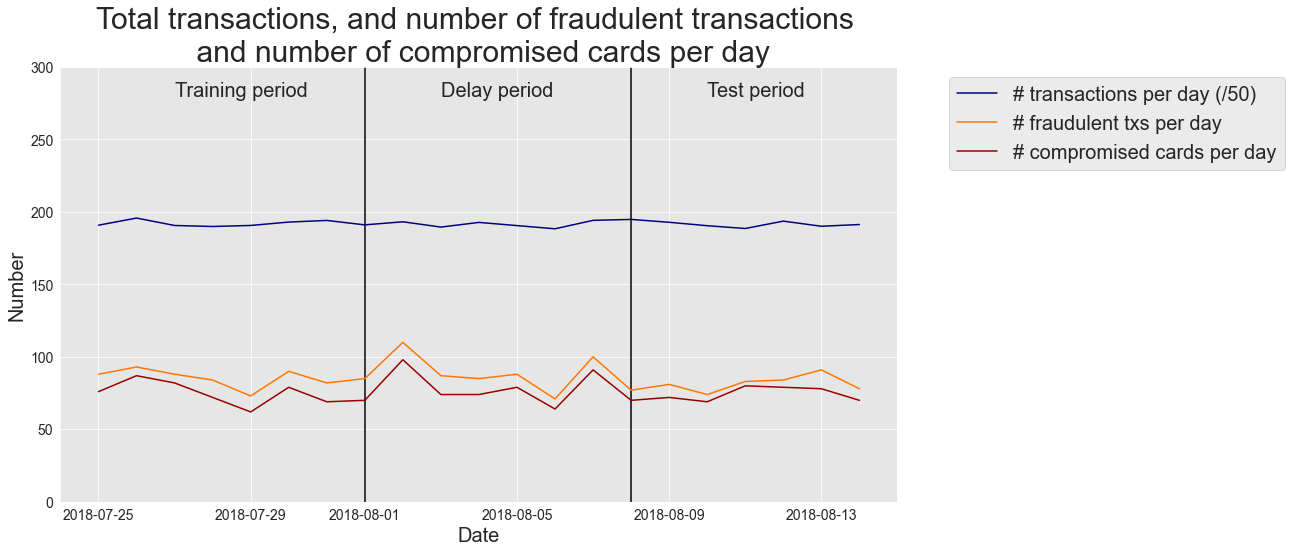
O gráfico ilustra que o número de transações e fraudes é similar nos períodos de treinamento e teste. O número médio de fraudes é de cerca de 85 por dia. Vamos extrair do conjunto de dados as transações para o conjunto de treinamento e o conjunto de teste.
Notebook Cell
def get_train_test_set(transactions_df,
start_date_training,
delta_train=7,delta_delay=7,delta_test=7):
# Get the training set data
train_df = transactions_df[(transactions_df.TX_DATETIME>=start_date_training) &
(transactions_df.TX_DATETIME<start_date_training+datetime.timedelta(days=delta_train))]
# Get the test set data
test_df = []
# Note: Cards known to be compromised after the delay period are removed from the test set
# That is, for each test day, all frauds known at (test_day-delay_period) are removed
# First, get known defrauded customers from the training set
known_defrauded_customers = set(train_df[train_df.TX_FRAUD==1].CUSTOMER_ID)
# Get the relative starting day of training set (easier than TX_DATETIME to collect test data)
start_tx_time_days_training = train_df.TX_TIME_DAYS.min()
# Then, for each day of the test set
for day in range(delta_test):
# Get test data for that day
test_df_day = transactions_df[transactions_df.TX_TIME_DAYS==start_tx_time_days_training+
delta_train+delta_delay+
day]
# Compromised cards from that test day, minus the delay period, are added to the pool of known defrauded customers
test_df_day_delay_period = transactions_df[transactions_df.TX_TIME_DAYS==start_tx_time_days_training+
delta_train+
day-1]
new_defrauded_customers = set(test_df_day_delay_period[test_df_day_delay_period.TX_FRAUD==1].CUSTOMER_ID)
known_defrauded_customers = known_defrauded_customers.union(new_defrauded_customers)
test_df_day = test_df_day[~test_df_day.CUSTOMER_ID.isin(known_defrauded_customers)]
test_df.append(test_df_day)
test_df = pd.concat(test_df)
# Sort data sets by ascending order of transaction ID
train_df=train_df.sort_values('TRANSACTION_ID')
test_df=test_df.sort_values('TRANSACTION_ID')
return (train_df, test_df)(train_df, test_df)=get_train_test_set(transactions_df,start_date_training,
delta_train=7,delta_delay=7,delta_test=7)O conjunto de treinamento contém 67240 transações, das quais 598 são fraudulentas.
train_df.shape(67240, 23)train_df[train_df.TX_FRAUD==1].shape
(598, 23)O conjunto de teste contém 58264 transações, das quais 385 são fraudulentas.
test_df.shape(58264, 23)test_df[test_df.TX_FRAUD==1].shape
(385, 23)Ou seja, uma proporção de 0,007 de transações fraudulentas.
385/582640.00660785390635727Treinamento do modelo: Árvore de decisão¶
Conforme explicado na seção Metodologia de linha de base - Aprendizado supervisionado, o treinamento de um modelo de predição consiste em identificar uma relação matemática entre dois conjuntos de características, chamadas características de entrada e de saída. Em um contexto de detecção de fraude, o objetivo é encontrar uma função capaz de prever se uma transação é fraudulenta ou legítima (a característica de saída), usando características que caracterizam as transações (as características de entrada).
Definiremos as características de entrada e saída da seguinte forma:
A característica de saída será o rótulo da transação
TX_FRAUDAs características de entrada serão o valor da transação
TX_AMOUNT, bem como todas as características calculadas na seção anterior, que caracterizam o contexto de uma transação.
output_feature="TX_FRAUD"
input_features=['TX_AMOUNT','TX_DURING_WEEKEND', 'TX_DURING_NIGHT', 'CUSTOMER_ID_NB_TX_1DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_1DAY_WINDOW', 'CUSTOMER_ID_NB_TX_7DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_7DAY_WINDOW', 'CUSTOMER_ID_NB_TX_30DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_30DAY_WINDOW', 'TERMINAL_ID_NB_TX_1DAY_WINDOW',
'TERMINAL_ID_RISK_1DAY_WINDOW', 'TERMINAL_ID_NB_TX_7DAY_WINDOW',
'TERMINAL_ID_RISK_7DAY_WINDOW', 'TERMINAL_ID_NB_TX_30DAY_WINDOW',
'TERMINAL_ID_RISK_30DAY_WINDOW']
Em Python, o treinamento de um modelo de predição é facilitado pelo uso da biblioteca sklearn. Em particular, a biblioteca sklearn fornece implementações para treinar uma ampla gama de modelos de predição.
O treinamento de modelos de predição será abordado com mais detalhes no Capítulo 5, Seleção de Modelos. Por ora, simplesmente treinaremos alguns classificadores padrão, sem entrar nos detalhes de como o treinamento é realmente realizado.
Começaremos utilizando um modelo de predição chamado árvore de decisão.
Vamos criar uma função fit_model_and_get_predictions que treina um modelo e retorna previsões para um conjunto de teste. A função recebe como entrada um objeto classificador sklearn (um modelo de predição sklearn), um conjunto de treinamento, um conjunto de teste e o conjunto de características de entrada e saída. O conjunto de treinamento será usado para treinar o classificador. Isso é feito chamando o método fit do objeto classificador sklearn. As previsões do classificador para os conjuntos de treinamento e teste são então obtidas chamando o método predict_proba do objeto classificador sklearn (cf. Capítulo 4).
A função retorna um dicionário que contém o classificador treinado, as previsões para o conjunto de treinamento, as previsões para o conjunto de teste e os tempos de execução para treinamento e inferência.
Notebook Cell
def fit_model_and_get_predictions(classifier, train_df, test_df,
input_features, output_feature="TX_FRAUD",scale=True):
# By default, scales input data
if scale:
(train_df, test_df)=scaleData(train_df,test_df,input_features)
# We first train the classifier using the `fit` method, and pass as arguments the input and output features
start_time=time.time()
classifier.fit(train_df[input_features], train_df[output_feature])
training_execution_time=time.time()-start_time
# We then get the predictions on the training and test data using the `predict_proba` method
# The predictions are returned as a numpy array, that provides the probability of fraud for each transaction
start_time=time.time()
predictions_test=classifier.predict_proba(test_df[input_features])[:,1]
prediction_execution_time=time.time()-start_time
predictions_train=classifier.predict_proba(train_df[input_features])[:,1]
# The result is returned as a dictionary containing the fitted models,
# and the predictions on the training and test sets
model_and_predictions_dictionary = {'classifier': classifier,
'predictions_test': predictions_test,
'predictions_train': predictions_train,
'training_execution_time': training_execution_time,
'prediction_execution_time': prediction_execution_time
}
return model_and_predictions_dictionaryComo exemplo, vamos treinar uma árvore de decisão pequena (com profundidade máxima de 2). Primeiro criamos um objeto de árvore de decisão (sklearn.tree.DecisionTreeClassifier) e chamamos fit_model_and_get_predictions_dictionary para treinar a árvore de decisão e obter as previsões nos conjuntos de treinamento e teste.
# We first create a decision tree object. We will limit its depth to 2 for interpretability,
# and set the random state to zero for reproducibility
classifier = sklearn.tree.DecisionTreeClassifier(max_depth = 2, random_state=0)
model_and_predictions_dictionary = fit_model_and_get_predictions(classifier, train_df, test_df,
input_features, output_feature,
scale=False)Vamos analisar as previsões obtidas para as primeiras cinco transações do conjunto de teste:
test_df['TX_FRAUD_PREDICTED']=model_and_predictions_dictionary['predictions_test']
test_df.head()A probabilidade de fraude para todas essas transações é de 0,003536. Podemos exibir a árvore de decisão para entender como essas probabilidades foram definidas:
display(graphviz.Source(sklearn.tree.export_graphviz(classifier,feature_names=input_features,class_names=True, filled=True)))Uma árvore de decisão permite dividir o espaço de entrada em diferentes regiões, de forma que as transações fraudulentas sejam separadas das transações legítimas. O último nível da árvore (as folhas) indica o número de transações fraudulentas e legítimas de treinamento em cada uma dessas regiões. A cor indica se um nó ou folha da árvore contém maioria de transações legítimas (laranja) ou fraudulentas (azul).
Cada uma das cinco primeiras transações cai na primeira folha, uma região que contém 236 transações fraudulentas e 66498 transações legítimas, ou seja, uma região onde a probabilidade de fraude é .
Vale notar que a árvore de decisão encontrou corretamente que transações com valor alto são fraudes (cenário 1 no processo de geração de fraudes). A região correspondente é a segunda folha. O limiar de decisão (218,67) não é encontrado de forma ideal, pois a segunda folha contém 2 transações legítimas classificadas incorretamente. O limiar ótimo deveria ser 220, conforme definido no cenário 1, mas foi apenas empiricamente ajustado a partir dos dados de treinamento que representam uma amostra da distribuição geral dos dados.
Avaliação de desempenho¶
Vamos finalmente avaliar o desempenho deste modelo de árvore de decisão. Calcularemos três métricas de desempenho: AUC ROC, Precisão Média (AP) e Precisão de Cartão top- (CP@k). A motivação para essas três métricas será abordada no Capítulo 4. Por ora, é suficiente saber que:
A Precisão de Cartão top- é a medida mais pragmática e interpretável. Ela leva em conta o fato de que os investigadores só podem verificar no máximo cartões potencialmente fraudulentos por dia. É calculada classificando, para cada dia no conjunto de teste, as transações mais fraudulentas e selecionando os cartões cujas transações têm as maiores probabilidades de fraude. A precisão (proporção de cartões realmente comprometidos em relação aos cartões previstos como comprometidos) é então calculada para cada dia. A Precisão de Cartão top- é a média dessas precisões diárias. O número será definido como 100 (ou seja, assume-se que apenas 100 cartões podem ser verificados a cada dia). A métrica é descrita em detalhes no Capítulo 4, Métricas de Precisão top-k.
A Precisão Média é uma aproximação da Precisão de Cartão top- que integra precisões para todos os valores possíveis de . A métrica é descrita em detalhes no Capítulo 4, Curva Precisão-Recall.
O AUC ROC é uma medida alternativa à Precisão Média, que dá mais importância às pontuações obtidas com valores maiores de . É menos relevante na prática, pois os desempenhos que mais importam são aqueles para valores baixos de . No entanto, também o reportamos por ser a métrica de desempenho mais amplamente usada para detecção de fraude na literatura. A métrica é descrita em detalhes no Capítulo 4, Curva ROC (Receiver Operating Characteristic).
Note que todas as três métricas fornecem valores no intervalo , e que valores mais altos significam melhor desempenho.
Fornecemos a implementação abaixo para calcular essas três métricas de desempenho. Os detalhes de sua implementação serão abordados no Capítulo 4.
def card_precision_top_k_day(df_day,top_k):
# This takes the max of the predictions AND the max of label TX_FRAUD for each CUSTOMER_ID,
# and sorts by decreasing order of fraudulent prediction
df_day = df_day.groupby('CUSTOMER_ID').max().sort_values(by="predictions", ascending=False).reset_index(drop=False)
# Get the top k most suspicious cards
df_day_top_k=df_day.head(top_k)
list_detected_compromised_cards=list(df_day_top_k[df_day_top_k.TX_FRAUD==1].CUSTOMER_ID)
# Compute precision top k
card_precision_top_k = len(list_detected_compromised_cards) / top_k
return list_detected_compromised_cards, card_precision_top_k
def card_precision_top_k(predictions_df, top_k, remove_detected_compromised_cards=True):
# Sort days by increasing order
list_days=list(predictions_df['TX_TIME_DAYS'].unique())
list_days.sort()
# At first, the list of detected compromised cards is empty
list_detected_compromised_cards = []
card_precision_top_k_per_day_list = []
nb_compromised_cards_per_day = []
# For each day, compute precision top k
for day in list_days:
df_day = predictions_df[predictions_df['TX_TIME_DAYS']==day]
df_day = df_day[['predictions', 'CUSTOMER_ID', 'TX_FRAUD']]
# Let us remove detected compromised cards from the set of daily transactions
df_day = df_day[df_day.CUSTOMER_ID.isin(list_detected_compromised_cards)==False]
nb_compromised_cards_per_day.append(len(df_day[df_day.TX_FRAUD==1].CUSTOMER_ID.unique()))
detected_compromised_cards, card_precision_top_k = card_precision_top_k_day(df_day,top_k)
card_precision_top_k_per_day_list.append(card_precision_top_k)
# Let us update the list of detected compromised cards
if remove_detected_compromised_cards:
list_detected_compromised_cards.extend(detected_compromised_cards)
# Compute the mean
mean_card_precision_top_k = np.array(card_precision_top_k_per_day_list).mean()
# Returns precision top k per day as a list, and resulting mean
return nb_compromised_cards_per_day,card_precision_top_k_per_day_list,mean_card_precision_top_k
def performance_assessment(predictions_df, output_feature='TX_FRAUD',
prediction_feature='predictions', top_k_list=[100],
rounded=True):
AUC_ROC = metrics.roc_auc_score(predictions_df[output_feature], predictions_df[prediction_feature])
AP = metrics.average_precision_score(predictions_df[output_feature], predictions_df[prediction_feature])
performances = pd.DataFrame([[AUC_ROC, AP]],
columns=['AUC ROC','Average precision'])
for top_k in top_k_list:
_, _, mean_card_precision_top_k = card_precision_top_k(predictions_df, top_k)
performances['Card Precision@'+str(top_k)]=mean_card_precision_top_k
if rounded:
performances = performances.round(3)
return performancesVamos calcular o desempenho em termos de AUC ROC, Precisão Média (AP) e Precisão de Cartão top 100 (CP@100) para a árvore de decisão.
predictions_df=test_df
predictions_df['predictions']=model_and_predictions_dictionary['predictions_test']
performance_assessment(predictions_df, top_k_list=[100])A métrica mais interpretável é a Precisão de Cartão@100, que nos diz que, a cada dia, 24% dos cartões com as maiores pontuações de fraude eram de fato comprometidos. Como o percentual de fraudes no conjunto de teste é de 0,7%, essa proporção de fraudes detectadas é alta e significa que o classificador de fato consegue fazer muito melhor do que o acaso.
A interpretação do AUC ROC e da Precisão Média é menos direta. No entanto, por definição, sabe-se que um classificador aleatório daria um AUC ROC de 0,5 e uma Precisão Média de 0,007 (a proporção de fraudes no conjunto de teste). Os valores obtidos são muito maiores (0,764) e (0,496), confirmando a capacidade do classificador de fornecer previsões muito melhores do que um modelo aleatório.
Nota: O desempenho de um modelo aleatório pode ser calculado simplesmente definindo todas as previsões para uma probabilidade de :
predictions_df['predictions']=0.5
performance_assessment(predictions_df, top_k_list=[100])Desempenhos usando modelos de predição padrão¶
Agora temos todos os blocos de construção para treinar e avaliar outros classificadores. Além da árvore de decisão com profundidade 2, vamos treinar quatro outros modelos de predição: uma árvore de decisão com profundidade ilimitada, um modelo de regressão logística, uma floresta aleatória e um modelo de boosting (consulte a célula de importações para detalhes das bibliotecas). Esses modelos são os mais comumente usados em benchmarks na literatura de detecção de fraude Yousefi et al. (2019)Priscilla & Prabha (2019).
Para esse fim, vamos primeiro criar um dicionário de classificadores sklearn que instancia cada um desses classificadores. Em seguida, treinamos e calculamos as previsões para cada um desses classificadores usando a função fit_model_and_get_predictions.
classifiers_dictionary={'Logistic regression':sklearn.linear_model.LogisticRegression(random_state=0),
'Decision tree with depth of two':sklearn.tree.DecisionTreeClassifier(max_depth=2,random_state=0),
'Decision tree - unlimited depth':sklearn.tree.DecisionTreeClassifier(random_state=0),
'Random forest':sklearn.ensemble.RandomForestClassifier(random_state=0,n_jobs=-1),
'XGBoost':xgboost.XGBClassifier(random_state=0,n_jobs=-1),
}
fitted_models_and_predictions_dictionary={}
for classifier_name in classifiers_dictionary:
model_and_predictions = fit_model_and_get_predictions(classifiers_dictionary[classifier_name], train_df, test_df,
input_features=input_features,
output_feature=output_feature)
fitted_models_and_predictions_dictionary[classifier_name]=model_and_predictions
[11:36:54] WARNING: /private/var/folders/2y/mv3z1v0945b60_l2bzjwpzj80000gn/T/pip-install-v081hmhv/xgboost_5f8c79180547427599a229ec66faab67/build/temp.macosx-10.9-x86_64-3.9/xgboost/src/learner.cc:1115: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
Vamos finalmente avaliar os desempenhos de predição desses cinco modelos, no conjunto de teste e no conjunto de treinamento, e seus tempos de execução.
def performance_assessment_model_collection(fitted_models_and_predictions_dictionary,
transactions_df,
type_set='test',
top_k_list=[100]):
performances=pd.DataFrame()
for classifier_name, model_and_predictions in fitted_models_and_predictions_dictionary.items():
predictions_df=transactions_df
predictions_df['predictions']=model_and_predictions['predictions_'+type_set]
performances_model=performance_assessment(predictions_df, output_feature='TX_FRAUD',
prediction_feature='predictions', top_k_list=top_k_list)
performances_model.index=[classifier_name]
performances=performances.append(performances_model)
return performances# performances on test set
df_performances=performance_assessment_model_collection(fitted_models_and_predictions_dictionary, test_df,
type_set='test',
top_k_list=[100])
df_performances# performances on training set
df_performances=performance_assessment_model_collection(fitted_models_and_predictions_dictionary, train_df,
type_set='train',
top_k_list=[100])
df_performancesdef execution_times_model_collection(fitted_models_and_predictions_dictionary):
execution_times=pd.DataFrame()
for classifier_name, model_and_predictions in fitted_models_and_predictions_dictionary.items():
execution_times_model=pd.DataFrame()
execution_times_model['Training execution time']=[model_and_predictions['training_execution_time']]
execution_times_model['Prediction execution time']=[model_and_predictions['prediction_execution_time']]
execution_times_model.index=[classifier_name]
execution_times=execution_times.append(execution_times_model)
return execution_times# Execution times
df_execution_times=execution_times_model_collection(fitted_models_and_predictions_dictionary)
df_execution_timesOs principais pontos a destacar nesses resultados de desempenho são:
Todos os modelos de predição aprenderam padrões de fraude úteis a partir dos dados de treinamento. Isso pode ser observado pelo AUC ROC no conjunto de teste, que é maior que 0,5 para todos os classificadores, e uma precisão média muito maior que 0,007.
A floresta aleatória e os modelos de boosting fornecem melhor desempenho (em termos de Precisão Média) do que a regressão logística e as árvores de decisão. Isso também é amplamente relatado na literatura de detecção de fraude.
Os desempenhos relativos dos classificadores diferem dependendo de qual métrica de desempenho é usada. Por exemplo, uma árvore de decisão de profundidade 2 tem um AUC ROC menor do que uma árvore de decisão de profundidade ilimitada, mas uma precisão média maior. Entender precisamente o que esses desempenhos significam é crucial, e será abordado no próximo capítulo.
O desempenho de alguns classificadores (Floresta Aleatória e Árvore de Decisão com profundidade ilimitada) é perfeito no conjunto de treinamento (AUC ROC e Precisão Média de 1), mas menor no conjunto de teste. Na verdade, a árvore de decisão com profundidade ilimitada é o pior classificador no conjunto de teste em termos de Precisão Média. Este é um exemplo de um fenômeno chamado sobreajuste (overfitting), que deve ser evitado. Este problema será abordado com mais detalhes no Capítulo 5.
Como esperado, os tempos de execução para treinar conjuntos de modelos (Floresta Aleatória e XGBoost) são significativamente maiores do que modelos individuais (árvores de decisão e regressão logística).
- Dal Pozzolo, A., Boracchi, G., Caelen, O., Alippi, C., & Bontempi, G. (2017). Credit card fraud detection: a realistic modeling and a novel learning strategy. IEEE Transactions on Neural Networks and Learning Systems, 29(8), 3784–3797.
- Yousefi, N., Alaghband, M., & Garibay, I. (2019). A Comprehensive Survey on Machine Learning Techniques and User Authentication Approaches for Credit Card Fraud Detection. arXiv Preprint arXiv:1912.02629.
- Priscilla, C. V., & Prabha, D. P. (2019). Credit Card Fraud Detection: A Systematic Review. International Conference on Information, Communication and Computing Technology, 290–303.