Esta seção aborda a relevância de um SDF de cartão de crédito de uma perspectiva mais operacional, considerando explicitamente seus benefícios para os investigadores de fraude. Vamos primeiro lembrar que o propósito de um SDF é fornecer aos investigadores alertas, ou seja, um conjunto de transações que se assume serem as mais suspeitas (ver Seção Sistema de detecção de fraude de cartão de crédito). Essas transações são verificadas manualmente, contatando o titular do cartão. O processo de contatar os titulares de cartão é demorado e o número de investigadores de fraude é limitado. O número de alertas que podem ser verificados durante um determinado período é, portanto, necessariamente limitado.
As métricas de Precisão top- visam quantificar o desempenho de um SDF nesse contexto Dal Pozzolo et al. (2017)Dal Pozzolo (2015)Fan & Zhu (2011). As precisões são calculadas diariamente, refletindo as precisões obtidas para um dia de trabalho dos investigadores de fraude. O parâmetro quantifica o número máximo de alertas que podem ser verificados pelos investigadores em um dia.
Formalmente, para um dia , vamos denotar por o conjunto de transações. Apenas uma minoria de transações é fraudulenta, enquanto a maioria é legítima. Vamos ainda denotar por o conjunto de alertas. O conjunto de alertas contém tanto verdadeiros positivos () quanto falsos positivos (). A Fig. 1 fornece uma ilustração esquemática.
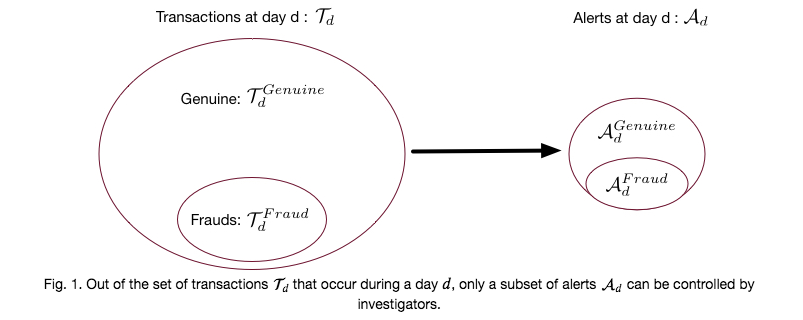
Denotando por o número de alertas que os investigadores podem processar durante um dia, e por a cardinalidade de um conjunto, temos , com .
Nesse contexto, o desempenho de um classificador é maximizar a precisão no subconjunto , ou seja, maximizar
Essa quantidade é referida como a Precisão top- para o dia Dal Pozzolo et al. (2017)Dal Pozzolo (2015), ou . Uma alternativa a essa medida é a Precisão de Cartão top-, que mede a Precisão top- em termos de cartões em vez de transações autorizadas. Múltiplas transações em do mesmo cartão devem ser contadas como um único alerta, pois os investigadores verificam todas as transações recentes ao contatar os titulares de cartão. A Precisão de Cartão top- para o dia é referida como .
Detalhamos ambas essas métricas a seguir, junto com suas implementações.
Notebook Cell
# Initialization: Load shared functions and simulated data
# Load shared functions
!curl -O https://raw.githubusercontent.com/Fraud-Detection-Handbook/fraud-detection-handbook/main/Chapter_References/shared_functions.py
%run shared_functions.py
# Get simulated data from Github repository
if not os.path.exists("simulated-data-transformed"):
!git clone https://github.com/Fraud-Detection-Handbook/simulated-data-transformed
Precisão top-¶
Vamos reutilizar a configuração de detecção de fraude de linha de base, usando uma semana de dados para treinamento e uma semana de dados para testar os desempenhos de detecção. Uma árvore de decisão de profundidade dois é usada como modelo de predição.
Notebook Cell
# Load data from the 2018-07-25 to the 2018-08-14
DIR_INPUT='./simulated-data-transformed/data/'
BEGIN_DATE = "2018-07-25"
END_DATE = "2018-08-14"
print("Load files")
%time transactions_df=read_from_files(DIR_INPUT, BEGIN_DATE, END_DATE)
print("{0} transactions loaded, containing {1} fraudulent transactions".format(len(transactions_df),transactions_df.TX_FRAUD.sum()))
start_date_training = datetime.datetime.strptime("2018-07-25", "%Y-%m-%d")
delta_train=delta_delay=delta_test=7
(train_df,test_df)=get_train_test_set(transactions_df,start_date_training,
delta_train=delta_train,delta_delay=delta_delay,delta_test=delta_test)
output_feature="TX_FRAUD"
input_features=['TX_AMOUNT','TX_DURING_WEEKEND', 'TX_DURING_NIGHT', 'CUSTOMER_ID_NB_TX_1DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_1DAY_WINDOW', 'CUSTOMER_ID_NB_TX_7DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_7DAY_WINDOW', 'CUSTOMER_ID_NB_TX_30DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_30DAY_WINDOW', 'TERMINAL_ID_NB_TX_1DAY_WINDOW',
'TERMINAL_ID_RISK_1DAY_WINDOW', 'TERMINAL_ID_NB_TX_7DAY_WINDOW',
'TERMINAL_ID_RISK_7DAY_WINDOW', 'TERMINAL_ID_NB_TX_30DAY_WINDOW',
'TERMINAL_ID_RISK_30DAY_WINDOW']
classifier = sklearn.tree.DecisionTreeClassifier(max_depth = 2, random_state=0)
model_and_predictions_dictionary = fit_model_and_get_predictions(classifier, train_df, test_df,
input_features, output_feature) Load files
CPU times: user 47.8 ms, sys: 49 ms, total: 96.8 ms
Wall time: 140 ms
201295 transactions loaded, containing 1792 fraudulent transactions
As previsões para a semana de teste são retornadas na entrada predictions_test do dicionário model_and_predictions_dictionary. predictions_test é um vetor que contém as probabilidades de fraude para cada uma das transações no DataFrame test_df. Podemos verificar que o número de previsões é igual ao número de transações:
assert len(model_and_predictions_dictionary['predictions_test'])==len(test_df)Vamos adicionar essas previsões como uma nova coluna no DataFrame de transações de teste e exibir as cinco primeiras linhas.
predictions_df=test_df
predictions_df['predictions']=model_and_predictions_dictionary['predictions_test']
predictions_df[['TRANSACTION_ID','TX_DATETIME','CUSTOMER_ID','TERMINAL_ID','TX_AMOUNT','TX_TIME_DAYS','TX_FRAUD','predictions']].head()O pode ser calculado para um dia classificando todas as probabilidades de fraude em ordem decrescente e calculando a precisão para as transações melhor classificadas. Vamos por exemplo calcular a precisão obtida nas 100 transações principais, para o primeiro dia de transações no conjunto de teste (dia 129).
def precision_top_k_day(df_day, top_k=100):
# Order transactions by decreasing probabilities of frauds
df_day = df_day.sort_values(by="predictions", ascending=False).reset_index(drop=False)
# Get the top k most suspicious transactions
df_day_top_k=df_day.head(top_k)
list_detected_fraudulent_transactions=list(df_day_top_k[df_day_top_k.TX_FRAUD==1].TRANSACTION_ID)
# Compute precision top k
precision_top_k = len(list_detected_fraudulent_transactions) / top_k
return list_detected_fraudulent_transactions, precision_top_k
day=129
df_day = predictions_df[predictions_df['TX_TIME_DAYS']==day]
df_day = df_day[['TRANSACTION_ID','CUSTOMER_ID', 'TX_FRAUD', 'predictions']]
_, precision_top_k= precision_top_k_day(df_day=df_day, top_k=100)
precision_top_k
0.26Obtemos uma precisão de 0,26, ou seja, 26 das cem transações mais suspeitas foram de fato transações fraudulentas.
Deve-se notar que o valor mais alto alcançável para o pode ser menor que 1. Esse é o caso quando é maior que o número de transações fraudulentas para um determinado dia. No exemplo acima, o número de transações fraudulentas no dia 129 é 55.
df_day.TX_FRAUD.sum()55Como resultado, o máximo que pode ser alcançado é 55/100=0,55.
Quando um conjunto de teste abrange vários dias, seja a média de para um conjunto de dias Dal Pozzolo et al. (2017)Dal Pozzolo (2015), ou seja:
Vamos implementar essa pontuação com uma função precision_top_k, que recebe como entrada um DataFrame predictions_df e um limiar top_k. A função percorre todos os dias do DataFrame e calcula para cada dia o número de transações fraudulentas e a precisão top-. Ela retorna esses valores para todos os dias como listas, juntamente com a média resultante das precisões top-.
def precision_top_k(predictions_df, top_k=100):
# Sort days by increasing order
list_days=list(predictions_df['TX_TIME_DAYS'].unique())
list_days.sort()
precision_top_k_per_day_list = []
nb_fraudulent_transactions_per_day = []
# For each day, compute precision top k
for day in list_days:
df_day = predictions_df[predictions_df['TX_TIME_DAYS']==day]
df_day = df_day[['TRANSACTION_ID', 'CUSTOMER_ID', 'TX_FRAUD', 'predictions']]
nb_fraudulent_transactions_per_day.append(len(df_day[df_day.TX_FRAUD==1]))
_, _precision_top_k = precision_top_k_day(df_day, top_k=top_k)
precision_top_k_per_day_list.append(_precision_top_k)
# Compute the mean
mean_precision_top_k = np.round(np.array(precision_top_k_per_day_list).mean(),3)
# Returns number of fraudulent transactions per day,
# precision top k per day, and resulting mean
return nb_fraudulent_transactions_per_day,precision_top_k_per_day_list,mean_precision_top_k
Aplicando esta função ao prediction_df, com , obtemos:
nb_fraudulent_transactions_per_day_remaining,\
precision_top_k_per_day_list,\
mean_precision_top_k = precision_top_k(predictions_df=predictions_df, top_k=100)
print("Number of remaining fraudulent transactions: "+str(nb_fraudulent_transactions_per_day_remaining))
print("Precision top-k: "+str(precision_top_k_per_day_list))
print("Average Precision top-k: "+str(mean_precision_top_k))Number of remaining fraudulent transactions: [55, 60, 56, 56, 59, 58, 41]
Precision top-k: [0.26, 0.35, 0.26, 0.33, 0.3, 0.35, 0.19]
Average Precision top-k: 0.291
Para melhor visualização, vamos plotar esses dados. Reutilizamos a função de plotagem introduzida em Definição dos conjuntos de treinamento e teste (importada do notebook de funções compartilhadas). Primeiro, usamos a função get_tx_stats para calcular o número de transações por dia, transações fraudulentas por dia e cartões comprometidos por dia. Em seguida, adicionamos as transações fraudulentas restantes por dia e a precisão top- por dia ao DataFrame, para os sete dias do período de teste.
# Compute the number of transactions per day,
#fraudulent transactions per day and fraudulent cards per day
tx_stats=get_tx_stats(transactions_df, start_date_df="2018-04-01")
# Add the remaining number of fraudulent transactions for the last 7 days (test period)
tx_stats.loc[14:20,'nb_fraudulent_transactions_per_day_remaining']=list(nb_fraudulent_transactions_per_day_remaining)
# Add precision top k for the last 7 days (test period)
tx_stats.loc[14:20,'precision_top_k_per_day']=precision_top_k_per_day_list
Note que o número restante de transações fraudulentas é o número de transações fraudulentas originalmente presentes no período de teste, menos aquelas transações que pertencem a cartões conhecidos como comprometidos no conjunto de treinamento (ver função get_train_test_set). Lembramos que essas transações devem ser removidas ao avaliar o desempenho do detector de fraude no conjunto de teste, pois os cartões a que pertencem eram conhecidos como comprometidos quando o detector de fraude foi treinado.
Notebook Cell
%%capture
# Plot the number of transactions per day, fraudulent transactions per day and fraudulent cards per day
cmap = plt.get_cmap('jet')
colors={'precision_top_k_per_day':cmap(0),
'nb_fraudulent_transactions_per_day':cmap(200),
'nb_fraudulent_transactions_per_day_remaining':cmap(250),
}
fraud_and_transactions_stats_fig, ax = plt.subplots(1, 1, figsize=(15,8))
# Training period
start_date_training = datetime.datetime.strptime("2018-07-25", "%Y-%m-%d")
delta_train = delta_delay = delta_test = 7
end_date_training = start_date_training+datetime.timedelta(days=delta_train-1)
# Test period
start_date_test = start_date_training+datetime.timedelta(days=delta_train+delta_delay)
end_date_test = start_date_training+datetime.timedelta(days=delta_train+delta_delay+delta_test-1)
get_template_tx_stats(ax, fs=20,
start_date_training=start_date_training,
title='Number of fraudulent transactions per day \n and number of detected fraudulent transactions',
delta_train=delta_train,
delta_delay=delta_delay,
delta_test=delta_test,
ylim=150
)
ax.plot(tx_stats['tx_date'], tx_stats['nb_fraudulent_transactions_per_day'], 'b', color=colors['nb_fraudulent_transactions_per_day'], label = '# fraudulent txs per day - Original')
ax.plot(tx_stats['tx_date'], tx_stats['nb_fraudulent_transactions_per_day_remaining'], 'b', color=colors['nb_fraudulent_transactions_per_day_remaining'], label = '# fraudulent txs per day - Remaining')
ax.plot(tx_stats['tx_date'], tx_stats['precision_top_k_per_day']*100, 'b', color=colors['precision_top_k_per_day'], label = '# detected fraudulent txs per day')
ax.legend(loc = 'upper left',bbox_to_anchor=(1.05, 1),fontsize=20)
O gráfico resultante nos dá:
o número de transações fraudulentas originalmente presentes no conjunto de dados de transações, para os períodos de treinamento, atraso e teste
o número de transações restantes para o período de teste (originais, menos aquelas pertencentes a cartões conhecidos como fraudulentos no período de treinamento)
o número de transações fraudulentas detectadas para o período de teste (precisão top- vezes ).
fraud_and_transactions_stats_fig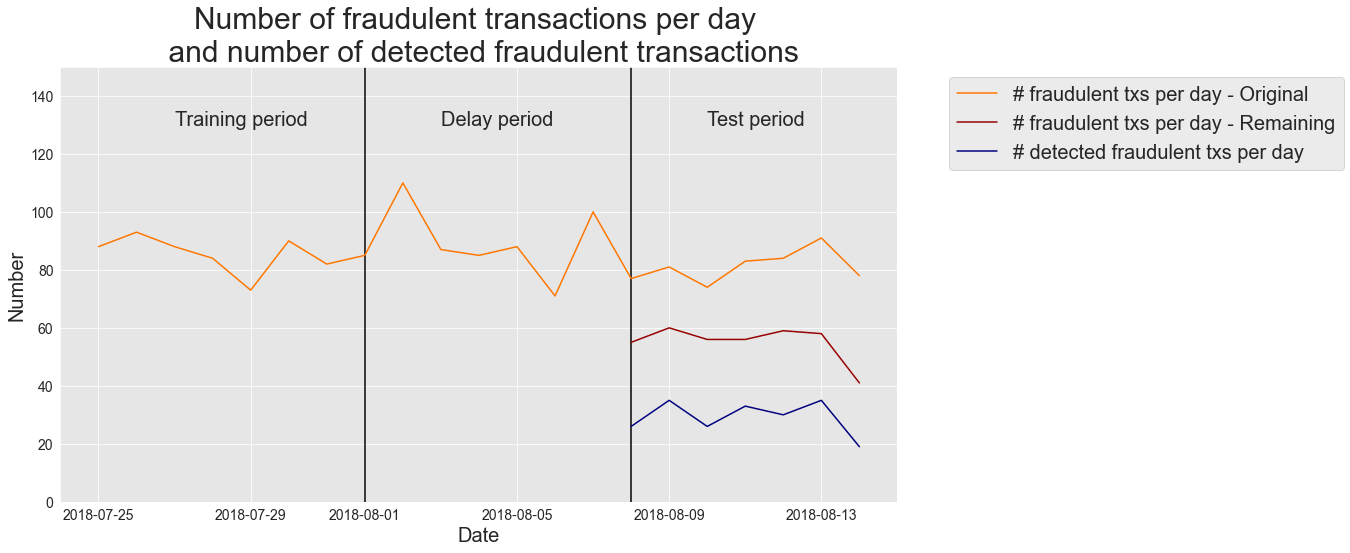
O gráfico mostra um resumo detalhado do desempenho do detector de fraude do ponto de vista operacional. No período de teste, o número de transações fraudulentas variou entre 74 e 91. Após a remoção dos cartões comprometidos conhecidos do período de treinamento, as transações fraudulentas restantes variaram entre 41 e 60. Dessas transações fraudulentas restantes, o detector de fraude detectou corretamente entre 19 e 35 transações, com um número médio de 29 transações fraudulentas detectadas por dia (precisão média top-=0,29), ou seja, cerca de 50% das transações fraudulentas reais foram detectadas.
Precisão de Cartão top-¶
Como observado na introdução, múltiplas transações fraudulentas do mesmo cartão devem contar como uma única detecção correta, pois os investigadores verificam todas as transações recentes ao contatar os titulares de cartão. A métrica resultante é a Precisão de Cartão top-, ou , e quantifica o número de cartões comprometidos corretamente detectados entre os cartões que têm os maiores riscos de fraude.
pode ser calculado com uma ligeira modificação na implementação da Precisão top- fornecida acima. Mais especificamente, em vez de simplesmente ordenar as transações em ordem decrescente de suas probabilidades de fraude, primeiro agrupamos as transações por ID do cliente. Para cada ID do cliente, então tomamos o valor máximo da probabilidade de fraude e do rótulo de fraude. Isso pode ser calculado em uma única linha de código com os operadores group_by e max do Pandas. A precisão de cartão top- é finalmente calculada ordenando os IDs de clientes em ordem decrescente das probabilidades de fraude e calculando a precisão para o conjunto de cartões com as maiores probabilidades de fraude.
Isso é implementado abaixo com a função card_precision_top_k_day. De forma similar a precision_top_k_day, a função recebe como entrada um conjunto de transações para um determinado dia e um valor top-. Ela retorna a lista de cartões comprometidos detectados e a precisão de cartão top- para aquele dia. Como exemplo, vamos calcular a precisão obtida nos 100 cartões principais, para o primeiro dia de transações no conjunto de teste (dia 129).
def card_precision_top_k_day(df_day, top_k):
# This takes the max of the predictions AND the max of label TX_FRAUD for each CUSTOMER_ID,
# and sorts by decreasing order of fraudulent prediction
df_day = df_day.groupby('CUSTOMER_ID').max().sort_values(by="predictions", ascending=False).reset_index(drop=False)
# Get the top k most suspicious cards
df_day_top_k=df_day.head(top_k)
list_detected_compromised_cards=list(df_day_top_k[df_day_top_k.TX_FRAUD==1].CUSTOMER_ID)
# Compute precision top k
card_precision_top_k = len(list_detected_compromised_cards) / top_k
return list_detected_compromised_cards, card_precision_top_k
day=129
df_day = predictions_df[predictions_df['TX_TIME_DAYS']==day]
df_day = df_day[['predictions', 'CUSTOMER_ID', 'TX_FRAUD']]
_,card_precision_top_k= card_precision_top_k_day(df_day=df_day, top_k=100)
card_precision_top_k
0.24Obtemos uma precisão de cartão de 0,24, ou seja, 24 dos primeiros cem cartões mais suspeitos eram de fato cartões comprometidos. O número de cartões comprometidos no dia 129 foi de 50.
df_day.groupby('CUSTOMER_ID').max().TX_FRAUD.sum()50Cerca de 50% dos cartões comprometidos foram, portanto, detectados. O cálculo da Precisão de Cartão top- ao longo de vários dias é feito da mesma forma que para a Precisão top-, calculando a Precisão de Cartão top- para cada dia do período de teste e tomando a média.
def card_precision_top_k(predictions_df, top_k):
# Sort days by increasing order
list_days=list(predictions_df['TX_TIME_DAYS'].unique())
list_days.sort()
card_precision_top_k_per_day_list = []
nb_compromised_cards_per_day = []
# For each day, compute precision top k
for day in list_days:
df_day = predictions_df[predictions_df['TX_TIME_DAYS']==day]
df_day = df_day[['predictions', 'CUSTOMER_ID', 'TX_FRAUD']]
nb_compromised_cards_per_day.append(len(df_day[df_day.TX_FRAUD==1].CUSTOMER_ID.unique()))
_, card_precision_top_k = card_precision_top_k_day(df_day,top_k)
card_precision_top_k_per_day_list.append(card_precision_top_k)
# Compute the mean
mean_card_precision_top_k = np.array(card_precision_top_k_per_day_list).mean()
# Returns precision top k per day as a list, and resulting mean
return nb_compromised_cards_per_day,card_precision_top_k_per_day_list,mean_card_precision_top_k
nb_compromised_cards_per_day_remaining\
,card_precision_top_k_per_day_list\
,mean_card_precision_top_k=card_precision_top_k(predictions_df=predictions_df, top_k=100)
print("Number of remaining compromised cards: "+str(nb_compromised_cards_per_day_remaining))
print("Precision top-k: "+str(card_precision_top_k_per_day_list))
print("Average Precision top-k: "+str(mean_card_precision_top_k))
Number of remaining compromised cards: [50, 54, 51, 54, 55, 54, 38]
Precision top-k: [0.24, 0.35, 0.26, 0.32, 0.3, 0.34, 0.19]
Average Precision top-k: 0.2857142857142857
Vamos plotar esses resultados para melhor visualização.
# Compute the number of transactions per day,
# fraudulent transactions per day and fraudulent cards per day
tx_stats=get_tx_stats(transactions_df, start_date_df="2018-04-01")
# Add the remaining number of compromised cards for the last 7 days (test period)
tx_stats.loc[14:20,'nb_compromised_cards_per_day_remaining']=list(nb_compromised_cards_per_day_remaining)
# Add the card precision top k for the last 7 days (test period)
tx_stats.loc[14:20,'card_precision_top_k_per_day']=card_precision_top_k_per_day_list
Notebook Cell
%%capture
# Plot the number of transactions per day, fraudulent transactions per day and fraudulent cards per day
cmap = plt.get_cmap('jet')
colors={'card_precision_top_k_per_day':cmap(0),
'nb_compromised_cards_per_day':cmap(200),
'nb_compromised_cards_per_day_remaining':cmap(250),
}
fraud_and_transactions_stats_fig, ax = plt.subplots(1, 1, figsize=(15,8))
# Training period
start_date_training = datetime.datetime.strptime("2018-07-25", "%Y-%m-%d")
delta_train = delta_delay = delta_test = 7
end_date_training = start_date_training+datetime.timedelta(days=delta_train-1)
# Test period
start_date_test = start_date_training+datetime.timedelta(days=delta_train+delta_delay)
end_date_test = start_date_training+datetime.timedelta(days=delta_train+delta_delay+delta_test-1)
get_template_tx_stats(ax, fs=20,
start_date_training=start_date_training,
title='Number of fraudulent transactions per day \n and number of detected fraudulent transactions',
delta_train=delta_train,
delta_delay=delta_delay,
delta_test=delta_test,
ylim=150
)
ax.plot(tx_stats['tx_date'], tx_stats['nb_compromised_cards_per_day'], 'b', color=colors['nb_compromised_cards_per_day'], label = '# fraudulent txs per day - Original')
ax.plot(tx_stats['tx_date'], tx_stats['nb_compromised_cards_per_day_remaining'], 'b', color=colors['nb_compromised_cards_per_day_remaining'], label = '# compromised cards per day - Remaining')
ax.plot(tx_stats['tx_date'], tx_stats['card_precision_top_k_per_day']*100, 'b', color=colors['card_precision_top_k_per_day'], label = '# detected compromised cards per day')
ax.legend(loc = 'upper left', bbox_to_anchor=(1.05, 1), fontsize=20)
fraud_and_transactions_stats_fig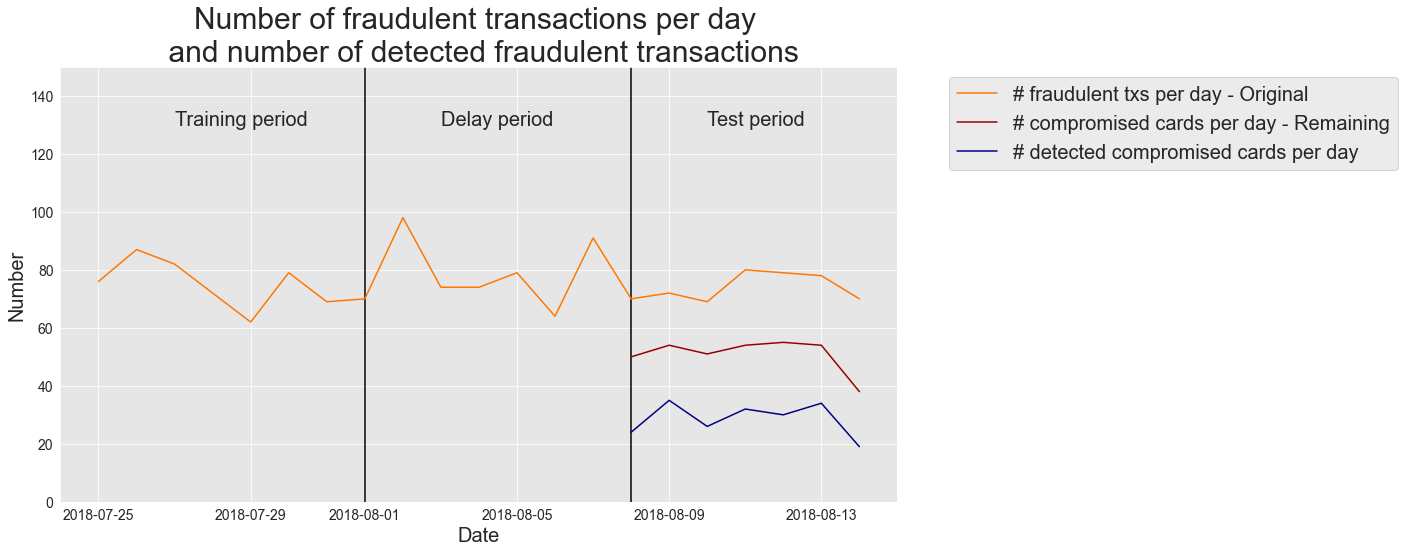
Os resultados são qualitativamente similares aos obtidos com a Precisão top-. No período de teste, o número de cartões comprometidos variou entre 69 e 80. Após a remoção das transações de cartões comprometidos conhecidos, os cartões comprometidos restantes variaram entre 38 e 55. Desses cartões comprometidos restantes, o detector de fraude detectou corretamente entre 19 e 35 cartões, com um número médio de 29 cartões comprometidos detectados por dia (Precisão de Cartão top- média=0,33), ou seja, cerca de 60% dos cartões comprometidos reais foram detectados.
Por fim, deve-se notar que, uma vez que um cartão comprometido é detectado, ele é bloqueado e deve ser removido do pool de transações. Vamos modificar o card_precision_top_k para remover os cartões comprometidos que foram detectados.
def card_precision_top_k(predictions_df, top_k, remove_detected_compromised_cards=True):
# Sort days by increasing order
list_days=list(predictions_df['TX_TIME_DAYS'].unique())
list_days.sort()
# At first, the list of detected compromised cards is empty
list_detected_compromised_cards = []
card_precision_top_k_per_day_list = []
nb_compromised_cards_per_day = []
# For each day, compute precision top k
for day in list_days:
df_day = predictions_df[predictions_df['TX_TIME_DAYS']==day]
df_day = df_day[['predictions', 'CUSTOMER_ID', 'TX_FRAUD']]
# Let us remove detected compromised cards from the set of daily transactions
df_day = df_day[df_day.CUSTOMER_ID.isin(list_detected_compromised_cards)==False]
nb_compromised_cards_per_day.append(len(df_day[df_day.TX_FRAUD==1].CUSTOMER_ID.unique()))
detected_compromised_cards, card_precision_top_k = card_precision_top_k_day(df_day,top_k)
card_precision_top_k_per_day_list.append(card_precision_top_k)
# Let us update the list of detected compromised cards
if remove_detected_compromised_cards:
list_detected_compromised_cards.extend(detected_compromised_cards)
# Compute the mean
mean_card_precision_top_k = np.array(card_precision_top_k_per_day_list).mean()
# Returns precision top k per day as a list, and resulting mean
return nb_compromised_cards_per_day,card_precision_top_k_per_day_list,mean_card_precision_top_k
nb_compromised_cards_per_day_remaining\
,card_precision_top_k_per_day_list\
,mean_card_precision_top_k=card_precision_top_k(predictions_df=predictions_df, top_k=100)
print("Number of remaining compromised cards: "+str(nb_compromised_cards_per_day_remaining))
print("Precision top-k: "+str(card_precision_top_k_per_day_list))
print("Average Precision top-k: "+str(mean_card_precision_top_k))
Number of remaining compromised cards: [50, 50, 49, 47, 46, 44, 31]
Precision top-k: [0.24, 0.32, 0.27, 0.25, 0.23, 0.26, 0.12]
Average Precision top-k: 0.2414285714285714
Observamos que o número de cartões comprometidos restantes é menor, pois os cartões comprometidos detectados são removidos do pool de transações.
# Compute the number of transactions per day,
#fraudulent transactions per day and fraudulent cards per day
tx_stats=get_tx_stats(transactions_df, start_date_df="2018-04-01")
# Add the remaining number of compromised cards for the last 7 days (test period)
tx_stats.loc[14:20,'nb_compromised_cards_per_day_remaining']=list(nb_compromised_cards_per_day_remaining)
# Add the card precision top k for the last 7 days (test period)
tx_stats.loc[14:20,'card_precision_top_k_per_day']=card_precision_top_k_per_day_list
Notebook Cell
%%capture
# Plot the number of transactions per day, fraudulent transactions per day and fraudulent cards per day
cmap = plt.get_cmap('jet')
colors={'card_precision_top_k_per_day':cmap(0),
'nb_compromised_cards_per_day':cmap(200),
'nb_compromised_cards_per_day_remaining':cmap(250),
}
fraud_and_transactions_stats_fig, ax = plt.subplots(1, 1, figsize=(15,8))
# Training period
start_date_training = datetime.datetime.strptime("2018-07-25", "%Y-%m-%d")
delta_train = delta_delay = delta_test = 7
end_date_training = start_date_training+datetime.timedelta(days=delta_train-1)
# Test period
start_date_test = start_date_training+datetime.timedelta(days=delta_train+delta_delay)
end_date_test = start_date_training+datetime.timedelta(days=delta_train+delta_delay+delta_test-1)
get_template_tx_stats(ax, fs=20,
start_date_training=start_date_training,
title='Number of fraudulent transactions per day \n and number of detected fraudulent transactions',
delta_train=delta_train,
delta_delay=delta_delay,
delta_test=delta_test,
ylim=150
)
ax.plot(tx_stats['tx_date'], tx_stats['nb_compromised_cards_per_day'], 'b', color=colors['nb_compromised_cards_per_day'], label = '# compromised cards per day - Original')
ax.plot(tx_stats['tx_date'], tx_stats['nb_compromised_cards_per_day_remaining'], 'b', color=colors['nb_compromised_cards_per_day_remaining'], label = '# compromised cards per day - Remaining')
ax.plot(tx_stats['tx_date'], tx_stats['card_precision_top_k_per_day']*100, 'b', color=colors['card_precision_top_k_per_day'], label = '# detected compromised compromised cards per day')
ax.legend(loc = 'upper left',bbox_to_anchor=(1.05, 1),fontsize=20)fraud_and_transactions_stats_fig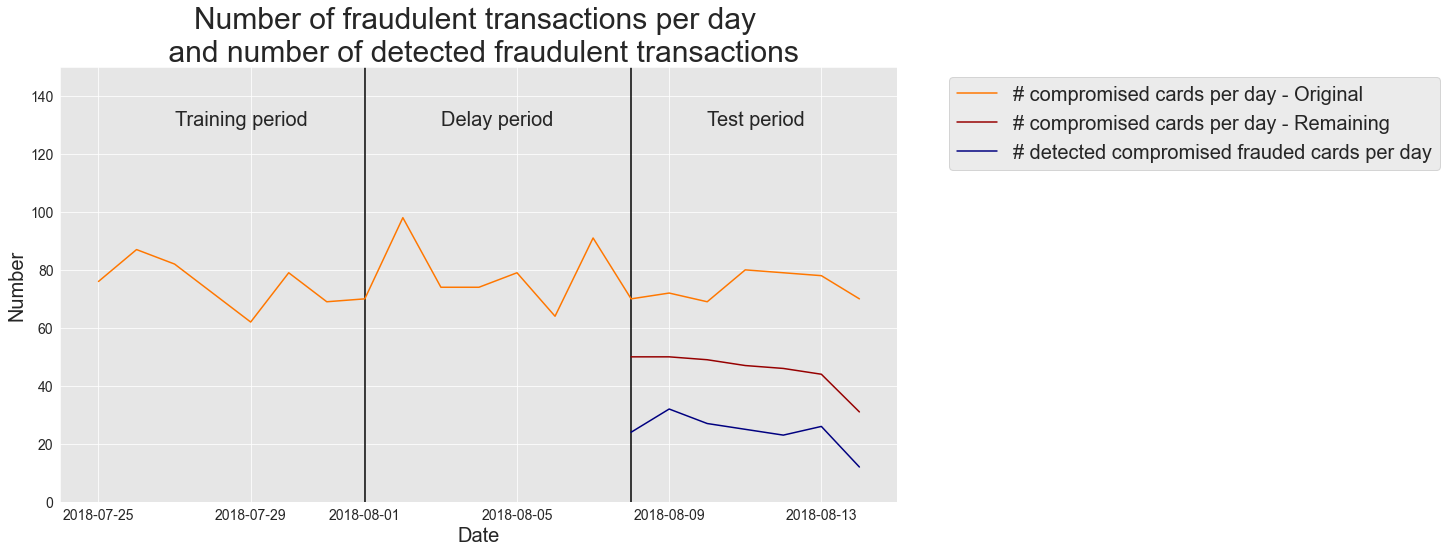
Esta última implementação de card_precision_top_k é a incluída no notebook de funções compartilhadas e usada nos próximos capítulos.
- Dal Pozzolo, A., Boracchi, G., Caelen, O., Alippi, C., & Bontempi, G. (2017). Credit card fraud detection: a realistic modeling and a novel learning strategy. IEEE Transactions on Neural Networks and Learning Systems, 29(8), 3784–3797.
- Dal Pozzolo, A. (2015). Adaptive machine learning for credit card fraud detection. Université libre de Bruxelles.
- Fan, G., & Zhu, M. (2011). Detection of rare items with target. Statistics and Its Interface, 4(1), 11–17.