Todas as métricas apresentadas na seção anterior só podem ser calculadas uma vez que uma matriz de confusão esteja disponível, o que requer a definição de um limiar de decisão sobre as probabilidades retornadas pelo classificador. Para avaliar o desempenho de um classificador em uma variedade de limiares diferentes, duas técnicas de avaliação bem conhecidas são a Curva ROC (Receiver Operating Characteristic) e a Curva Precisão-Recall (PR). Ambas as técnicas permitem fornecer uma pontuação de desempenho geral, na forma da medida de área sob a curva (AUC).
Esta seção apresenta essas duas técnicas e discute seus prós e contras. Em particular, mostraremos que a Curva PR e a Precisão Média (como métrica que calcula a área sob a Curva PR) são mais adequadas para problemas de detecção de fraude do que a Curva ROC e o AUC ROC, respectivamente.
Notebook Cell
# Initialization: Load shared functions and simulated data
# Load shared functions
!curl -O https://raw.githubusercontent.com/Fraud-Detection-Handbook/fraud-detection-handbook/main/Chapter_References/shared_functions.py
%run shared_functions.py
# Get simulated data from Github repository
if not os.path.exists("simulated-data-transformed"):
!git clone https://github.com/Fraud-Detection-Handbook/simulated-data-transformed
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 37136 100 37136 0 0 148k 0 --:--:-- --:--:-- --:--:-- 148k
Curva ROC (Receiver Operating Characteristic)¶
A Curva ROC Fawcett (2004)Fawcett (2006) é obtida plotando o Recall (ou Taxa de Verdadeiros Positivos - TPR) contra a Taxa de Falsos Positivos (FPR) para todos os diferentes limiares de classificação . É o padrão de facto para estimar o desempenho de sistemas de detecção de fraude na literatura Dal Pozzolo (2015).
Um classificador K é considerado mais performático do que um classificador W no espaço ROC somente se a curva de K dominar sempre a curva de W.
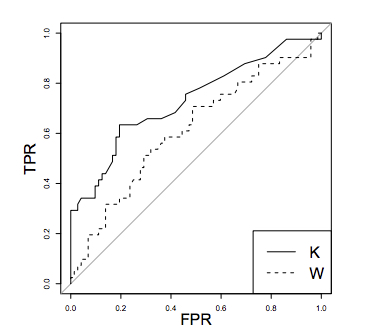
A linha cinza representa o desempenho de um modelo aleatório.
O melhor classificador corresponde ao ponto (0,1) no espaço ROC (sem falsos negativos e sem falsos positivos), enquanto um classificador que prevê aleatoriamente teria desempenho ao longo da diagonal que conecta o canto inferior esquerdo ao canto superior direito. Quando não há um vencedor claro (por exemplo, o classificador K domina W apenas em uma parte do espaço ROC), a comparação é geralmente feita calculando a Área Sob a Curva ROC (AUC ROC). O AUC ROC é geralmente calculado com a regra trapezoidal (interpolação linear) Fawcett (2006), que fornece uma probabilidade esperada para a TPR e FPR em caso de empates nos valores de previsão.
A Curva ROC é obtida calculando a TPR e a FPR para todos os valores possíveis de probabilidade de fraude retornados por um classificador.
Vamos ilustrar sua construção reutilizando o exemplo simples apresentado na seção anterior. O exemplo contém 10 transações, das quais 2 são fraudulentas e 8 legítimas. Os rótulos são fornecidos por uma lista true_labels. Assumimos que um vetor de probabilidades de fraude foi retornado por um detector de fraude. O vetor de probabilidades de fraude é fornecido por uma lista fraud_probabilities.
# 2 fraudulent and 8 genuine transactions
true_labels = [1,1,0,0,0,0,0,0,0,0]
# Probability of fraud for each transaction
fraud_probabilities = [0.9,0.35,0.45,0.4,0.2,0.2,0.2,0.1,0.1,0]Os primeiros passos no cálculo da Curva ROC consistem em obter a lista de todos os limiares únicos possíveis para os quais a TPR e a FPR serão calculadas, e ordená-los em ordem decrescente. Um limiar maior que 1 (definido como 1,1) também é adicionado para ter o caso em que todas as transações são preditas como legítimas.
unique_thresholds = [1.1]+list(set(fraud_probabilities))
unique_thresholds.sort(reverse=True)
unique_thresholds[1.1, 0.9, 0.45, 0.4, 0.35, 0.2, 0.1, 0]Isso nos dá uma lista de oito limiares únicos a serem considerados neste exemplo. A esses limiares estão associados todos os possíveis pares (TPR, FPR) que o classificador pode retornar.
Reutilizando a função threshold_based_metrics definida na seção anterior, vamos calcular a TPR e a FPR para cada um desses limiares.
performance_metrics=threshold_based_metrics(fraud_probabilities, true_labels, unique_thresholds)
performance_metrics[['Threshold','TPR','FPR']]Como esperado, quanto menor o limiar, maior a TPR (mais fraudes são detectadas), mas maior a FPR (mais transações legítimas são classificadas como fraudulentas). O primeiro ponto da curva consiste em prever todas as transações como legítimas (limiar 1,1). A TPR resultante é zero (nenhuma fraude detectada), e a FPR é 0 (nenhum falso positivo). O último ponto da curva consiste em prever todas as transações como fraudulentas (limiar 0). A TPR resultante é 1 (todas as fraudes detectadas) e a FPR é 1 (todas as transações legítimas classificadas incorretamente como fraudes).
Como a Curva ROC é uma métrica padrão em classificação, a biblioteca Python sklearn.metrics fornece uma função roc_curve para calcular os limiares, bem como a FPR e a TPR correspondentes.
FPR_list, TPR_list, threshold = sklearn.metrics.roc_curve(true_labels, fraud_probabilities, drop_intermediate=False)
FPR_list, TPR_list, threshold(array([0. , 0. , 0.125, 0.25 , 0.25 , 0.625, 0.875, 1. ]),
array([0. , 0.5, 0.5, 0.5, 1. , 1. , 1. , 1. ]),
array([1.9 , 0.9 , 0.45, 0.4 , 0.35, 0.2 , 0.1 , 0. ]))Vamos agora plotar a Curva ROC resultante. Notamos que o primeiro limiar (1,9) difere do que escolhemos anteriormente (1,1). Isso ocorre porque a função sklearn.metrics.roc_curve define o primeiro limiar como 1 mais o segundo limiar (0,9), resultando em 1,9 neste caso.
Notebook Cell
%%capture
def get_template_roc_curve(ax, title,fs,random=True):
ax.set_title(title, fontsize=fs)
ax.set_xlim([-0.01, 1.01])
ax.set_ylim([-0.01, 1.01])
ax.set_xlabel('False Positive Rate', fontsize=fs)
ax.set_ylabel('True Positive Rate', fontsize=fs)
if random:
ax.plot([0, 1], [0, 1],'r--',label="AUC ROC Random = 0.5")
ROC_AUC = metrics.auc(FPR_list, TPR_list)
roc_curve, ax = plt.subplots(figsize=(5,5))
get_template_roc_curve(ax, "Receiver Operating Characteristic (ROC) Curve",fs=15)
ax.plot(FPR_list, TPR_list, 'b', color='blue', label = 'AUC ROC Classifier = {0:0.3f}'.format(ROC_AUC))
ax.legend(loc = 'lower right')roc_curve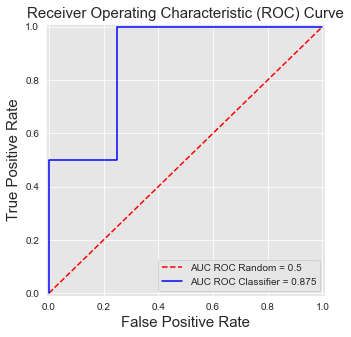
As Curvas ROC têm três propriedades importantes Fernández et al. (2018). Primeiro, são funções monótonas: a TPR só pode aumentar à medida que a FPR aumenta. Segundo, a área sob a curva tem uma interpretação probabilística: o AUC ROC pode ser interpretado como a probabilidade de que as pontuações dadas por um classificador ranquearão uma instância positiva aleatoriamente escolhida acima de uma instância negativa aleatoriamente escolhida. Terceiro, o AUC ROC de um classificador aleatório é .
A última propriedade pode ser facilmente verificada definindo todas as previsões como 0,5. Isso nos dá uma lista de apenas dois limiares. O primeiro é 1,5, que classifica todas as previsões como legítimas. O segundo é 0,5, que classifica todas as previsões como fraudulentas.
# 2 fraudulent and 8 genuine transactions
true_labels = [1,1,0,0,0,0,0,0,0,0]
# Probability of fraud for each transaction
fraud_probabilities = [0.5]*10
FPR_list, TPR_list, threshold = metrics.roc_curve(true_labels, fraud_probabilities, drop_intermediate=False)
FPR_list, TPR_list, threshold(array([0., 1.]), array([0., 1.]), array([1.5, 0.5]))Notebook Cell
%%capture
ROC_AUC = metrics.auc(FPR_list, TPR_list)
roc_curve, ax = plt.subplots(figsize=(5,5))
get_template_roc_curve(ax, "Receiver Operating Characteristic (ROC) Curve\n Random classifier",fs=15,random=False)
ax.plot(FPR_list, TPR_list, 'b', color='blue', label = 'AUC ROC Classifier = {0:0.3f}'.format(ROC_AUC))
ax.legend(loc = 'lower right')roc_curve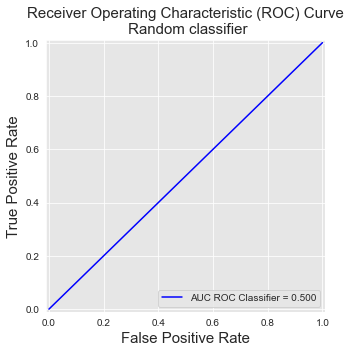
Isso resulta em uma linha indo de [0,0] a [1,1]. O AUC ROC resultante é a área sob essa linha, que é 0,5.
Vamos agora reutilizar o cenário experimental do sistema de detecção de fraude de linha de base apresentado no Capítulo 3. Uma semana de dados é usada para treinamento e uma semana para teste. Cinco modelos de predição são considerados: regressão logística, uma árvore de decisão com profundidade dois e uma árvore de decisão de profundidade ilimitada, uma floresta aleatória com 25 árvores e um modelo de boosting com parâmetros padrão. As Curvas ROC e seus AUC são reportados abaixo para os cinco modelos.
Notebook Cell
# Load data from the 2018-07-25 to the 2018-08-14
DIR_INPUT='./simulated-data-transformed/data'
BEGIN_DATE = "2018-07-25"
END_DATE = "2018-08-14"
print("Load files")
%time transactions_df=read_from_files(DIR_INPUT, BEGIN_DATE, END_DATE)
print("{0} transactions loaded, containing {1} fraudulent transactions".format(len(transactions_df),transactions_df.TX_FRAUD.sum()))
start_date_training = datetime.datetime.strptime("2018-07-25", "%Y-%m-%d")
delta_train=delta_delay=delta_test=7
(train_df,test_df)=get_train_test_set(transactions_df,start_date_training,
delta_train=delta_train,delta_delay=delta_delay,delta_test=delta_test)
output_feature="TX_FRAUD"
input_features=['TX_AMOUNT','TX_DURING_WEEKEND', 'TX_DURING_NIGHT', 'CUSTOMER_ID_NB_TX_1DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_1DAY_WINDOW', 'CUSTOMER_ID_NB_TX_7DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_7DAY_WINDOW', 'CUSTOMER_ID_NB_TX_30DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_30DAY_WINDOW', 'TERMINAL_ID_NB_TX_1DAY_WINDOW',
'TERMINAL_ID_RISK_1DAY_WINDOW', 'TERMINAL_ID_NB_TX_7DAY_WINDOW',
'TERMINAL_ID_RISK_7DAY_WINDOW', 'TERMINAL_ID_NB_TX_30DAY_WINDOW',
'TERMINAL_ID_RISK_30DAY_WINDOW']
classifiers_dictionary={'Logistic regression':sklearn.linear_model.LogisticRegression(random_state=0),
'Decision tree with depth of two':sklearn.tree.DecisionTreeClassifier(max_depth=2,random_state=0),
'Decision tree - unlimited depth':sklearn.tree.DecisionTreeClassifier(random_state=0),
'Random forest':sklearn.ensemble.RandomForestClassifier(random_state=0,n_jobs=-1),
'XGBoost':xgboost.XGBClassifier(random_state=0,n_jobs=-1),
}
fitted_models_and_predictions_dictionary={}
for classifier_name in classifiers_dictionary:
start_time=time.time()
model_and_predictions = fit_model_and_get_predictions(classifiers_dictionary[classifier_name], train_df, test_df,
input_features=input_features,
output_feature=output_feature)
print("Time to fit the "+classifier_name+" model: "+str(round(time.time()-start_time,2)))
fitted_models_and_predictions_dictionary[classifier_name]=model_and_predictions
Load files
CPU times: user 196 ms, sys: 155 ms, total: 351 ms
Wall time: 375 ms
201295 transactions loaded, containing 1792 fraudulent transactions
Time to fit the Logistic regression model: 0.73
Time to fit the Decision tree with depth of two model: 0.45
Time to fit the Decision tree - unlimited depth model: 1.3
Time to fit the Random forest model: 9.15
[10:53:15] WARNING: /private/var/folders/wz/86tkhhmd5gxgh4f24bdl9l2m0000gn/T/pip-install-o8iul8v_/xgboost/build/temp.macosx-10.9-x86_64-3.8/xgboost/src/learner.cc:1061: Starting in XGBoost 1.3.0, the default evaluation metric used with the objective 'binary:logistic' was changed from 'error' to 'logloss'. Explicitly set eval_metric if you'd like to restore the old behavior.
Time to fit the XGBoost model: 7.49
Notebook Cell
%%capture
roc_curve, ax = plt.subplots(1, 1, figsize=(5,5))
cmap = plt.get_cmap('jet')
colors={'Logistic regression':cmap(0), 'Decision tree with depth of two':cmap(200),
'Decision tree - unlimited depth':cmap(250),
'Random forest':cmap(70), 'XGBoost':cmap(40)}
get_template_roc_curve(ax,title='Receiver Operating Characteristic Curve\nTest data',fs=15)
for classifier_name in classifiers_dictionary:
model_and_predictions=fitted_models_and_predictions_dictionary[classifier_name]
FPR_list, TPR_list, threshold = metrics.roc_curve(test_df[output_feature], model_and_predictions['predictions_test'])
ROC_AUC = metrics.auc(FPR_list, TPR_list)
ax.plot(FPR_list, TPR_list, 'b', color=colors[classifier_name], label = 'AUC ROC {0}= {1:0.3f}'.format(classifier_name,ROC_AUC))
ax.legend(loc = 'upper left',bbox_to_anchor=(1.05, 1))
roc_curve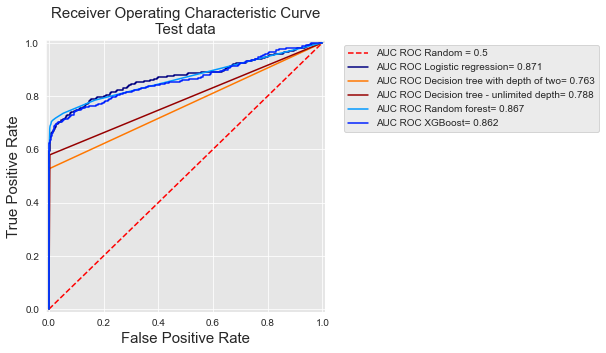
As curvas mostram que as árvores de decisão têm os menores desempenhos, enquanto a floresta aleatória, a regressão logística e o boosting têm desempenhos similares. Podemos notar que as curvas para as duas árvores de decisão têm apenas alguns pontos. Para a árvore com profundidade dois, o motivo é que ela tem apenas quatro folhas, portanto prevê apenas quatro valores diferentes e, consequentemente, tem apenas quatro limiares possíveis. Para a árvore com profundidade ilimitada, o motivo é que todas as suas folhas são puras no conjunto de treinamento (preveem uma probabilidade de 1 ou de 0). Portanto, este modelo tem apenas dois limiares possíveis.
As Curvas ROC são relevantes para ter uma noção do desempenho de um classificador em toda a faixa de valores possíveis de FPR. Seu interesse para detecção de fraude é, no entanto, limitado, pois um objetivo importante da detecção de fraude é manter a FPR muito baixa.
Para ter uma noção de quão baixa a FPR deve ser mantida, vamos lembrar que os falsos positivos são transações legítimas que são preditas como fraudulentas. Em um sistema de fraude operacional, essas transações precisarão ser tratadas manualmente pelos investigadores. Devido ao número limitado de investigadores, há apenas uma quantidade limitada de transações que podem ser verificadas.
Vamos considerar de forma mais concreta como essa restrição se traduz em termos de FPR.
Neste exemplo, o conjunto de dados contém 58264 transações (ao longo de 7 dias), das quais 57879 são legítimas e 385 fraudulentas.
test_df[test_df.TX_FRAUD==0].shape(57879, 23)test_df[test_df.TX_FRAUD==1].shape(385, 23)Assumindo que 100 transações possam ser verificadas a cada dia, um total de 700 transações poderia ser verificado após 7 dias, ou seja, cerca de 1% das transações. Portanto, qualquer FPR acima de 0,01 gerará mais alertas do que os investigadores conseguem processar.
Os sistemas de detecção de fraude do mundo real geralmente lidam com centenas de milhares a milhões de transações diariamente. A proporção de transações que podem ser verificadas manualmente está, na verdade, mais próxima de 0,1% do que de 1%. Ou seja, qualquer FPR acima de 0,001 já é muito alto.
Como resultado, devido à natureza desbalanceada do problema, 99,9% do que é representado na Curva ROC tem pouca relevância do ponto de vista de um sistema de detecção de fraude operacional, onde as transações fraudulentas devem ser verificadas por uma equipe limitada de investigadores.
Remetemos o leitor a Saito & Rehmsmeier (2015) para uma discussão aprofundada sobre a inadequação da Curva ROC para problemas desbalanceados, e as motivações para usar a Curva Precisão-Recall em vez dela.
Curva Precisão-Recall¶
A Curva Precisão-Recall (Curva PR) é obtida plotando a precisão contra o recall (ou Taxa de Verdadeiros Positivos - TPR) para todos os diferentes limiares de classificação . A principal vantagem da Curva PR é evidenciar classificadores que podem ter tanto alto recall quanto alta precisão (o que indiretamente se traduz em alta TPR e baixa FPR).
Vamos reutilizar o mesmo exemplo de acima e calcular a precisão e o recall para os oito limiares únicos.
# 2 fraudulent and 8 genuine transactions
true_labels = [1,1,0,0,0,0,0,0,0,0]
# Probability of fraud for each transaction
fraud_probabilities = [0.9,0.35,0.45,0.4,0.2,0.2,0.2,0.1,0.1,0]
unique_thresholds = [1.1]+list(set(fraud_probabilities))
unique_thresholds.sort(reverse=True)
performance_metrics=threshold_based_metrics(fraud_probabilities, true_labels, unique_thresholds)
performance_metrics[['Threshold','Precision','TPR']]Vamos agora plotar a Curva PR e calcular sua AUC. Usaremos a Precisão Média (AP), que resume tal gráfico como a média ponderada das precisões obtidas em cada limiar, com o aumento no recall em relação ao limiar anterior usado como peso Boyd et al. (2013)Fan & Zhu (2011).
onde e são a precisão e o recall no -ésimo limiar.
Uma implementação da precisão média é fornecida abaixo.
def compute_AP(precision, recall):
AP = 0
n_thresholds = len(precision)
for i in range(1, n_thresholds):
if recall[i]-recall[i-1]>=0:
AP = AP+(recall[i]-recall[i-1])*precision[i]
return APO gráfico é obtido usando a função step do matplotlib.
Notebook Cell
%%capture
def get_template_pr_curve(ax, title,fs, baseline=0.5):
ax.set_title(title, fontsize=fs)
ax.set_xlim([-0.01, 1.01])
ax.set_ylim([-0.01, 1.01])
ax.set_xlabel('Recall (True Positive Rate)', fontsize=fs)
ax.set_ylabel('Precision', fontsize=fs)
ax.plot([0, 1], [baseline, baseline],'r--',label='AP Random = {0:0.3f}'.format(baseline))
precision = performance_metrics.Precision.values
recall = performance_metrics.TPR.values
pr_curve, ax = plt.subplots(figsize=(5,5))
get_template_pr_curve(ax, "Precision Recall (PR) Curve",fs=15,baseline=sum(true_labels)/len(true_labels))
AP2 = metrics.average_precision_score(true_labels, fraud_probabilities)
AP = compute_AP(precision, recall)
ax.step(recall, precision, 'b', color='blue', label = 'AP Classifier = {0:0.3f}'.format(AP))
ax.legend(loc = 'lower right')
pr_curve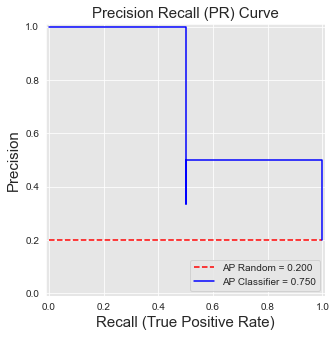
As Curvas PR se comportam de maneira diferente das Curvas ROC. Detalhamos essas diferenças a seguir.
Primeiro, elas não são monótonas: a precisão pode diminuir ou aumentar à medida que o recall aumenta. Isso é ilustrado acima, onde para um recall de , a precisão primeiro cai para (limiar ), antes de subir para (limiar ).
Segundo, sua AUC não carrega uma interpretação estatística como o AUC ROC. No entanto, pode-se mostrar que existe uma correspondência biunívoca entre as Curvas PR e ROC, e que uma curva que domina no espaço PR necessariamente domina no espaço ROC Davis & Goadrich (2006).
Terceiro, o desempenho de um classificador aleatório depende do desequilíbrio de classes. É no caso balanceado e no caso geral, onde é o número de exemplos positivos e o número de exemplos negativos. Em particular, um classificador que classifica todos os exemplos como positivos (recall de 1) tem uma precisão de . No exemplo acima, isso resulta em uma precisão de , destacada com a linha vermelha pontilhada. Essa propriedade torna a AP mais interessante do que o AUC ROC em um problema de detecção de fraude, pois reflete melhor o desafio relacionado ao problema de desequilíbrio de classes (a AP de um classificador aleatório diminui à medida que a proporção de desequilíbrio de classes aumenta).
Vamos finalmente reutilizar o cenário experimental da seção anterior e plotar as Curvas PR e as AP correspondentes para cada um dos cinco modelos de predição.
Notebook Cell
%%capture
pr_curve, ax = plt.subplots(1, 1, figsize=(6,6))
cmap = plt.get_cmap('jet')
colors={'Logistic regression':cmap(0), 'Decision tree with depth of two':cmap(200),
'Decision tree - unlimited depth':cmap(250),
'Random forest':cmap(70), 'XGBoost':cmap(40)}
get_template_pr_curve(ax, "Precision Recall (PR) Curve\nTest data",fs=15,baseline=sum(test_df[output_feature])/len(test_df[output_feature]))
for classifier_name in classifiers_dictionary:
model_and_predictions=fitted_models_and_predictions_dictionary[classifier_name]
precision, recall, threshold = metrics.precision_recall_curve(test_df[output_feature], model_and_predictions['predictions_test'])
precision=precision[::-1]
recall=recall[::-1]
AP = metrics.average_precision_score(test_df[output_feature], model_and_predictions['predictions_test'])
ax.step(recall, precision, 'b', color=colors[classifier_name], label = 'AP {0}= {1:0.3f}'.format(classifier_name,AP))
ax.legend(loc = 'upper left',bbox_to_anchor=(1.05, 1))
plt.subplots_adjust(wspace=0.5, hspace=0.8)pr_curve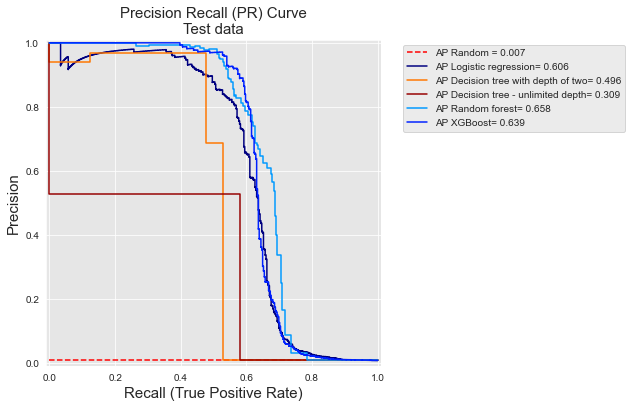
E vamos comparar essas Curvas PR com as Curvas ROC.
roc_curveÀ primeira vista, as Curvas PR e ROC fornecem uma imagem muito diferente dos desempenhos relativos dos diferentes classificadores. Para relacionar melhor os dois tipos de curva, é útil “transpor” mentalmente a Curva PR de forma que o eixo x represente a precisão e o eixo y represente a Taxa de Verdadeiros Positivos. Uma vez transposta, ambas as curvas representam a TPR em seu eixo y, e pode-se notar que a Curva PR é na verdade uma versão ampliada das Curvas ROC para valores muito baixos da Taxa de Falsos Positivos.
Como observado acima ao final da seção sobre Curvas ROC, os valores de TPR para valores baixos de FPR são, na verdade, o que importa em um problema de detecção de fraude: o número de cartões que podem ser verificados manualmente pelos investigadores de fraude é, na prática, muito limitado. Isso também fornece uma ordenação diferente dos desempenhos para os classificadores. Por exemplo, com Curvas ROC, as árvores de decisão com profundidade ilimitada têm uma AUC melhor do que uma árvore de decisão de profundidade dois (0,788 versus 0,763, respectivamente). Os desempenhos se invertem quando calculados em termos de Precisão Média (0,309 versus 0,496).
Embora as Curvas PR sejam úteis para destacar os desempenhos dos sistemas de detecção de fraude para valores baixos de FPR, elas continuam difíceis de interpretar do ponto de vista operacional. A próxima seção aborda essa questão, discutindo métricas de Precisão top-.
- Fawcett, T. (2004). ROC graphs: Notes and practical considerations for researchers. Machine Learning, 31(1), 1–38.
- Fawcett, T. (2006). An introduction to ROC analysis. Pattern Recognition Letters, 27(8), 861–874.
- Dal Pozzolo, A. (2015). Adaptive machine learning for credit card fraud detection. Université libre de Bruxelles.
- Fernández, A., Garcı́a, S., Galar, M., Prati, R. C., Krawczyk, B., & Herrera, F. (2018). Learning from imbalanced data sets. Springer.
- Saito, T., & Rehmsmeier, M. (2015). The precision-recall plot is more informative than the ROC plot when evaluating binary classifiers on imbalanced datasets. PloS One, 10(3), e0118432.
- Boyd, K., Eng, K. H., & Page, C. D. (2013). Area under the precision-recall curve: point estimates and confidence intervals. Joint European Conference on Machine Learning and Knowledge Discovery in Databases, 451–466.
- Fan, G., & Zhu, M. (2011). Detection of rare items with target. Statistics and Its Interface, 4(1), 11–17.
- Davis, J., & Goadrich, M. (2006). The relationship between Precision-Recall and ROC curves. Proceedings of the 23rd International Conference on Machine Learning, 233–240.
- Flach, P., & Kull, M. (2015). Precision-recall-gain curves: PR analysis done right. Advances in Neural Information Processing Systems, 838–846.