A detecção de fraude é geralmente tratada como um problema de classificação binária: um sistema de detecção de fraude recebe transações e seu objetivo é prever se são provavelmente legítimas ou fraudulentas. Dada uma transação (com características , , ...), um sistema de detecção de fraude retorna uma pontuação de fraude e a classifica como legítima ou fraudulenta, conforme ilustrado na Fig. 1.
As pontuações de fraude retornadas por um sistema de detecção de fraude em um conjunto de transações precisam apenas ser ordenadas. Quanto maior seu valor, maior a probabilidade de a transação ser uma fraude. Por simplicidade, assumiremos a seguir que a pontuação de fraude é a probabilidade de uma transação ser uma fraude, ou seja, um valor entre 0 e 1.
A decisão de classificar uma transação como fraudulenta pode então ser feita definindo um limiar sobre a probabilidade , de forma que se , a transação é classificada como fraudulenta, ou como legítima se .
Notebook Cell
# Initialization: Load shared functions
# Load shared functions
!curl -O https://raw.githubusercontent.com/Fraud-Detection-Handbook/fraud-detection-handbook/main/Chapter_References/shared_functions.py
%run shared_functions.py
# For plotting confusion matrices
from pretty_plot_confusion_matrix import plot_confusion_matrix_from_data
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 37136 100 37136 0 0 533k 0 --:--:-- --:--:-- --:--:-- 533k
# Getting classes from a vector of fraud probabilities and a threshold
def get_class_from_fraud_probability(fraud_probabilities, threshold=0.5):
predicted_classes = [0 if fraud_probability<threshold else 1
for fraud_probability in fraud_probabilities]
return predicted_classesMatriz de confusão¶
Uma vez que um limiar é definido, o resultado de um problema de classificação binária é geralmente representado como uma matriz de confusão. Denotando por o conjunto de instâncias positivas (fraudes), o conjunto de instâncias negativas (legítimas), o conjunto de instâncias preditas como positivas e as preditas como negativas, a matriz de confusão é representada da seguinte forma, ver Fig. 2 Tharwat (2020)Dal Pozzolo (2015).
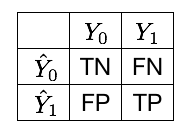
Os quatro resultados possíveis são:
VP: Verdadeiros positivos. São as instâncias da classe 1 (transações fraudulentas) que o classificador prevê corretamente como fraudulentas.
VN: Verdadeiros negativos. São as instâncias da classe 0 (transações legítimas) que o classificador prevê corretamente como legítimas.
FP: Falsos positivos. São as instâncias da classe 0 (transações legítimas) que o classificador prevê incorretamente como fraudulentas.
FN: Falsos negativos. São as instâncias da classe 1 (transações fraudulentas) que o classificador prevê incorretamente como legítimas.
Erro médio de classificação incorreta¶
A forma mais direta de avaliar o desempenho de um classificador binário é calculando a proporção de instâncias classificadas incorretamente. Essa quantidade é conhecida como erro médio de classificação incorreta (MME, do inglês mean misclassification error) e é calculada da seguinte forma:
onde é o tamanho do conjunto de dados.
Note que a medida complementar às vezes é usada em vez disso e é referida como acurácia (sklearn.metrics.accuracy_score).
# Implementation of the mean misclassification error
def compute_MME(true_labels,predicted_classes):
N = len(true_labels)
MME = np.sum(np.array(true_labels)!=np.array(predicted_classes))/N
return MMEO MME é geralmente um bom indicador do desempenho de um classificador para conjuntos de dados balanceados. Para problemas sensíveis a custo, como detecção de fraude, o MME tem várias limitações. Vamos ilustrar isso com o seguinte exemplo:
10 transações
2 das quais são fraudulentas, e 8 das quais são legítimas
A lista
true_labelsfornece a lista de rótulos fraudulentos (1) e legítimos (0)A lista
fraud_probabilitiesfornece as previsões de fraude de um sistema de detecção de fraude
# 2 fraudulent and 8 genuine transactions
true_labels = [1,1,0,0,0,0,0,0,0,0]
# Probability of fraud for each transaction
fraud_probabilities = [0.9,0.35,0.45,0.4,0.2,0.2,0.2,0.1,0.1,0]
E vamos considerar três limiares:
: Este limiar não leva em consideração as probabilidades de fraude e classifica todas as transações como legítimas.
: Este limiar é geralmente considerado o limiar padrão, que assume que uma transação com probabilidade de fraude superior a 0,5 será classificada como fraude.
: Dados as probabilidades de fraude previstas deste exemplo, este limiar permitirá classificar corretamente as duas transações fraudulentas.
Vamos plotar a matriz de confusão para esses 3 limiares:
Notebook Cell
%%capture
confusion_matrix_plots,ax=plt.subplots(1, 3, figsize=(17,4))
thresholds=[1,0.5,0.3]
for i in range(len(thresholds)):
predicted_classes = get_class_from_fraud_probability(fraud_probabilities, threshold=thresholds[i])
MME = compute_MME(true_labels,predicted_classes)
confusion_matrix_plot = plot_confusion_matrix_from_data(true_labels, predicted_classes, columns=[0,1],
annot=True, cmap="Oranges",
fmt='.2f', fz=12, lw=0.5, cbar=True,
figsize=[4,4], show_null_values=1,
pred_val_axis='lin',
subtitle="Threshold="+str(thresholds[i])+". MME="+str(MME),ax=ax[i])
plt.subplots_adjust(wspace=0.5)confusion_matrix_plots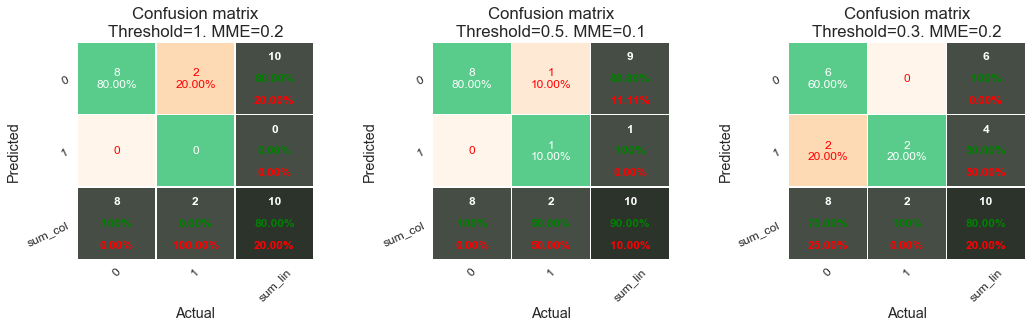
Além da matriz de confusão, também calculamos explicitamente o MME e o reportamos no título. Note que o MME também é reportado em vermelho na matriz de confusão na célula inferior direita, como porcentagem. Vamos agora considerar os resultados obtidos com esses três limiares em mais detalhe.
Com um limiar , todas as transações são preditas como legítimas. O classificador comete dois erros: classifica as duas transações fraudulentas como legítimas (2 falsos negativos). O MME é, portanto, 0,2, ou seja, 80% de classificações corretas. Esse alto percentual de classificações corretas é, no entanto, um artefato do desequilíbrio de classes do conjunto de dados. O preditor é praticamente inútil, pois não detecta nenhuma transação fraudulenta.
Com um limiar , o classificador é melhor, com um MME de 0,1. Ele só classifica incorretamente uma transação fraudulenta (um FN).
Por fim, ao diminuir ainda mais o limiar para , o classificador detecta corretamente as duas transações fraudulentas (sem falsos negativos). No entanto, classifica incorretamente duas transações legítimas como fraudulentas. O MME resultante é 0,2, ou seja, o mesmo que o primeiro classificador.
Este exemplo ilustra a principal limitação do MME: ele dá o mesmo peso aos falsos negativos e falsos positivos. O primeiro classificador (limiar ) é inútil como detector de fraude, enquanto o terceiro classificador (limiar ) identifica corretamente as duas transações fraudulentas, ao custo de dois falsos positivos. O MME tem o mesmo erro de classificação para o primeiro e o terceiro classificador, e um erro menor para o segundo (uma classificação incorreta). Um caso mais desproporcional com mais transações legítimas exacerbaria ainda mais esse comportamento. Decidir qual desses três classificadores é o melhor é, no entanto, uma questão não trivial. Depende da importância que damos à detecção de fraude.
Matriz de custo e perda ponderada¶
Um problema de detecção de fraude é por natureza um problema sensível a custo: deixar passar uma transação fraudulenta é geralmente considerado mais custoso do que emitir um falso alerta em uma transação legítima. No primeiro caso, as perdas não incluem apenas o valor da transação fraudulenta. Elas também incluem outras transações fraudulentas que podem ser realizadas com o cartão comprometido, bem como custos de atendimento ao cliente relacionados à resolução posterior do problema e a reputação geral da empresa. No segundo caso, o custo se resume a verificar a legitimidade da transação com o cliente. Em caso de detecção em tempo real, também inclui o inconveniente para o cliente de ter seu pagamento legítimo bloqueado.
Uma abordagem possível para corrigir o apresentado acima é definir uma matriz de custo. A matriz de custo quantifica, para cada resultado na matriz de confusão, um custo associado. É uma matriz 2 × 2, cujas entradas são denotadas seguindo as notações de Elkan (2001).
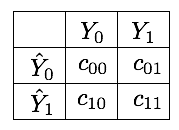
O erro de classificação pode então ser expresso como uma perda ponderada esperada, multiplicando cada entrada da matriz de confusão pela entrada correspondente na matriz de custo Fernández et al. (2018)Gupta et al. (2020). Denotando por essa quantidade (perda ponderada), obtemos:
Os custos de verdadeiros negativos e verdadeiros positivos são geralmente 0, pois essas são as entradas que correspondem a classificações corretas. Isso simplifica a expressão de para:
Na prática, no entanto, é difícil definir os valores e Dal Pozzolo (2015).
Ao definir uma medida de custo, pode-se considerar o custo de um FN fixo ou dependente do valor da transação. No primeiro caso, cada fraude tem o mesmo custo, enquanto no segundo o custo depende do exemplo. Um argumento para usar custo fixo é dar igual importância a fraudes pequenas e maiores (os fraudadores geralmente testam um cartão com valores pequenos), enquanto o custo dependente da transação permite quantificar a perda real que uma empresa precisa enfrentar.
No caso dependente da transação, o custo de uma fraude não detectada (FN) é frequentemente assumido como igual ao valor da transação Elkan (2001)Dal Pozzolo (2015), pois precisa ser reembolsado ao cliente. O limite de gastos do cartão também pode ser considerado para levar em conta o dano potencial máximo que uma fraude não detectada pode causar. O custo de alertas corretos ou falsos é considerado equivalente ao custo de um investigador verificar com o titular do cartão se uma transação foi fraudulenta. O custo de uma ligação telefônica é insignificante comparado à perda que ocorre em caso de fraude. No entanto, quando o número de falsos alertas é muito grande ou o cartão é bloqueado por engano, a impossibilidade de fazer transações pode se traduzir em grandes perdas para o cliente.
O custo geral também deve incluir o tempo que o sistema de detecção leva para reagir. Quanto menor o tempo de reação, maior o número de fraudes que podem ser prevenidas. Normalmente, uma vez que os fraudadores perpetram com sucesso uma fraude, tentam gastar todo o dinheiro disponível no cartão. Como consequência, ao avaliar um SDF, também se deve considerar o limite de gastos de cada cartão: detectar uma fraude em um cartão com um grande limite de gastos (por exemplo, cartões corporativos) resulta em maior economia do que detectar uma fraude em um cartão com um pequeno limite de gastos. Outra consideração é que às vezes existem restrições específicas de negócios especificadas em contratos (por exemplo, pelo menos uma fraude em três deve ser detectada). Nesse caso, uma métrica é fixada (aqui a TPR, definida abaixo) e o objetivo é otimizar uma complementar (por exemplo, a precisão). Por todas essas razões, definir uma medida de custo é um problema desafiador na detecção de fraude em cartão de crédito e não há consenso sobre qual é a forma correta de medir o custo das fraudes Dal Pozzolo (2015).
Outras métricas de desempenho derivadas da matriz de confusão¶
Métricas mais específicas sobre classificações incorretas podem ser obtidas focando em proporções dentro das colunas ou linhas de uma matriz de confusão.
Por coluna¶
Por coluna, duas quantidades significativas são a Taxa de Verdadeiros Positivos (TPR) e a Taxa de Verdadeiros Negativos (TNR). A TPR mede a proporção de positivos que são corretamente identificados (por exemplo, a proporção de fraudes que são corretamente classificadas como fraudes). Também é chamada de recall, taxa de acerto ou sensibilidade. É definida como:
A TNR mede a proporção de negativos que são corretamente identificados (por exemplo, a proporção de transações legítimas que são corretamente classificadas como legítimas). Também é chamada de especificidade ou seletividade. É definida como:
Alternativamente, as medidas complementares, ou seja, as proporções de previsões incorretas, também podem ser calculadas. Elas são chamadas de Taxa de Falsos Negativos (FNR) e Taxa de Falsos Positivos (FPR). Note que a FNR e a TPR somam 1, assim como a FPR e a TNR.
Tomar a média da FNR e da FPR fornece uma medida balanceada de acurácia conhecida como Taxa de Erro Balanceada (BER, do inglês Balanced Error Rate) Fernández et al. (2018):
O BER é uma perda ponderada onde os custos de classificação incorreta compensam o desequilíbrio de classes. Uma medida alternativa que agrega a TNR e a TPR é a média geométrica G-mean, definida como Fernández et al. (2018).
Por linha¶
Por linha, a métrica mais comumente usada é a precisão, também conhecida como Valor Preditivo Positivo. Ela mede, para o conjunto de transações previstas como fraudulentas, a proporção de transações que são de fato fraudulentas.
Um sistema com alto recall mas baixa precisão retorna muitos alertas, mas a maioria dos alertas está incorreta quando comparada aos rótulos reais (muitos falsos positivos). Um sistema com alta precisão mas baixo recall é exatamente o oposto, retornando muito poucos alertas, mas a maioria de seus alertas está correta. Um sistema ideal com alta precisão e alto recall retorna muitos alertas, com todos os alertas rotulados corretamente. Para um sistema de bloqueio totalmente automatizado, alta precisão seria preferível. Para um sistema com uma segunda camada de verificação humana, alto recall é benéfico, pois os falsos positivos serão descartados de qualquer forma pelos investigadores, dentro do limite de sua capacidade.
As outras três métricas que podem ser calculadas por linha são o Valor Preditivo Negativo (NPV), a Taxa de Descoberta Falsa (FDR) e a Taxa de Omissão Falsa (FOR). Elas são definidas como Fernández et al. (2018):
Uma medida agregada da precisão e do recall frequentemente usada na prática é o F1-score. É definida como a média harmônica das duas quantidades:
O F1-score e o G-mean são frequentemente considerados medidas relevantes em problemas desbalanceados Chawla et al. (2008),Chen et al. (2004). Essas medidas, no entanto, só podem ser calculadas uma vez que uma matriz de confusão esteja disponível, o que significa que seus valores dependem do limiar usado para classificação. Alterar o limiar corresponde a usar diferentes custos de classificação incorreta.
Implementação¶
Vamos implementar todas essas medidas usando uma função threshold_based_metrics. A função recebe como entrada uma lista de previsões, uma lista de rótulos verdadeiros e uma lista de limiares. Ela retorna, para cada limiar na lista de limiares, o conjunto de medidas de desempenho.
Notebook Cell
def threshold_based_metrics(fraud_probabilities, true_label, thresholds_list):
results = []
for threshold in thresholds_list:
predicted_classes = get_class_from_fraud_probability(fraud_probabilities, threshold=threshold)
(TN, FP, FN, TP) = metrics.confusion_matrix(true_label, predicted_classes).ravel()
MME = (FP+FN)/(TN+FP+FN+TP)
TPR = TP/(TP+FN)
TNR = TN/(TN+FP)
FPR = FP/(TN+FP)
FNR = FN/(TP+FN)
BER = 1/2*(FPR+FNR)
Gmean = np.sqrt(TPR*TNR)
precision = 0
FDR = 0
F1_score=0
if TP+FP>0:
precision = TP/(TP+FP)
FDR=FP/(TP+FP)
NPV = 0
FOR = 0
if TN+FN>0:
NPV = TN/(TN+FN)
FOR = FN/(TN+FN)
if precision+TPR>0:
F1_score = 2*(precision*TPR)/(precision+TPR)
results.append([threshold, MME, TPR, TNR, FPR, FNR, BER, Gmean, precision, NPV, FDR, FOR, F1_score])
results_df = pd.DataFrame(results,columns=['Threshold' ,'MME', 'TPR', 'TNR', 'FPR', 'FNR', 'BER', 'G-mean', 'Precision', 'NPV', 'FDR', 'FOR', 'F1 Score'])
return results_df
Vamos calcular as métricas baseadas em limiar para todos os limiares possíveis.
unique_thresholds = list(set(fraud_probabilities))
unique_thresholds.sort(reverse=True)
unique_thresholds[0.9, 0.45, 0.4, 0.35, 0.2, 0.1, 0]results_df = threshold_based_metrics(fraud_probabilities, true_labels, unique_thresholds)results_dfObservamos que um limiar de é o que minimiza o BER e maximiza o G-mean e o F1-score. O limiar fornece uma TPR (recall) de 1 e uma precisão de 0,5, e poderia, portanto, ser uma escolha sensata para este exemplo simples. Se o problema exigir maximizar a precisão, um limiar de deve ser selecionado.
Para concluir esta seção, o principal benefício das métricas baseadas em limiar é fornecer uma visão detalhada dos erros de classificação. Esse benefício é também sua desvantagem. Devido à multiplicidade de medidas e à sua dependência do limiar de decisão , elas tornam a comparação de dois classificadores difícil. Na verdade, somente se as restrições e o objetivo da aplicação estiverem claramente definidos (por exemplo, o objetivo é capturar o máximo de fraudes enquanto garante que a precisão permaneça acima de 60%) é que a otimização do limiar e as métricas baseadas em limiar fazem sentido. Caso contrário, é melhor realizar uma comparação mais geral com métricas independentes de limiar, abordadas na próxima seção, que visam caracterizar com um único número o desempenho de um classificador para todos os limiares possíveis.
- Tharwat, A. (2020). Classification assessment methods. Applied Computing and Informatics.
- Dal Pozzolo, A. (2015). Adaptive machine learning for credit card fraud detection. Université libre de Bruxelles.
- Elkan, C. (2001). The foundations of cost-sensitive learning. International Joint Conference on Artificial Intelligence, 17(1), 973–978.
- Fernández, A., Garcı́a, S., Galar, M., Prati, R. C., Krawczyk, B., & Herrera, F. (2018). Learning from imbalanced data sets. Springer.
- Gupta, A., Tatbul, N., Marcus, R., Zhou, S., Lee, I., & Gottschlich, J. (2020). Class-Weighted Evaluation Metrics for Imbalanced Data Classification. arXiv Preprint arXiv:2010.05995.
- Chawla, N. V., Cieslak, D. A., Hall, L. O., & Joshi, A. (2008). Automatically countering imbalance and its empirical relationship to cost. Data Mining and Knowledge Discovery, 17(2), 225–252.
- Chen, C., Liaw, A., Breiman, L., & others. (2004). Using random forest to learn imbalanced data. University of California, Berkeley, 110(1–12), 24.