O objetivo de um sistema de detecção de fraude é maximizar a detecção de transações fraudulentas que ocorrerão no futuro.
A abordagem mais direta para treinar e avaliar um modelo de predição para um sistema de detecção de fraude é ilustrada na Fig. 1. Para clareza da ilustração, o fluxo de dados de transações é discretizado em blocos. Um bloco corresponde a um período de tempo (como uma semana ou um dia). Assumimos que o modelo de predição deve ser atualizado a cada novo bloco Dal Pozzolo et al. (2017)Dal Pozzolo (2015).
Esta é a abordagem que usamos na seção Sistema de detecção de fraude de linha de base. Os blocos correspondiam a uma semana de dados de transações. Um bloco de dados foi usado para treinamento e um bloco de dados para teste. Um atraso de uma semana também foi usado para separar os blocos de treinamento e teste.
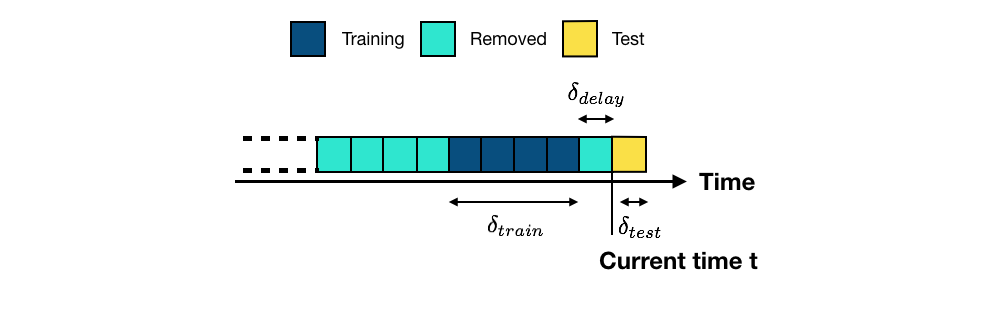
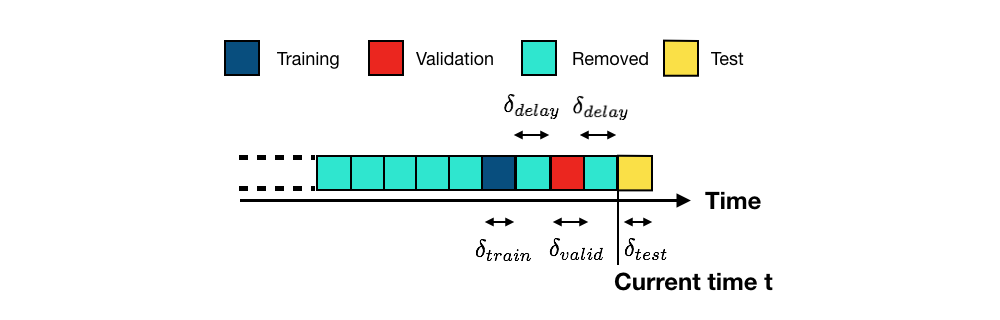
De forma mais geral, dado um conjunto de blocos de transações passadas coletados até o instante atual , o objetivo do modelo de predição é fornecer previsões para transações que ocorrerão no próximo bloco (transações futuras, também chamadas de transações de teste, em amarelo) Dal Pozzolo et al. (2017)Dal Pozzolo (2015). O conjunto de blocos usados para treinamento são os blocos de treinamento (em azul escuro). Devido ao atraso na obtenção dos rótulos das transações (ver seção Sistema de detecção de fraude de cartão de crédito), as transações mais recentes geralmente não podem ser usadas para treinamento (período de atraso, em azul claro) e são removidas. Blocos mais antigos também são geralmente descartados, devido à deriva de conceito (em azul claro, também removidos). Denotemos os comprimentos dos períodos de treinamento, atraso e teste por , e , respectivamente.
O desempenho de um modelo nos dados de treinamento é frequentemente um mau indicador do desempenho em dados futuros Bontempi (2021)Bishop (2006)Friedman et al. (2001). O primeiro é chamado de desempenho de treinamento, e o segundo de desempenho de teste (isto é, o desempenho do modelo quando testado em dados não vistos). Em particular, aumentar o grau de liberdade de um modelo (como a profundidade de uma árvore de decisão) sempre permite aumentar o desempenho de treinamento, mas geralmente leva a desempenhos menores no teste (fenômeno de sobreajuste).
Os procedimentos de validação visam resolver esse problema estimando, em dados passados, o desempenho de teste de um modelo de predição, reservando uma parte deles Cerqueira et al. (2020)Gama et al. (2014). Eles funcionam dividindo os dados rotulados passados em dois conjuntos, o conjunto de treinamento e o conjunto de validação, que simulam o cenário de um sistema de detecção de fraude do mundo real. O conjunto de validação desempenha o papel do conjunto de teste. Isso é ilustrado na Fig. 2.
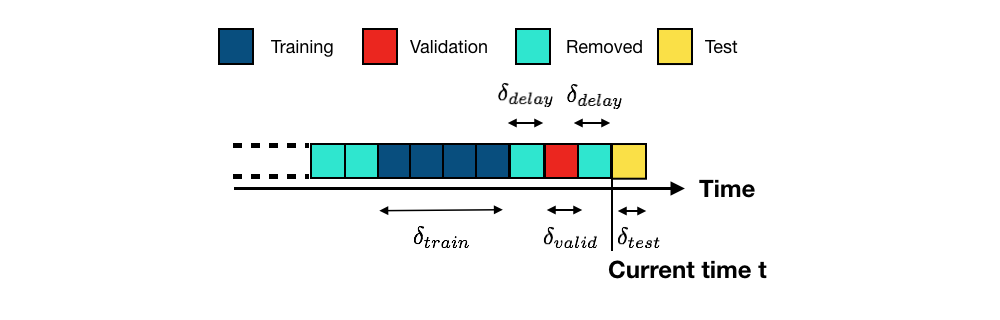
Para melhor simular o cenário ilustrado na Fig. 1, os conjuntos de treinamento e validação são separados com o mesmo período de atraso. O comprimento do conjunto de validação () é definido igual ao comprimento do conjunto de teste (). O desempenho de um modelo no conjunto de validação é usado como estimativa do desempenho esperado no conjunto de teste.
A estratégia de validação ilustrada na Fig. 2 é chamada de validação holdout (já que parte das transações rotuladas disponíveis é retida dos dados de treinamento). Variantes dessa abordagem são a validação holdout repetida e a validação prequencial. A primeira é igual à validação holdout, exceto que o procedimento é repetido várias vezes usando diferentes subconjuntos dos dados de treinamento. A segunda é uma variante que repete a validação holdout deslocando os conjuntos de treinamento e validação no passado. Tanto a validação holdout repetida quanto a prequencial permitem fornecer estimativas de desempenho no conjunto de teste, juntamente com intervalos de confiança Cerqueira et al. (2020)Gama et al. (2014).
As próximas seções detalham esses procedimentos de validação. Primeiro ilustramos usando dados simulados e árvores de decisão que o desempenho de treinamento é uma má estimativa do desempenho de teste. Em seguida, fornecemos implementações das validações holdout, holdout repetida e prequencial, e discutimos seus prós e contras.
Notebook Cell
# Initialization: Load shared functions and simulated data
# Load shared functions
!curl -O https://raw.githubusercontent.com/Fraud-Detection-Handbook/fraud-detection-handbook/main/Chapter_References/shared_functions.py
%run shared_functions.py
# Get simulated data from Github repository
if not os.path.exists("simulated-data-transformed"):
!git clone https://github.com/Fraud-Detection-Handbook/simulated-data-transformed
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 41751 100 41751 0 0 147k 0 --:--:-- --:--:-- --:--:-- 147k
Desempenho de treinamento versus desempenho de teste¶
Primeiro ilustramos que o desempenho de treinamento é um mau indicador do desempenho de teste. Reutilizamos a mesma configuração experimental do Capítulo 3 - Sistema de detecção de fraude de linha de base. Uma semana de dados é usada para treinar o modelo de predição, e uma semana de dados para testar as previsões. Usamos um modelo de árvore de decisão e avaliamos os desempenhos de treinamento e teste para árvores de decisão com diferentes profundidades, variando de dois a cinquenta. Os desempenhos são avaliados em termos de AUC ROC, Precisão Média e Precisão de Cartão@100, conforme motivado no Capítulo 4 - Introdução.
Vamos primeiro carregar os dados simulados e definir a característica de saída e as características de entrada como na seção Treinamento do modelo: Árvore de decisão.
# Note: We load more data than three weeks, as the experiments in the next sections
# will require up to three months of data
# Load data from the 2018-06-11 to the 2018-09-14
DIR_INPUT='simulated-data-transformed/data/'
BEGIN_DATE = "2018-06-11"
END_DATE = "2018-09-14"
print("Load files")
%time transactions_df=read_from_files(DIR_INPUT, BEGIN_DATE, END_DATE)
print("{0} transactions loaded, containing {1} fraudulent transactions".format(len(transactions_df),transactions_df.TX_FRAUD.sum()))
output_feature="TX_FRAUD"
input_features=['TX_AMOUNT','TX_DURING_WEEKEND', 'TX_DURING_NIGHT', 'CUSTOMER_ID_NB_TX_1DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_1DAY_WINDOW', 'CUSTOMER_ID_NB_TX_7DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_7DAY_WINDOW', 'CUSTOMER_ID_NB_TX_30DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_30DAY_WINDOW', 'TERMINAL_ID_NB_TX_1DAY_WINDOW',
'TERMINAL_ID_RISK_1DAY_WINDOW', 'TERMINAL_ID_NB_TX_7DAY_WINDOW',
'TERMINAL_ID_RISK_7DAY_WINDOW', 'TERMINAL_ID_NB_TX_30DAY_WINDOW',
'TERMINAL_ID_RISK_30DAY_WINDOW']
Load files
CPU times: user 1.04 s, sys: 778 ms, total: 1.82 s
Wall time: 2.16 s
919767 transactions loaded, containing 8195 fraudulent transactions
Usar uma semana para treinamento, uma semana para teste e uma semana de atraso corresponde à configuração experimental ilustrada na Fig. 3.
Vamos definir o início do período de treinamento como 2018-07-25, e os deltas para treinamento, atraso e teste como 7 dias (uma semana).
# Set the starting day for the training period, and the deltas
start_date_training = datetime.datetime.strptime("2018-07-25", "%Y-%m-%d")
delta_train=7
delta_delay=7
delta_test=7
Definimos uma função get_performances_train_test_sets para treinar um modelo e avaliar seu desempenho nos conjuntos de treinamento e teste. A função realiza as mesmas etapas descritas na seção Sistema de detecção de fraude de linha de base. As quatro etapas principais são:
Definir a data de início do período de treinamento e os deltas para treinamento, atraso e teste
Obter os conjuntos de treinamento e teste
Ajustar o modelo e coletar as previsões
Avaliar os desempenhos tanto no conjunto de treinamento quanto no conjunto de teste
Notebook Cell
def get_performances_train_test_sets(transactions_df, classifier,
input_features, output_feature,
start_date_training,
delta_train=7, delta_delay=7, delta_test=7,
top_k_list=[100],
type_test="Test", parameter_summary=""):
# Get the training and test sets
(train_df, test_df)=get_train_test_set(transactions_df,start_date_training,
delta_train=delta_train,
delta_delay=delta_delay,
delta_test=delta_test)
# Fit model
start_time=time.time()
model_and_predictions_dictionary = fit_model_and_get_predictions(classifier, train_df, test_df,
input_features, output_feature)
execution_time=time.time()-start_time
# Compute fraud detection performances
test_df['predictions']=model_and_predictions_dictionary['predictions_test']
performances_df_test=performance_assessment(test_df, top_k_list=top_k_list)
performances_df_test.columns=performances_df_test.columns.values+' '+type_test
train_df['predictions']=model_and_predictions_dictionary['predictions_train']
performances_df_train=performance_assessment(train_df, top_k_list=top_k_list)
performances_df_train.columns=performances_df_train.columns.values+' Train'
performances_df=pd.concat([performances_df_test,performances_df_train],axis=1)
performances_df['Execution time']=execution_time
performances_df['Parameters summary']=parameter_summary
return performances_df
Vamos, por exemplo, calcular as acurácias de teste e treinamento usando uma árvore de decisão com profundidade 2.
classifier = sklearn.tree.DecisionTreeClassifier(max_depth=2, random_state=0)
performances_df=get_performances_train_test_sets(transactions_df, classifier,
input_features, output_feature,
start_date_training=start_date_training,
delta_train=delta_train,
delta_delay=delta_delay,
delta_test=delta_test,
parameter_summary=2
)performances_dfObserve que os desempenhos são os mesmos obtidos na seção Desempenhos usando modelos de predição padrão.
Podemos então calcular os desempenhos para diferentes profundidades de árvore de decisão. Vamos variar as profundidades de dois a cinquenta, usando os seguintes valores: .
list_params = [2,3,4,5,6,7,8,9,10,20,50]
performances_df=pd.DataFrame()
for max_depth in list_params:
classifier = sklearn.tree.DecisionTreeClassifier(max_depth = max_depth, random_state=0)
performances_df=performances_df.append(
get_performances_train_test_sets(transactions_df, classifier,
input_features, output_feature,
start_date_training=start_date_training,
delta_train=delta_train,
delta_delay=delta_delay,
delta_test=delta_test,
parameter_summary=max_depth
)
)
performances_df.reset_index(inplace=True,drop=True)performances_dfPara melhor visualização dos resultados, vamos plotar os desempenhos resultantes em termos de AUC ROC, AP e CP@100, em função da profundidade da árvore de decisão.
Notebook Cell
# Get the performance plot for a single performance metric
def get_performance_plot(performances_df,
ax,
performance_metric,
expe_type_list=['Test','Train'],
expe_type_color_list=['#008000','#2F4D7E'],
parameter_name="Tree maximum depth",
summary_performances=None):
# expe_type_list is the list of type of experiments, typically containing 'Test', 'Train', or 'Valid'
# For all types of experiments
for i in range(len(expe_type_list)):
# Column in performances_df for which to retrieve the data
performance_metric_expe_type=performance_metric+' '+expe_type_list[i]
# Plot data on graph
ax.plot(performances_df['Parameters summary'], performances_df[performance_metric_expe_type],
color=expe_type_color_list[i], label = expe_type_list[i])
# If performances_df contains confidence intervals, add them to the graph
if performance_metric_expe_type+' Std' in performances_df.columns:
conf_min = performances_df[performance_metric_expe_type]\
-2*performances_df[performance_metric_expe_type+' Std']
conf_max = performances_df[performance_metric_expe_type]\
+2*performances_df[performance_metric_expe_type+' Std']
ax.fill_between(performances_df['Parameters summary'], conf_min, conf_max, color=expe_type_color_list[i], alpha=.1)
# If summary_performances table is present, adds vertical dashed bar for best estimated parameter
if summary_performances is not None:
best_estimated_parameter=summary_performances[performance_metric][['Best estimated parameters ($k^*$)']].values[0]
best_estimated_performance=float(summary_performances[performance_metric][['Validation performance']].values[0].split("+/-")[0])
ymin, ymax = ax.get_ylim()
ax.vlines(best_estimated_parameter, ymin, best_estimated_performance,
linestyles="dashed")
# Set title, and x and y axes labels
ax.set_title(performance_metric+'\n', fontsize=14)
ax.set(xlabel = parameter_name, ylabel=performance_metric)
# Get the performance plots for a set of performance metric
def get_performances_plots(performances_df,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Train'], expe_type_color_list=['#008000','#2F4D7E'],
parameter_name="Tree maximum depth",
summary_performances=None):
# Create as many graphs as there are performance metrics to display
n_performance_metrics = len(performance_metrics_list)
fig, ax = plt.subplots(1, n_performance_metrics, figsize=(5*n_performance_metrics,4))
# Plot performance metric for each metric in performance_metrics_list
for i in range(n_performance_metrics):
get_performance_plot(performances_df, ax[i], performance_metric=performance_metrics_list[i],
expe_type_list=expe_type_list,
expe_type_color_list=expe_type_color_list,
parameter_name=parameter_name,
summary_performances=summary_performances)
ax[n_performance_metrics-1].legend(loc='upper left',
labels=expe_type_list,
bbox_to_anchor=(1.05, 1),
title="Type set")
plt.subplots_adjust(wspace=0.5,
hspace=0.8)get_performances_plots(performances_df,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Train'],expe_type_color_list=['#008000','#2F4D7E'])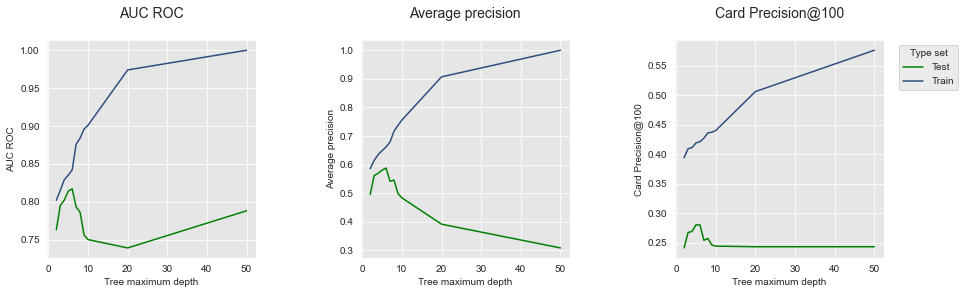
O desempenho de treinamento é plotado em azul, e o desempenho de teste em verde. O gráfico ilustra claramente o fenômeno de sobreajuste: o desempenho de treinamento continua aumentando com a profundidade da árvore e atinge um ajuste perfeito, ou seja, o maior AUC ROC/AP possível, para uma profundidade de cinquenta. O desempenho de teste, no entanto, atinge seu pico em uma profundidade de 6. Uma profundidade de 6 é, portanto, a profundidade que maximiza o desempenho no conjunto de teste quando uma árvore de decisão é usada como modelo de predição.
Lembremos também que a Precisão de Cartão@100 é a métrica de maior interesse para investigadores de fraude. Vale notar que o AUC ROC no conjunto de teste tem uma dinâmica diferente do CP@100: para a maior profundidade de árvore de cinquenta, a acurácia em termos de AUC ROC aumenta, enquanto o CP@100 permanece baixo. Isso ilustra experimentalmente que o AUC ROC não é uma métrica adequada para investigadores de fraude.
Validação holdout¶
Como ilustrado acima, o desempenho de treinamento não fornece orientação sobre como selecionar o modelo de predição que melhor se desempenha nos dados de teste. Lembremos também que os dados de teste não podem ser usados para estimar o modelo de predição no momento do treinamento, pois ainda não foram coletados.
Uma maneira simples de antecipar o desempenho do modelo na etapa de teste é simular a configuração como acima, mas deslocada no passado, usando apenas os dados históricos disponíveis no momento do treinamento. O bloco mais recente com dados rotulados é usado como conjunto de validação. O conjunto de treinamento consiste nos blocos de transações que precedem o conjunto de validação, com um bloco de atraso entre eles. A configuração de validação é ilustrada na Fig. 4.
Essa estratégia de validação é chamada de validação holdout, pois parte dos dados históricos é retida do conjunto de treinamento.
Como a validação holdout apenas desloca a configuração experimental, o mesmo código da seção anterior pode ser reutilizado. A única coisa a mudar é deslocar a data de início do treinamento para o passado.
Vamos, portanto, deslocar a data de início do conjunto de treinamento dois blocos para trás (os deltas dos períodos de atraso e validação), e calcular o desempenho no conjunto de validação usando a função get_performances_train_test_sets. Como exemplo, podemos começar com uma árvore de decisão de profundidade 2.
classifier = sklearn.tree.DecisionTreeClassifier(max_depth = 2, random_state=0)
delta_valid = delta_test
start_date_training_with_valid = start_date_training+datetime.timedelta(days=-(delta_delay+delta_valid))
performances_df_validation=get_performances_train_test_sets(transactions_df,
classifier,
input_features, output_feature,
start_date_training=start_date_training_with_valid,
delta_train=delta_train,
delta_delay=delta_delay,
delta_test=delta_test,
type_test='Validation', parameter_summary='2')performances_df_validationVamos comparar os resultados com os obtidos na seção anterior.
performances_df[:1]Os desempenhos obtidos no conjunto de validação são muito similares aos obtidos no conjunto de teste, ilustrando a capacidade do conjunto de validação de fornecer estimativas dos desempenhos esperados no conjunto de teste.
Vamos então calcular os desempenhos esperados para diferentes profundidades de árvores de decisão (com valores ).
list_params = [2,3,4,5,6,7,8,9,10,20,50]
performances_df_validation=pd.DataFrame()
for max_depth in list_params:
classifier = sklearn.tree.DecisionTreeClassifier(max_depth = max_depth, random_state=0)
performances_df_validation=performances_df_validation.append(
get_performances_train_test_sets(transactions_df,
classifier,
input_features, output_feature,
start_date_training=start_date_training_with_valid,
delta_train=delta_train,
delta_delay=delta_delay,
delta_test=delta_test,
type_test='Validation', parameter_summary=max_depth
)
)
performances_df_validation.reset_index(inplace=True,drop=True)performances_df_validationPara melhor visualização, vamos plotar os desempenhos de validação e teste em termos de AUC ROC, AP e CP@100, em função da profundidade da árvore de decisão.
performances_df_validation['AUC ROC Test']=performances_df['AUC ROC Test']
performances_df_validation['Average precision Test']=performances_df['Average precision Test']
performances_df_validation['Card Precision@100 Test']=performances_df['Card Precision@100 Test']
get_performances_plots(performances_df_validation,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'],expe_type_color_list=['#008000','#FF0000'])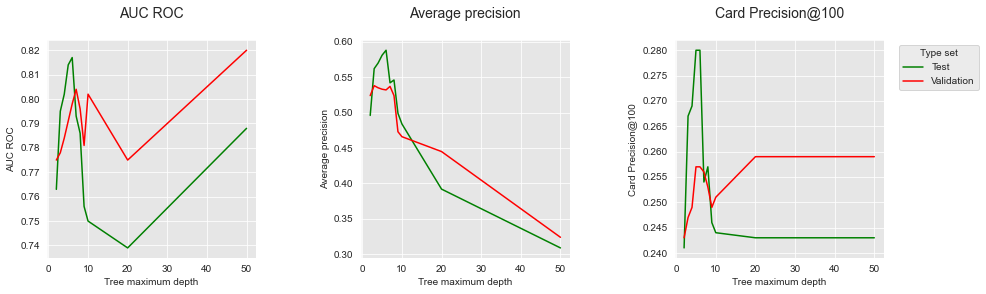
Os gráficos mostram insights interessantes sobre a capacidade do conjunto de validação de fornecer tanto uma boa estimativa de desempenho para o conjunto de teste quanto uma forma de selecionar o melhor modelo. Primeiro, deve-se notar que os desempenhos obtidos nos dois conjuntos diferem em termos de valores exatos, mas tendem a seguir dinâmicas similares. Correspondências exatas em termos de desempenho não podem ser esperadas, pois diferentes conjuntos são usados para treinamento e teste.
Os desempenhos obtidos no conjunto de validação fornecem, no entanto, orientação para selecionar as profundidades de árvore que podem maximizar o desempenho no conjunto de teste. Isso é particularmente verdadeiro para o desempenho em termos de AP, onde a profundidade ótima está na faixa de 3 a 8.
O AUC ROC e o CP@100 apresentam, no entanto, mais discrepâncias e parecem menos adequados para determinar a profundidade ótima da árvore. Em particular, seu valor é maximizado no conjunto de validação para uma profundidade de árvore de 50, enquanto tal profundidade fornece baixo desempenho no conjunto de teste.
Validação holdout repetida¶
Modelos de predição, e seus desempenhos, são frequentemente sensíveis aos dados usados para treinamento. Mudar ligeiramente o conjunto de treinamento pode resultar em diferentes modelos de predição e desempenhos.
Uma alternativa ao procedimento de validação holdout consiste em treinar diferentes modelos de predição com amostras aleatórias dos dados de treinamento. Isso permite obter diferentes estimativas do erro de validação, fornecendo assim intervalos de confiança sobre os desempenhos esperados, em vez de uma única estimativa. O procedimento é chamado de validação holdout repetida.
A validação holdout repetida pode ser implementada com uma pequena modificação na função get_performances_train_test_sets definida acima. A função recebe dois parâmetros adicionais:
n_folds: O número de subconjuntos aleatórios que serão usados para treinar os diferentes modelos de prediçãosampling_ratio: A proporção de dados que serão amostrados aleatoriamente a cada vez a partir dos dados de treinamento.
Notebook Cell
def repeated_holdout_validation(transactions_df, classifier,
start_date_training,
delta_train=7, delta_delay=7, delta_test=7,
n_folds=4,
sampling_ratio=0.7,
top_k_list=[100],
type_test="Test", parameter_summary=""):
performances_df_folds=pd.DataFrame()
start_time=time.time()
for fold in range(n_folds):
# Get the training and test sets
(train_df, test_df)=get_train_test_set(transactions_df,
start_date_training,
delta_train=delta_train,delta_delay=delta_delay,delta_test=delta_test,
sampling_ratio=sampling_ratio,
random_state=fold)
# Fit model
model_and_predictions_dictionary = fit_model_and_get_predictions(classifier, train_df, test_df,
input_features, output_feature)
# Compute fraud detection performances
test_df['predictions']=model_and_predictions_dictionary['predictions_test']
performances_df_test=performance_assessment(test_df, top_k_list=top_k_list)
performances_df_test.columns=performances_df_test.columns.values+' '+type_test
train_df['predictions']=model_and_predictions_dictionary['predictions_train']
performances_df_train=performance_assessment(train_df, top_k_list=top_k_list)
performances_df_train.columns=performances_df_train.columns.values+' Train'
performances_df_folds=performances_df_folds.append(pd.concat([performances_df_test,performances_df_train],axis=1))
execution_time=time.time()-start_time
performances_df_folds_mean=performances_df_folds.mean()
performances_df_folds_std=performances_df_folds.std(ddof=0)
performances_df_folds_mean=pd.DataFrame(performances_df_folds_mean).transpose()
performances_df_folds_std=pd.DataFrame(performances_df_folds_std).transpose()
performances_df_folds_std.columns=performances_df_folds_std.columns.values+" Std"
performances_df=pd.concat([performances_df_folds_mean,performances_df_folds_std],axis=1)
performances_df['Execution time']=execution_time
performances_df['Parameters summary']=parameter_summary
return performances_df, performances_df_folds
Vamos, por exemplo, calcular a acurácia de validação com uma árvore de decisão de profundidade 2.
classifier = sklearn.tree.DecisionTreeClassifier(max_depth = 2, random_state=0)
performances_df_repeated_holdout_summary, \
performances_df_repeated_holdout_folds=repeated_holdout_validation(
transactions_df, classifier,
start_date_training=start_date_training_with_valid,
delta_train=delta_train,
delta_delay=delta_delay,
delta_test=delta_test,
n_folds=4,
sampling_ratio=0.7,
type_test="Validation", parameter_summary='2'
)A função repeated_holdout_validation retorna dois DataFrames:
performances_df_repeated_holdout_summary: Resumo das métricas de desempenho ao longo de todos os folds, em termos de média e variância padrão para cada métrica de desempenho.accuracy_df_repeated_holdout_folds: Métricas de desempenho obtidas em cada fold
performances_df_repeated_holdout_summaryperformances_df_repeated_holdout_foldsVamos então calcular os desempenhos esperados para diferentes profundidades de árvores de decisão (com valores ).
list_params = [2,3,4,5,6,7,8,9,10,20,50]
performances_df_repeated_holdout=pd.DataFrame()
start_time=time.time()
for max_depth in list_params:
print("Computing performances for a decision tree with max_depth="+str(max_depth))
classifier = sklearn.tree.DecisionTreeClassifier(max_depth = max_depth, random_state=0)
performances_df_repeated_holdout=performances_df_repeated_holdout.append(
repeated_holdout_validation(
transactions_df, classifier,
start_date_training=start_date_training_with_valid,
delta_train=delta_train,
delta_delay=delta_delay,
delta_test=delta_test,
n_folds=4,
sampling_ratio=0.7,
type_test="Validation", parameter_summary=max_depth
)[0]
)
performances_df_repeated_holdout.reset_index(inplace=True,drop=True)
print("Total execution time: "+str(round(time.time()-start_time,2))+"s")
Computing performances for a decision tree with max_depth=2
Computing performances for a decision tree with max_depth=3
Computing performances for a decision tree with max_depth=4
Computing performances for a decision tree with max_depth=5
Computing performances for a decision tree with max_depth=6
Computing performances for a decision tree with max_depth=7
Computing performances for a decision tree with max_depth=8
Computing performances for a decision tree with max_depth=9
Computing performances for a decision tree with max_depth=10
Computing performances for a decision tree with max_depth=20
Computing performances for a decision tree with max_depth=50
Total execution time: 39.19s
performances_df_repeated_holdoutPara melhor visualização, vamos plotar as acurácias de validação e teste em termos de AUC ROC, AP e CP@100, em função da profundidade da árvore de decisão.
performances_dfperformances_df_repeated_holdout['AUC ROC Test']=performances_df['AUC ROC Test']
performances_df_repeated_holdout['Average precision Test']=performances_df['Average precision Test']
performances_df_repeated_holdout['Card Precision@100 Test']=performances_df['Card Precision@100 Test']
get_performances_plots(
performances_df_repeated_holdout,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'],expe_type_color_list=['#008000','#FF0000']
)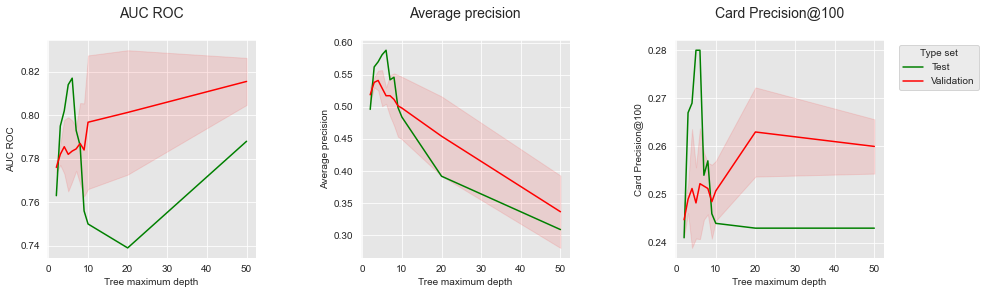
A validação holdout repetida oferece uma visão melhor dos desempenhos esperados, fornecendo intervalos de confiança. Qualitativamente, os resultados são similares à validação holdout. O AP fornece o proxy mais preciso para o desempenho esperado no conjunto de teste. O AUC ROC e o CP@100 fornecem estimativas mais fracas do desempenho de teste.
Validação prequencial¶
A validação holdout repetida baseia-se em subconjuntos aleatórios dos mesmos dados de treinamento para construir modelos de predição. Uma limitação dessa abordagem é que ela reduz os desempenhos esperados dos modelos, pois apenas subconjuntos de dados são usados para treinamento.
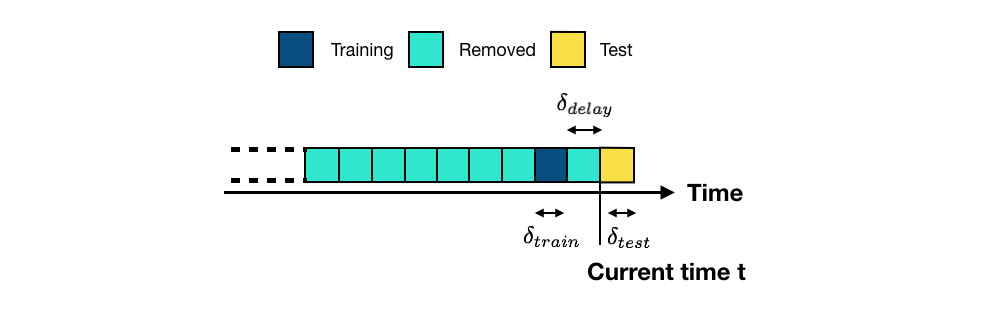
Uma alternativa de procedimento de validação consiste em usar conjuntos de treinamento de tamanhos similares, retirados de dados históricos mais antigos. O esquema é chamado de validação prequencial e é ilustrado na Fig. 5. Cada fold desloca os conjuntos de treinamento e validação um bloco para o passado.
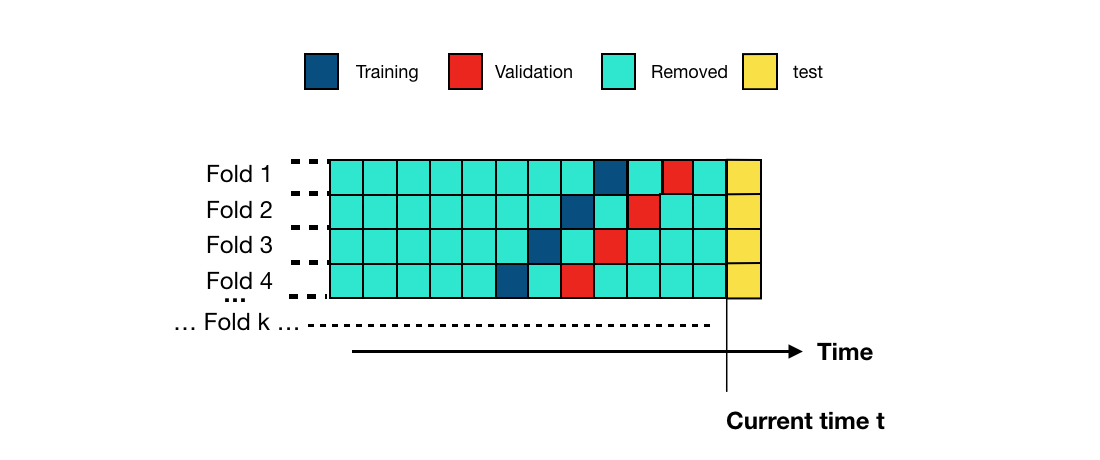
A implementação é similar à da validação holdout repetida. A única diferença é que, para cada fold, as datas de início para os conjuntos de treinamento e validação são deslocadas um bloco para o passado. A implementação é fornecida abaixo, com a função prequential_validation.
Notebook Cell
def prequential_validation(transactions_df, classifier,
start_date_training,
delta_train=7,
delta_delay=7,
delta_assessment=7,
n_folds=4,
top_k_list=[100],
type_test="Test", parameter_summary=""):
performances_df_folds=pd.DataFrame()
start_time=time.time()
for fold in range(n_folds):
start_date_training_fold=start_date_training-datetime.timedelta(days=fold*delta_assessment)
# Get the training and test sets
(train_df, test_df)=get_train_test_set(transactions_df,
start_date_training=start_date_training_fold,
delta_train=delta_train,
delta_delay=delta_delay,
delta_test=delta_assessment)
# Fit model
model_and_predictions_dictionary = fit_model_and_get_predictions(classifier, train_df, test_df,
input_features, output_feature)
# Compute fraud detection performances
test_df['predictions']=model_and_predictions_dictionary['predictions_test']
performances_df_test=performance_assessment(test_df, top_k_list=top_k_list, rounded=False)
performances_df_test.columns=performances_df_test.columns.values+' '+type_test
train_df['predictions']=model_and_predictions_dictionary['predictions_train']
performances_df_train=performance_assessment(train_df, top_k_list=top_k_list, rounded=False)
performances_df_train.columns=performances_df_train.columns.values+' Train'
performances_df_folds=performances_df_folds.append(pd.concat([performances_df_test,performances_df_train],axis=1))
execution_time=time.time()-start_time
performances_df_folds_mean=performances_df_folds.mean()
performances_df_folds_std=performances_df_folds.std(ddof=0)
performances_df_folds_mean=pd.DataFrame(performances_df_folds_mean).transpose()
performances_df_folds_std=pd.DataFrame(performances_df_folds_std).transpose()
performances_df_folds_std.columns=performances_df_folds_std.columns.values+" Std"
performances_df=pd.concat([performances_df_folds_mean,performances_df_folds_std],axis=1)
performances_df['Execution time']=execution_time
performances_df['Parameters summary']=parameter_summary
return performances_df, performances_df_folds
Vamos, por exemplo, calcular o desempenho de validação com uma árvore de decisão de profundidade 2.
classifier = sklearn.tree.DecisionTreeClassifier(max_depth = 2, random_state=0)
performances_df_prequential_summary, performances_df_prequential_folds=prequential_validation(
transactions_df, classifier,
start_date_training=start_date_training_with_valid,
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_valid,
n_folds=4,
type_test="Validation", parameter_summary='2'
)Assim como com a função repeated_holdout_validation, a função prequential_validation retorna dois DataFrames:
performances_df_prequential_summary: Resumo das métricas de desempenho ao longo de todos os folds, em termos de média e variância padrão para cada métrica de desempenho.performances_df_prequential_folds: Métricas de desempenho obtidas em cada fold
performances_df_prequential_summaryperformances_df_prequential_foldsVamos então calcular os desempenhos esperados para diferentes profundidades de árvores de decisão, variando de .
list_params = [2,3,4,5,6,7,8,9,10,20,50]
start_time=time.time()
performances_df_prequential=pd.DataFrame()
for max_depth in list_params:
print("Computing performances for a decision tree with max_depth="+str(max_depth))
classifier = sklearn.tree.DecisionTreeClassifier(max_depth = max_depth, random_state=0)
performances_df_prequential=performances_df_prequential.append(
prequential_validation(
transactions_df, classifier,
start_date_training=start_date_training_with_valid,
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_test,
n_folds=4,
type_test="Validation", parameter_summary=max_depth
)[0]
)
performances_df_prequential.reset_index(inplace=True,drop=True)
print("Total execution time: "+str(round(time.time()-start_time,2))+"s")
Computing performances for a decision tree with max_depth=2
Computing performances for a decision tree with max_depth=3
Computing performances for a decision tree with max_depth=4
Computing performances for a decision tree with max_depth=5
Computing performances for a decision tree with max_depth=6
Computing performances for a decision tree with max_depth=7
Computing performances for a decision tree with max_depth=8
Computing performances for a decision tree with max_depth=9
Computing performances for a decision tree with max_depth=10
Computing performances for a decision tree with max_depth=20
Computing performances for a decision tree with max_depth=50
Total execution time: 52.82s
performances_df_prequentialVamos plotar os desempenhos de validação e teste em termos de AUC ROC, AP e CP@100, em função da profundidade da árvore de decisão.
performances_df_prequential['AUC ROC Test']=performances_df['AUC ROC Test']
performances_df_prequential['Average precision Test']=performances_df['Average precision Test']
performances_df_prequential['Card Precision@100 Test']=performances_df['Card Precision@100 Test']
get_performances_plots(performances_df_prequential,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'])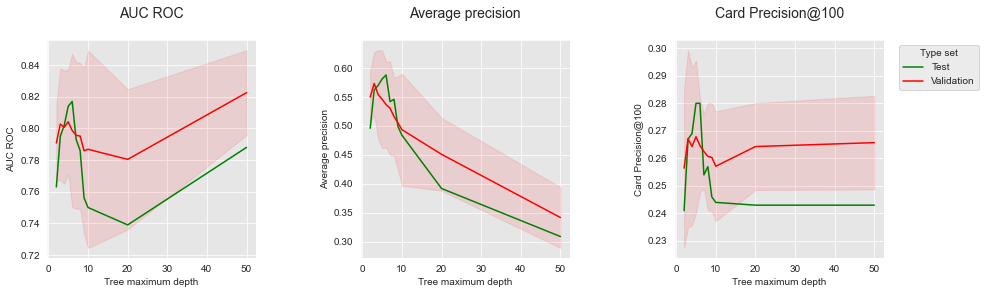
Podemos também calcular os desempenhos nas próximas n_folds semanas usando o mesmo código, mas definindo o dia de início do treinamento de forma que estimativas para o período de teste sejam obtidas. Isso permite fornecer intervalos de confiança para os desempenhos nos dados de teste.
list_params = [2,3,4,5,6,7,8,9,10,20,50]
start_time=time.time()
n_folds=4
performances_df_prequential_test=pd.DataFrame()
for max_depth in list_params:
classifier = sklearn.tree.DecisionTreeClassifier(max_depth = max_depth, random_state=0)
performances_df_prequential_test=performances_df_prequential_test.append(
prequential_validation(
transactions_df, classifier,
start_date_training=start_date_training
+datetime.timedelta(days=delta_test*(n_folds-1)),
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_test,
n_folds=n_folds,
type_test="Test", parameter_summary=max_depth
)[0]
)
performances_df_prequential_test.reset_index(inplace=True,drop=True)
print("Total execution time: "+str(round(time.time()-start_time,2))+"s")
Total execution time: 53.54s
performances_df_prequential_testVamos plotar as acurácias de validação e teste em termos de AUC ROC, AP e CP@100, em função da profundidade da árvore de decisão.
performances_df_prequential['AUC ROC Test']=performances_df_prequential_test['AUC ROC Test']
performances_df_prequential['Average precision Test']=performances_df_prequential_test['Average precision Test']
performances_df_prequential['Card Precision@100 Test']=performances_df_prequential_test['Card Precision@100 Test']
performances_df_prequential['AUC ROC Test Std']=performances_df_prequential_test['AUC ROC Test Std']
performances_df_prequential['Average precision Test Std']=performances_df_prequential_test['Average precision Test Std']
performances_df_prequential['Card Precision@100 Test Std']=performances_df_prequential_test['Card Precision@100 Test Std']
performances_df_prequentialget_performances_plots(performances_df_prequential,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'])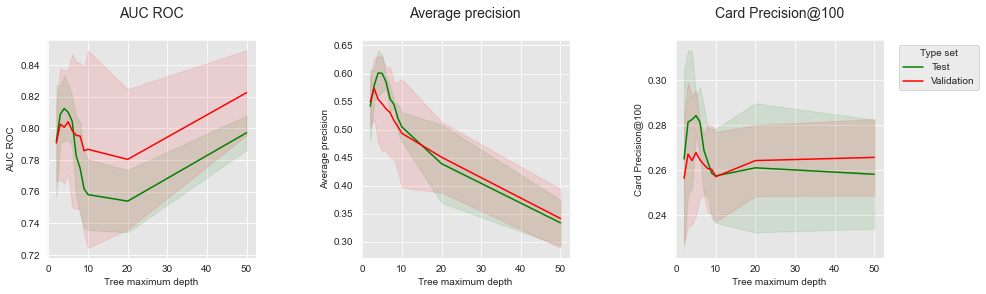
O gráfico resultante mostra uma melhor concordância entre os desempenhos de validação e teste para as três métricas de desempenho. O AUC ROC permanece problemático, pois selecionaria uma profundidade de 50 como melhor desempenho para o conjunto de validação, enquanto as profundidades ótimas estão na faixa de 3 a 6. O AP e o CP@100, no entanto, seguem tendências similares para os conjuntos de validação e teste.
A validação prequencial oferece a forma mais robusta de realizar seleção de modelos e será a abordagem preferida no restante deste livro. Deve-se notar, no entanto, que ela é computacionalmente intensiva, pois requer a criação de vários modelos de predição para cada parâmetro de modelo testado.
Integração no Scikit-learn¶
O Scikit-learn (também conhecido como sklearn) é a biblioteca de referência para aprendizado de máquina em Python. Como validação e seleção de modelos são etapas essenciais no design de modelos de predição de aprendizado de máquina, o sklearn fornece uma ampla gama de técnicas para avaliação e validação de modelos de predição.
O sklearn, no entanto, oferece poucas possibilidades para realizar validação em dados sequenciais. Em particular, a validação prequencial apresentada na seção anterior e a métrica de Precisão de Cartão não são fornecidas.
Esta última seção visa preencher essa lacuna, adicionando tanto a validação prequencial quanto a métrica CP aos pipelines de validação e seleção de modelos fornecidos pelo sklearn. Os benefícios serão ter acesso a funções de alto nível da biblioteca sklearn. Estes incluem, entre outros, a capacidade de
paralelizar facilmente a execução de código
depender de pipelines do sklearn para transformação de dados
depender de diferentes estratégias para ajuste de hiperparâmetros (busca exaustiva, busca aleatória, ...).
Divisão prequencial¶
O Scikit-learn fornece sete estratégias diferentes para dividir dados para validação: KFold, GroupKFold, ShuffleSplit, StratifiedKFold, GroupShuffleSplit, StratifiedShuffleSplit e TimeSeriesSplit. Uma visualização dessas estratégias de divisão é fornecida aqui. Nenhuma delas permite a divisão prequencial de dados ilustrada na Fig. 5.
Vamos definir uma função prequentialSplit, que retorna os índices dos conjuntos de treinamento e teste para cada um dos folds de uma divisão prequencial.
def prequentialSplit(transactions_df,
start_date_training,
n_folds=4,
delta_train=7,
delta_delay=7,
delta_assessment=7):
prequential_split_indices=[]
# For each fold
for fold in range(n_folds):
# Shift back start date for training by the fold index times the assessment period (delta_assessment)
# (See Fig. 5)
start_date_training_fold = start_date_training-datetime.timedelta(days=fold*delta_assessment)
# Get the training and test (assessment) sets
(train_df, test_df)=get_train_test_set(transactions_df,
start_date_training=start_date_training_fold,
delta_train=delta_train,delta_delay=delta_delay,delta_test=delta_assessment)
# Get the indices from the two sets, and add them to the list of prequential splits
indices_train=list(train_df.index)
indices_test=list(test_df.index)
prequential_split_indices.append((indices_train,indices_test))
return prequential_split_indicesPrecisão de Cartão top-k¶
Métricas personalizadas podem ser implementadas no sklearn graças à função de fábrica make_scorer. O cálculo da Precisão de Cartão top-k requer que a função de pontuação tenha acesso ao ID do cliente e ao dia da transação (ver Seção Métricas de Precisão Top K). Isso é feito passando o DataFrame transactions_df como argumento para a função. Mais detalhes sobre o design de funções de pontuação personalizadas podem ser encontrados aqui.
def card_precision_top_k_custom(y_true, y_pred, top_k, transactions_df):
# Let us create a predictions_df DataFrame, that contains all transactions matching the indices of the current fold
# (indices of the y_true vector)
predictions_df=transactions_df.iloc[y_true.index.values].copy()
predictions_df['predictions']=y_pred
# Compute the CP@k using the function implemented in Chapter 4, Section 4.2
nb_compromised_cards_per_day,card_precision_top_k_per_day_list,mean_card_precision_top_k=\
card_precision_top_k(predictions_df, top_k)
# Return the mean_card_precision_top_k
return mean_card_precision_top_k
# Only keep columns that are needed as argument to the custom scoring function
# (in order to reduce the serialization time of transaction dataset)
transactions_df_scorer=transactions_df[['CUSTOMER_ID', 'TX_FRAUD','TX_TIME_DAYS']]
# Make scorer using card_precision_top_k_custom
card_precision_top_100 = sklearn.metrics.make_scorer(card_precision_top_k_custom,
needs_proba=True,
top_k=100,
transactions_df=transactions_df_scorer)
Busca em grade¶
O sklearn permite automatizar o ajuste e a avaliação de modelos com diferentes hiperparâmetros por meio da função GridSearchCV.
Seus principais parâmetros são
estimator: O estimador a ser usado, que será uma árvore de decisão no exemplo a seguir.param_grid: O conjunto de hiperparâmetros para o estimador. Variaremos o parâmetro de profundidade da árvore de decisão (max_depth) e definiremos o estado aleatório (random_state) para reprodutibilidade.scoring: As funções de pontuação a serem usadas. Usaremos o AUC ROC, Precisão Média e CP@100.n_jobs: O número de núcleos a serem usados. Definiremos como -1, ou seja, usar todos os núcleos disponíveis.refit: Se o modelo deve ser ajustado com todos os dados após a validação cruzada. Isso será definido como falso, pois precisamos apenas dos resultados da validação cruzada.cv: A estratégia de divisão de validação cruzada. A validação prequencial será usada, passando os índices retornados pela funçãoprequentialSplit.
Vamos definir esses parâmetros e instanciar um objeto GridSearchCV.
# Estimator to use
classifier = sklearn.tree.DecisionTreeClassifier()
# Hyperparameters to test
parameters = {'clf__max_depth':[2,4], 'clf__random_state':[0]}
# Scoring functions. AUC ROC and Average Precision are readily available from sklearn
# with `auc_roc` and `average_precision`. Card Precision@100 was implemented with the make_scorer factory function.
scoring = {'roc_auc':'roc_auc',
'average_precision': 'average_precision',
'card_precision@100': card_precision_top_100
}
# A pipeline is created to scale data before fitting a model
estimators = [('scaler', sklearn.preprocessing.StandardScaler()), ('clf', classifier)]
pipe = sklearn.pipeline.Pipeline(estimators)
# Indices for the prequential validation are obtained with the prequentialSplit function
prequential_split_indices = prequentialSplit(transactions_df,
start_date_training_with_valid,
n_folds=n_folds,
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_valid)
# Let us instantiate the GridSearchCV
grid_search = sklearn.model_selection.GridSearchCV(pipe, param_grid=parameters, scoring=scoring, \
cv=prequential_split_indices, refit=False, n_jobs=-1,verbose=0)
# And select the input features, and output feature
X=transactions_df[input_features]
y=transactions_df[output_feature]
O ajuste e a avaliação são realizados chamando a função fit do objeto grid_search.
%time grid_search.fit(X, y)
print("Finished CV fitting")CPU times: user 152 ms, sys: 259 ms, total: 411 ms
Wall time: 6.51 s
Finished CV fitting
Os resultados da validação cruzada podem ser recuperados com o atributo cv_results_. Ele contém a pontuação para cada fold e métricas de pontuação, juntamente com estatísticas sobre os tempos de execução.
grid_search.cv_results_{'mean_fit_time': array([1.05854368, 1.27579147]),
'std_fit_time': array([0.0081484 , 0.01675179]),
'mean_score_time': array([0.29740781, 0.21103078]),
'std_score_time': array([0.00725061, 0.00444517]),
'param_clf__max_depth': masked_array(data=[2, 4],
mask=[False, False],
fill_value='?',
dtype=object),
'param_clf__random_state': masked_array(data=[0, 0],
mask=[False, False],
fill_value='?',
dtype=object),
'params': [{'clf__max_depth': 2, 'clf__random_state': 0},
{'clf__max_depth': 4, 'clf__random_state': 0}],
'split0_test_roc_auc': array([0.7750121 , 0.78393251]),
'split1_test_roc_auc': array([0.80873906, 0.82871798]),
'split2_test_roc_auc': array([0.79140481, 0.78643512]),
'split3_test_roc_auc': array([0.78798838, 0.80367453]),
'mean_test_roc_auc': array([0.79078609, 0.80069003]),
'std_test_roc_auc': array([0.01203472, 0.01787799]),
'rank_test_roc_auc': array([2, 1], dtype=int32),
'split0_test_average_precision': array([0.5235482 , 0.53514015]),
'split1_test_average_precision': array([0.58466274, 0.60015739]),
'split2_test_average_precision': array([0.54253116, 0.50175204]),
'split3_test_average_precision': array([0.5483265 , 0.57948508]),
'mean_test_average_precision': array([0.54976715, 0.55413367]),
'std_test_average_precision': array([0.02213352, 0.03829317]),
'rank_test_average_precision': array([2, 1], dtype=int32),
'split0_test_card_precision@100': array([0.24285714, 0.24857143]),
'split1_test_card_precision@100': array([0.24285714, 0.25714286]),
'split2_test_card_precision@100': array([0.26285714, 0.26428571]),
'split3_test_card_precision@100': array([0.27714286, 0.28714286]),
'mean_test_card_precision@100': array([0.25642857, 0.26428571]),
'std_test_card_precision@100': array([0.01448081, 0.01432138]),
'rank_test_card_precision@100': array([2, 1], dtype=int32)}Vamos reorganizar esses resultados em um formato mais legível:
performances_df=pd.DataFrame()
expe_type="Validation"
performance_metrics_list_grid=['roc_auc', 'average_precision', 'card_precision@100']
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100']
for i in range(len(performance_metrics_list_grid)):
performances_df[performance_metrics_list[i]+' '+expe_type]=grid_search.cv_results_['mean_test_'+performance_metrics_list_grid[i]]
performances_df[performance_metrics_list[i]+' '+expe_type+' Std']=grid_search.cv_results_['std_test_'+performance_metrics_list_grid[i]]
performances_df['Execution time']=grid_search.cv_results_['mean_fit_time']
performances_df['Parameters']=list(grid_search.cv_results_['params'])
performances_dfIntegração¶
Os mesmos resultados da seção anterior podem ser obtidos usando GridSearchCV. Vamos primeiro definir uma função prequential_grid_search, que implementa a busca em grade como acima:
def prequential_grid_search(transactions_df,
classifier,
input_features, output_feature,
parameters, scoring,
start_date_training,
n_folds=4,
expe_type='Test',
delta_train=7,
delta_delay=7,
delta_assessment=7,
performance_metrics_list_grid=['roc_auc'],
performance_metrics_list=['AUC ROC'],
n_jobs=-1):
estimators = [('scaler', sklearn.preprocessing.StandardScaler()), ('clf', classifier)]
pipe = sklearn.pipeline.Pipeline(estimators)
prequential_split_indices=prequentialSplit(transactions_df,
start_date_training=start_date_training,
n_folds=n_folds,
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment)
grid_search = sklearn.model_selection.GridSearchCV(pipe, parameters, scoring=scoring, cv=prequential_split_indices, refit=False, n_jobs=n_jobs)
X=transactions_df[input_features]
y=transactions_df[output_feature]
grid_search.fit(X, y)
performances_df=pd.DataFrame()
for i in range(len(performance_metrics_list_grid)):
performances_df[performance_metrics_list[i]+' '+expe_type]=grid_search.cv_results_['mean_test_'+performance_metrics_list_grid[i]]
performances_df[performance_metrics_list[i]+' '+expe_type+' Std']=grid_search.cv_results_['std_test_'+performance_metrics_list_grid[i]]
performances_df['Parameters']=grid_search.cv_results_['params']
performances_df['Execution time']=grid_search.cv_results_['mean_fit_time']
return performances_df
Podemos estimar os desempenhos de validação de um modelo de árvore de decisão para profundidades variadas definindo start_date_training como start_date_training_with_valid.
start_time=time.time()
classifier = sklearn.tree.DecisionTreeClassifier()
parameters = {'clf__max_depth':[2,3,4,5,6,7,8,9,10,20,50], 'clf__random_state':[0]}
scoring = {'roc_auc':'roc_auc',
'average_precision': 'average_precision',
'card_precision@100': card_precision_top_100,
}
performances_df_validation=prequential_grid_search(
transactions_df, classifier,
input_features, output_feature,
parameters, scoring,
start_date_training=start_date_training_with_valid,
n_folds=n_folds,
expe_type='Validation',
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_valid,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list)
print("Validation: Total execution time: "+str(round(time.time()-start_time,2))+"s")
Validation: Total execution time: 21.65s
E os desempenhos de teste definindo start_date_training de acordo.
start_time=time.time()
performances_df_test=prequential_grid_search(
transactions_df, classifier,
input_features, output_feature,
parameters, scoring,
start_date_training=start_date_training+datetime.timedelta(days=(n_folds-1)*delta_test),
n_folds=n_folds,
expe_type='Test',
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_test,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list)
print("Test: Total execution time: "+str(round(time.time()-start_time,2))+"s")
Test: Total execution time: 21.02s
Vamos concatenar os desempenhos de validação e teste em um único DataFrame.
performances_df_validation.drop(columns=['Parameters','Execution time'], inplace=True)
performances_df=pd.concat([performances_df_test,performances_df_validation],axis=1)# Use the max_depth as the label for plotting
parameters_dict=dict(performances_df['Parameters'])
max_depth=[parameters_dict[i]['clf__max_depth'] for i in range(len(parameters_dict))]
performances_df['Parameters summary']=max_depthperformances_dfVamos plotar os desempenhos para melhor visualização.
get_performances_plots(performances_df,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'],expe_type_color_list=['#008000','#FF0000'])Os resultados são os mesmos obtidos na Seção Validação Prequencial.
- Dal Pozzolo, A., Boracchi, G., Caelen, O., Alippi, C., & Bontempi, G. (2017). Credit card fraud detection: a realistic modeling and a novel learning strategy. IEEE Transactions on Neural Networks and Learning Systems, 29(8), 3784–3797.
- Dal Pozzolo, A. (2015). Adaptive machine learning for credit card fraud detection. Université libre de Bruxelles.
- Bontempi, G. (2021). Statistical foundations of machine learning, 2nd edition. Université Libre de Bruxelles.
- Bishop, C. M. (2006). Pattern recognition and machine learning. springer.
- Friedman, J., Hastie, T., & Tibshirani, R. (2001). The elements of statistical learning (Vol. 1). Springer series in statistics New York.
- Cerqueira, V., Torgo, L., & Mozetič, I. (2020). Evaluating time series forecasting models: an empirical study on performance estimation methods. Machine Learning, 109(11), 1997–2028.
- Gama, J., Žliobaitė, I., Bifet, A., Pechenizkiy, M., & Bouchachia, A. (2014). A survey on concept drift adaptation. ACM Computing Surveys (CSUR), 46(4), 1–37.