O objetivo de um modelo de predição é fornecer previsões precisas para dados novos, ou seja, dados que não foram utilizados no treinamento do modelo. Isso é chamado de capacidade de generalização de um modelo de predição. O desempenho preditivo esperado de um modelo de predição em novos dados é referido como desempenho de generalização ou desempenho de teste, e é o que deve ser maximizado.
O desempenho preditivo de um modelo de predição nos dados de treinamento, chamado desempenho de treinamento, é frequentemente um mau indicador do desempenho de generalização. Modelos de predição contêm hiperparâmetros que permitem ajustá-los de forma mais ou menos próxima aos dados de treinamento. Escolher hiperparâmetros que ajustem o modelo estreitamente aos dados de treinamento, por exemplo aumentando a expressividade, geralmente resulta em perda de desempenho de generalização, um fenômeno denominado sobreajuste. Isso foi observado, por exemplo, na Seção Desempenhos usando modelos de predição padrão, com árvores de decisão. Uma árvore de decisão com profundidade ilimitada foi capaz de detectar todas as fraudes no conjunto de treinamento, mas apresentou taxas de detecção de fraude muito baixas no conjunto de teste e uma taxa de detecção menor do que uma árvore de decisão de profundidade dois.
A abordagem padrão para avaliar a capacidade de generalização de um modelo de predição é um processo conhecido como validação. A validação consiste em dividir os dados históricos em dois conjuntos. O primeiro é utilizado para treinamento. O segundo, chamado conjunto de validação, é utilizado para avaliar (validar) a capacidade de generalização do modelo. O diagrama que resume a metodologia de validação, conforme apresentado no Capítulo 2 - Aprendizado de máquina para detecção de fraude em cartão de crédito, é reproduzido na Fig. 1.
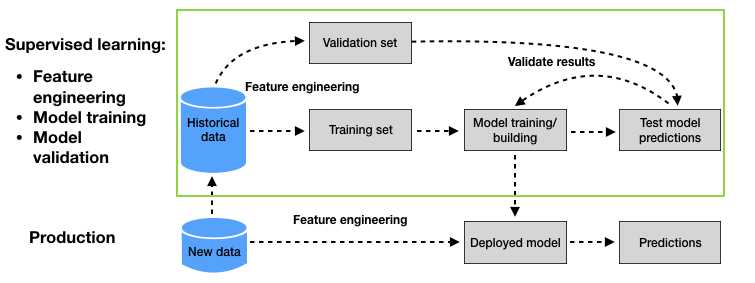
Fig. 1. Aprendizado de máquina para CCFD: Metodologia de linha de base. O processo de validação (parte superior, caixa verde) utiliza um conjunto de validação para estimar a capacidade de generalização de diferentes modelos de predição.
O processo de validação permite estimar a capacidade de generalização de diferentes modelos de predição por meio do conjunto de validação. O processo pode ser utilizado para comparar a capacidade de generalização com diferentes hiperparâmetros de modelo, classes de modelos ou técnicas de engenharia de características. O modelo que fornece a melhor capacidade de generalização estimada é eventualmente selecionado e implantado em produção.
Na detecção de fraude em cartão de crédito, o objetivo de um modelo de predição é, mais especificamente, fornecer previsões precisas para transações que ocorrerão no futuro. Devido à natureza sequencial dos dados de transação, cuidados especiais devem ser tomados ao dividir os dados em conjuntos de treinamento e validação. Em particular, as transações do conjunto de validação devem ocorrer após as transações do conjunto de treinamento.
Este capítulo explora as estratégias de validação que podem ser utilizadas para problemas de detecção de fraude. A Seção 5.2 cobre inicialmente três tipos de estratégias de validação conhecidas como hold-out, hold-out repetido e validação prequencial. A Seção 5.3 discute estratégias de seleção e otimização de modelos que podem ser utilizadas para explorar de forma mais eficiente o espaço de modelos concorrentes.