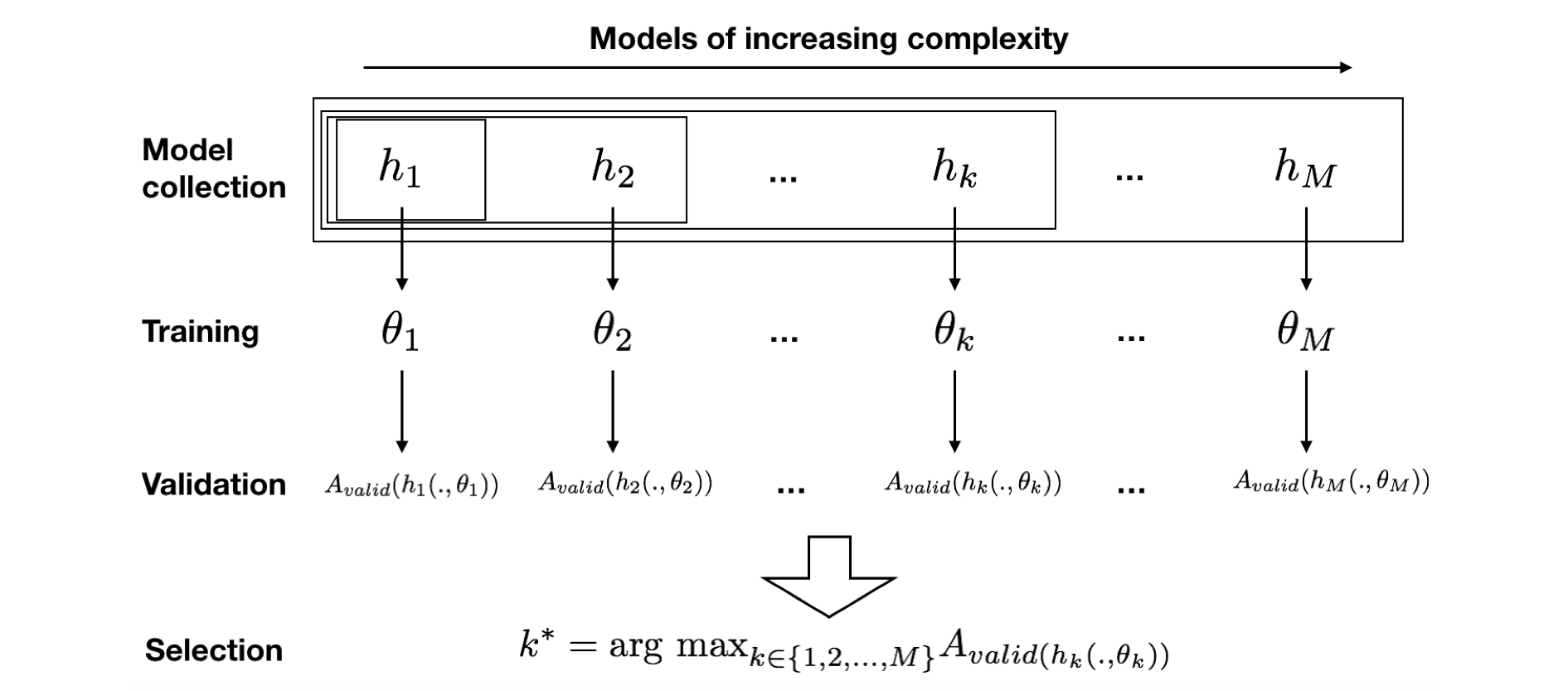
A seleção de modelos consiste em escolher o modelo de predição que se espera fornecer os melhores desempenhos em dados futuros. A metodologia padrão consiste em quatro etapas principais Bontempi (2021)Bishop (2006)Friedman et al. (2001):
Definir uma coleção de modelos candidatos a serem testados. Seja o número de modelos e , , o -ésimo modelo da coleção, parametrizado por um conjunto de parâmetros (ver também a seção Metodologia de linha de base - Aprendizado supervisionado). Dada uma classe de modelos (como árvores de decisão, regressão logística, ...), uma prática comum é definir uma coleção de modelos de complexidade crescente (profundidade da árvore para árvores de decisão, coeficientes de regularização para regressão logística, ...).
Treinar cada modelo candidato usando os dados de treinamento. O treinamento do modelo identifica os parâmetros que maximizam os desempenhos de no conjunto de treinamento.
Avaliar os desempenhos de cada modelo candidato por meio de um procedimento de validação (ver seção Estratégias de Validação). O procedimento de validação fornece uma estimativa do desempenho de generalização. Denotemos por o desempenho de validação para o -ésimo modelo.
Selecionar o modelo que tem o maior desempenho de validação. Denotando por o índice deste modelo ótimo, temos:
Uma ilustração do procedimento de seleção de modelos com suas diferentes etapas é fornecida na Fig. 1.
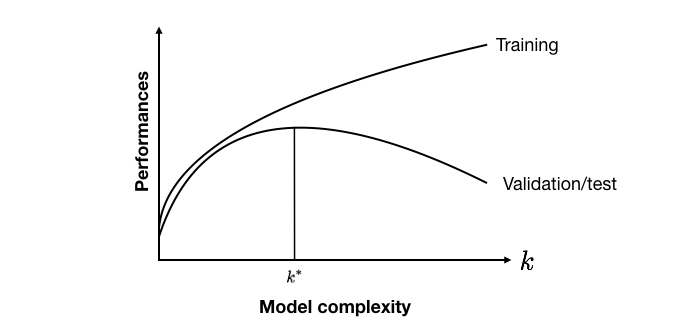
A justificativa para avaliar modelos de complexidade crescente é que geralmente há uma troca entre a complexidade do modelo e seus desempenhos de generalização (também chamada de trade-off viés/variância) Bontempi (2021)Bishop (2006)Friedman et al. (2001). Modelos com poucos parâmetros falham em representar adequadamente a relação entre características de entrada e saída (também chamado de subajuste). Modelos com muitos parâmetros podem representar perfeitamente a relação entre características de entrada e saída nos dados de treinamento (também chamado de sobreajuste). Os dados de treinamento são, no entanto, frequentemente ruidosos e sua distribuição ligeiramente diferente dos dados de validação e teste. Como resultado, o sobreajuste geralmente é prejudicial aos desempenhos nos dados de validação ou teste.
Uma representação qualitativa do trade-off entre complexidade do modelo e desempenhos é ilustrada na Fig. 2. Os desempenhos de treinamento geralmente aumentam com a complexidade do modelo. Os desempenhos ótimos de validação e teste são encontrados para modelos de complexidade intermediária, que evitam tanto o subajuste quanto o sobreajuste. Esse trade-off foi ilustrado experimentalmente com árvores de decisão na seção anterior sobre Estratégias de Validação.
Esta seção visa refinar o pipeline de validação do sklearn e explorar os trade-offs entre complexidade do modelo e desempenhos para diferentes classes de modelos.
Notebook Cell
# Initialization: Load shared functions and simulated data
# Load shared functions
!curl -O https://raw.githubusercontent.com/Fraud-Detection-Handbook/fraud-detection-handbook/main/Chapter_References/shared_functions.py
%run shared_functions.py
# Get simulated data from Github repository
if not os.path.exists("simulated-data-transformed"):
!git clone https://github.com/Fraud-Detection-Handbook/simulated-data-transformed
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 31568 100 31568 0 0 83513 0 --:--:-- --:--:-- --:--:-- 83513
Seleção de modelos: Árvores de decisão¶
Vamos primeiro reproduzir o pipeline de validação prequencial do sklearn proposto na seção anterior. Carregamos três meses de dados de transações e definimos a característica de saída como o rótulo de fraude TX_FRAUD, e as características de entrada como o conjunto de características obtidas a partir do pré-processamento de linha de base.
Notebook Cell
# Load data from the 2018-06-11 to the 2018-09-14
DIR_INPUT = 'simulated-data-transformed/data/'
BEGIN_DATE = "2018-06-11"
END_DATE = "2018-09-14"
print("Load files")
%time transactions_df = read_from_files(DIR_INPUT, BEGIN_DATE, END_DATE)
print("{0} transactions loaded, containing {1} fraudulent transactions".format(len(transactions_df),transactions_df.TX_FRAUD.sum()))
output_feature = "TX_FRAUD"
input_features = ['TX_AMOUNT','TX_DURING_WEEKEND', 'TX_DURING_NIGHT', 'CUSTOMER_ID_NB_TX_1DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_1DAY_WINDOW', 'CUSTOMER_ID_NB_TX_7DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_7DAY_WINDOW', 'CUSTOMER_ID_NB_TX_30DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_30DAY_WINDOW', 'TERMINAL_ID_NB_TX_1DAY_WINDOW',
'TERMINAL_ID_RISK_1DAY_WINDOW', 'TERMINAL_ID_NB_TX_7DAY_WINDOW',
'TERMINAL_ID_RISK_7DAY_WINDOW', 'TERMINAL_ID_NB_TX_30DAY_WINDOW',
'TERMINAL_ID_RISK_30DAY_WINDOW']
Load files
CPU times: user 880 ms, sys: 545 ms, total: 1.43 s
Wall time: 1.66 s
919767 transactions loaded, containing 8195 fraudulent transactions
A data de início de referência para treinamento é definida como 2018-07-25, e os deltas para sete dias (ver Estratégias de Validação).
Notebook Cell
# Number of folds for the prequential validation
n_folds = 4
# Set the starting day for the training period, and the deltas
start_date_training = datetime.datetime.strptime("2018-07-25", "%Y-%m-%d")
delta_train = delta_delay = delta_test = delta_valid = delta_assessment = 7
start_date_training_for_valid = start_date_training+datetime.timedelta(days=-(delta_delay+delta_valid))
start_date_training_for_test = start_date_training+datetime.timedelta(days=(n_folds-1)*delta_test)
As métricas de desempenho são o AUC ROC, a Precisão Média e a Precisão de Cartão@100.
Notebook Cell
# Only keep columns that are needed as argument to the custom scoring function
# (in order to reduce the serialization time of transaction dataset)
transactions_df_scorer = transactions_df[['CUSTOMER_ID', 'TX_FRAUD','TX_TIME_DAYS']]
card_precision_top_100 = sklearn.metrics.make_scorer(card_precision_top_k_custom,
needs_proba=True,
top_k=100,
transactions_df=transactions_df_scorer)
performance_metrics_list_grid = ['roc_auc', 'average_precision', 'card_precision@100']
performance_metrics_list = ['AUC ROC', 'Average precision', 'Card Precision@100']
scoring = {'roc_auc':'roc_auc',
'average_precision': 'average_precision',
'card_precision@100': card_precision_top_100,
}
Por questão de concisão, vamos definir uma função model_selection_wrapper, que realizará a validação prequencial tanto para os conjuntos de validação quanto de teste.
Notebook Cell
def model_selection_wrapper(transactions_df,
classifier,
input_features, output_feature,
parameters,
scoring,
start_date_training_for_valid,
start_date_training_for_test,
n_folds=4,
delta_train=7,
delta_delay=7,
delta_assessment=7,
performance_metrics_list_grid=['roc_auc'],
performance_metrics_list=['AUC ROC'],
n_jobs=-1):
# Get performances on the validation set using prequential validation
performances_df_validation=prequential_grid_search(transactions_df, classifier,
input_features, output_feature,
parameters, scoring,
start_date_training=start_date_training_for_valid,
n_folds=n_folds,
expe_type='Validation',
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list,
n_jobs=n_jobs)
# Get performances on the test set using prequential validation
performances_df_test=prequential_grid_search(transactions_df, classifier,
input_features, output_feature,
parameters, scoring,
start_date_training=start_date_training_for_test,
n_folds=n_folds,
expe_type='Test',
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list,
n_jobs=n_jobs)
# Bind the two resulting DataFrames
performances_df_validation.drop(columns=['Parameters','Execution time'], inplace=True)
performances_df=pd.concat([performances_df_test,performances_df_validation],axis=1)
# And return as a single DataFrame
return performances_df
A validação prequencial pode agora ser realizada com poucas linhas de código, ao:
definir qual classificador usar
definir quais parâmetros testar
ajustar os modelos e avaliar os desempenhos
A implementação usando árvores de decisão como modelos de predição, para profundidade máxima em , é obtida com:
# Define classifier
classifier = sklearn.tree.DecisionTreeClassifier()
# Set of parameters for which to assess model performances
parameters = {'clf__max_depth':[2,3,4,5,6,7,8,9,10,20,50], 'clf__random_state':[0]}
start_time = time.time()
# Fit models and assess performances for all parameters
performances_df=model_selection_wrapper(transactions_df, classifier,
input_features, output_feature,
parameters, scoring,
start_date_training_for_valid,
start_date_training_for_test,
n_folds=n_folds,
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list,
n_jobs=1)
execution_time_dt = time.time()-start_time
# Select parameter of interest (max_depth)
parameters_dict=dict(performances_df['Parameters'])
performances_df['Parameters summary']=[parameters_dict[i]['clf__max_depth'] for i in range(len(parameters_dict))]
# Rename to performances_df_dt for model performance comparison at the end of this notebook
performances_df_dt=performances_df
Notebook Cell
performances_df_dtO DataFrame resultante fornece os desempenhos em termos de AUC ROC, AP e CP@100 tanto para os conjuntos de validação quanto de teste. As linhas correspondem aos desempenhos para uma determinada profundidade máxima de uma árvore de decisão.
Vamos extrair desta tabela as informações mais relevantes, ou seja, entradas que permitem responder às seguintes perguntas:
Qual parâmetro fornece os melhores desempenhos no conjunto de validação?
Qual é o desempenho no conjunto de teste usando esse parâmetro?
Qual parâmetro teria fornecido o melhor desempenho no conjunto de teste?
As respostas a essas perguntas podem ser organizadas como uma tabela, usando a função get_summary_performances.
Notebook Cell
def get_summary_performances(performances_df, parameter_column_name="Parameters summary"):
# Three performance metrics
metrics = ['AUC ROC','Average precision','Card Precision@100']
performances_results=pd.DataFrame(columns=metrics)
# Reset indices in case a subset of a performane DataFrame is provided as input
performances_df.reset_index(drop=True,inplace=True)
# Lists of parameters/performances that will be retrieved for the best estimated parameters
best_estimated_parameters = []
validation_performance = []
test_performance = []
# For each performance metric, get the validation and test performance for the best estimated parameter
for metric in metrics:
# Find the index which provides the best validation performance
index_best_validation_performance = performances_df.index[np.argmax(performances_df[metric+' Validation'].values)]
# Retrieve the corresponding parameters
best_estimated_parameters.append(performances_df[parameter_column_name].iloc[index_best_validation_performance])
# Add validation performance to the validation_performance list (mean+/-std)
validation_performance.append(
str(round(performances_df[metric+' Validation'].iloc[index_best_validation_performance],3))+
'+/-'+
str(round(performances_df[metric+' Validation'+' Std'].iloc[index_best_validation_performance],2))
)
# Add test performance to the test_performance list (mean+/-std)
test_performance.append(
str(round(performances_df[metric+' Test'].iloc[index_best_validation_performance],3))+
'+/-'+
str(round(performances_df[metric+' Test'+' Std'].iloc[index_best_validation_performance],2))
)
# Add results to the performances_results DataFrame
performances_results.loc["Best estimated parameters"]=best_estimated_parameters
performances_results.loc["Validation performance"]=validation_performance
performances_results.loc["Test performance"]=test_performance
# Lists of parameters/performances that will be retrieved for the optimal parameters
optimal_test_performance = []
optimal_parameters = []
# For each performance metric, get the performance for the optimal parameter
for metric in ['AUC ROC Test','Average precision Test','Card Precision@100 Test']:
# Find the index which provides the optimal performance
index_optimal_test_performance = performances_df.index[np.argmax(performances_df[metric].values)]
# Retrieve the corresponding parameters
optimal_parameters.append(performances_df[parameter_column_name].iloc[index_optimal_test_performance])
# Add test performance to the test_performance list (mean+/-std)
optimal_test_performance.append(
str(round(performances_df[metric].iloc[index_optimal_test_performance],3))+
'+/-'+
str(round(performances_df[metric+' Std'].iloc[index_optimal_test_performance],2))
)
# Add results to the performances_results DataFrame
performances_results.loc["Optimal parameters"]=optimal_parameters
performances_results.loc["Optimal test performance"]=optimal_test_performance
return performances_results
summary_performances_dt=get_summary_performances(performances_df_dt, parameter_column_name="Parameters summary")
summary_performances_dtA primeira linha fornece os parâmetros que maximizam os desempenhos no conjunto de validação (melhores parâmetros estimados ). A segunda e a terceira linhas fornecem os desempenhos correspondentes nos conjuntos de validação e teste, respectivamente. A quarta linha fornece os parâmetros ótimos reais no conjunto de teste (os parâmetros que maximizam os desempenhos no conjunto de teste). A quinta linha fornece os desempenhos correspondentes no conjunto de teste.
Duas observações importantes podem ser feitas a partir desta tabela de resumo. Primeiro, o parâmetro ótimo depende das métricas de desempenho: é uma profundidade máxima de 4 para AUC ROC e AP, enquanto é uma profundidade máxima de 5 para o CP@100. Segundo, os melhores parâmetros para a validação podem não ser o parâmetro ótimo para o conjunto de teste. Este é o caso para o AUC ROC (profundidade máxima de 50 para o conjunto de validação versus 4 para o conjunto de teste) e o AP (profundidade máxima de 3 para o conjunto de validação versus 4 para o conjunto de teste).
Semelhante à seção Estratégias de Validação, vamos plotar os desempenhos em função da profundidade da árvore de decisão. A linha tracejada vertical é a profundidade da árvore para a qual o desempenho é maximizado nos dados de validação.
get_performances_plots(performances_df_dt,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
summary_performances=summary_performances_dt)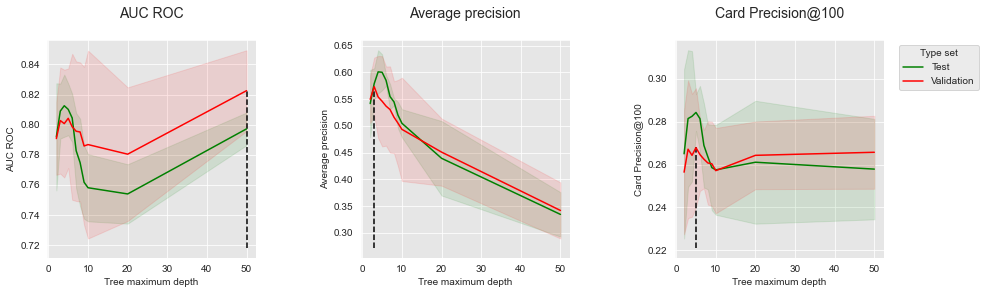
Seleção de modelos: Exploração de outras classes de modelos¶
Esta seção explora os desempenhos que podem ser alcançados com a seleção de modelos usando outras classes de modelos. Cobrimos regressão logística, florestas aleatórias e boosting (como na seção Sistema de Detecção de Fraude de Linha de Base).
Regressão logística¶
O principal hiperparâmetro da regressão logística é o parâmetro de regularização C. O valor padrão para este parâmetro é 1. Vamos tentar ajustar modelos com valores menores e maiores, por exemplo no conjunto [0.1,1,10,100].
classifier = sklearn.linear_model.LogisticRegression()
parameters = {'clf__C':[0.1,1,10,100], 'clf__random_state':[0]}
start_time=time.time()
performances_df=model_selection_wrapper(transactions_df, classifier,
input_features, output_feature,
parameters, scoring,
start_date_training_for_valid,
start_date_training_for_test,
n_folds=n_folds,
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list,
n_jobs=1)
execution_time_lr = time.time()-start_time
parameters_dict=dict(performances_df['Parameters'])
performances_df['Parameters summary']=[parameters_dict[i]['clf__C'] for i in range(len(parameters_dict))]
# Rename to performances_df_lr for model performance comparison at the end of this notebook
performances_df_lr=performances_dfNotebook Cell
performances_df_lrA função get_summary_performances fornece o resumo dos melhores parâmetros e os desempenhos correspondentes.
summary_performances_lr=get_summary_performances(performances_df_lr, parameter_column_name="Parameters summary")
summary_performances_lrVamos plotar os desempenhos em função do valor de regularização, juntamente com o valor que fornece os melhores desempenhos estimados.
get_performances_plots(performances_df_lr,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="Regularization value",
summary_performances=summary_performances_lr)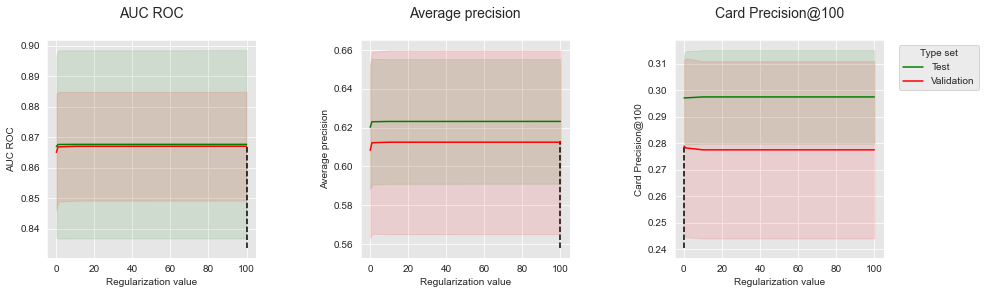
Os desempenhos tendem a ser um pouco menores para um valor baixo de (0,1). Valores de iguais ou maiores que um fornecem desempenhos similares. O parâmetro padrão parece, portanto, ser um valor sensato para o modelo de regressão logística.
Floresta aleatória¶
Os dois principais hiperparâmetros de uma floresta aleatória são a profundidade máxima da árvore e o número de árvores (parâmetros max_depth e n_estimators, respectivamente). Por padrão, a profundidade máxima da árvore é None (ou seja, os nós são expandidos até que todas as folhas sejam puras ou até que todas as folhas contenham menos de min_samples_split amostras), e o número de árvores é 100. Vamos tentar outros valores, combinando valores de max_depth no conjunto [5,10,20,50] e valores de n_estimators no conjunto [25,50,100].
classifier = sklearn.ensemble.RandomForestClassifier()
# Note: n_jobs set to one for getting true execution times
parameters = {'clf__max_depth':[5,10,20,50], 'clf__n_estimators':[25,50,100],
'clf__random_state':[0],'clf__n_jobs':[1]}
start_time=time.time()
performances_df=model_selection_wrapper(transactions_df, classifier,
input_features, output_feature,
parameters, scoring,
start_date_training_for_valid,
start_date_training_for_test,
n_folds=n_folds,
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list,
n_jobs=1)
execution_time_rf = time.time()-start_time
parameters_dict=dict(performances_df['Parameters'])
performances_df['Parameters summary']=[str(parameters_dict[i]['clf__n_estimators'])+
'/'+
str(parameters_dict[i]['clf__max_depth'])
for i in range(len(parameters_dict))]
# Rename to performances_df_rf for model performance comparison at the end of this notebook
performances_df_rf=performances_df
Notebook Cell
performances_df_rfA função get_summary_performances fornece o resumo dos melhores parâmetros e os desempenhos correspondentes.
summary_performances_rf=get_summary_performances(performances_df_rf, parameter_column_name="Parameters summary")
summary_performances_rfOs melhores desempenhos são obtidos com florestas contendo 100 árvores, com uma profundidade máxima de 10 ou 20. Os parâmetros ótimos diferem dos melhores parâmetros estimados para o AUC e CP@100. A diferença em termos de desempenhos é, no entanto, baixa, e os melhores parâmetros estimados podem ser considerados próximos dos ótimos.
A visualização dos desempenhos em função dos parâmetros do modelo é mais complicada, pois dois parâmetros são variados. Vamos primeiro fixar o número de árvores e depois variar a profundidade máxima da árvore.
Fixando o número de árvores em 100, obtemos:
performances_df_rf_fixed_number_of_trees=performances_df_rf[performances_df_rf["Parameters summary"].str.startswith("100")]
summary_performances_fixed_number_of_trees=get_summary_performances(performances_df_rf_fixed_number_of_trees, parameter_column_name="Parameters summary")
get_performances_plots(performances_df_rf_fixed_number_of_trees,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="Number of trees/Maximum tree depth",
summary_performances=summary_performances_fixed_number_of_trees)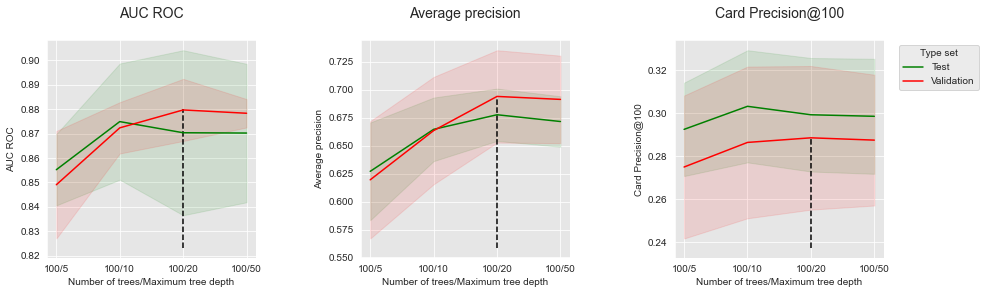
Uma profundidade máxima de 5 fornece os menores desempenhos. Os desempenhos aumentam com a profundidade máxima, até uma profundidade de 10 a 20 onde atingem um platô e depois diminuem ligeiramente.
Vamos então fixar a profundidade máxima da árvore e variar o número de estimadores. Fixando a profundidade máxima em 20, obtemos:
performances_df_rf_fixed_max_tree_depth=performances_df_rf[performances_df_rf["Parameters summary"].str.endswith("20")]
summary_performances_fixed_max_tree_depth=get_summary_performances(performances_df_rf_fixed_max_tree_depth, parameter_column_name="Parameters summary")
get_performances_plots(performances_df_rf_fixed_max_tree_depth,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="Number of trees/Maximum tree depth",
summary_performances=summary_performances_fixed_max_tree_depth)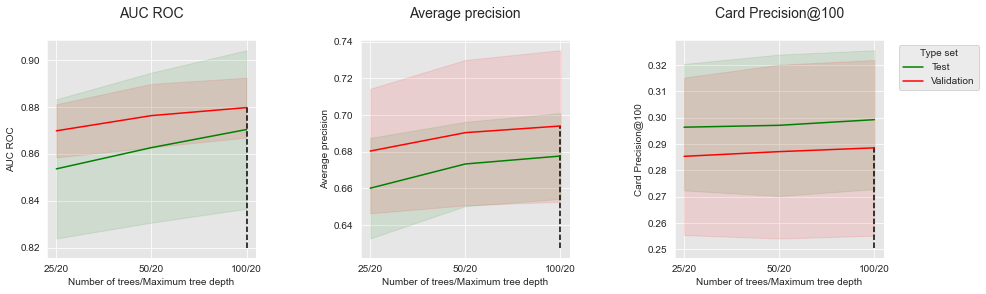
Para todas as métricas de desempenho, a tendência comum é um aumento nos desempenhos à medida que o número de árvores aumenta. Os ganhos de desempenho adicionais, no entanto, diminuem com o número de árvores adicionadas.
Vale notar que os tempos de execução para treinar florestas aleatórias aumentam linearmente com o número de árvores. Isso pode ser ilustrado plotando os tempos de execução em função do número de árvores.
Notebook Cell
# Get the performance plot for a single performance metric
def get_execution_times_plot(performances_df,
title="",
parameter_name="Tree maximum depth"):
fig, ax = plt.subplots(1,1, figsize=(5,4))
# Plot data on graph
ax.plot(performances_df['Parameters summary'], performances_df["Execution time"],
color="black")
# Set title, and x and y axes labels
ax.set_title(title, fontsize=14)
ax.set(xlabel = parameter_name, ylabel="Execution time (seconds)")get_execution_times_plot(performances_df_rf_fixed_max_tree_depth,
title="Execution times with varying \n number of trees",
parameter_name="Number of trees/Maximum tree depth")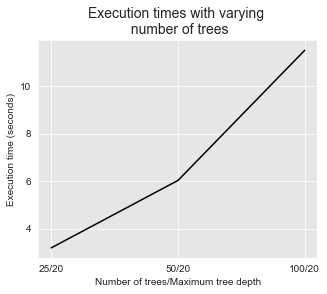
Os tempos de execução também aumentam com a profundidade máxima da árvore, como ilustrado abaixo.
get_execution_times_plot(performances_df_rf_fixed_number_of_trees,
title="Execution times with varying \n maximum tree depth",
parameter_name="Number of trees/Maximum tree depth")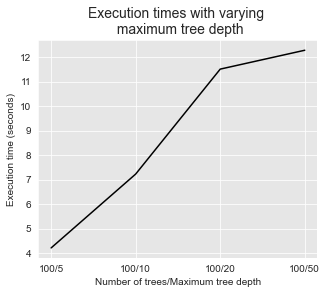
No total, o procedimento de seleção de modelos acima levou cerca de 10 minutos para ser concluído em um único núcleo, embora apenas um pequeno número de combinações de parâmetros tenham sido testadas (12 no total: 4 parâmetros diferentes para a profundidade máxima da árvore, e 3 parâmetros diferentes para o número de árvores).
print("Total execution time for the model selection procedure: "+str(round(execution_time_rf,2))+"s")Total execution time for the model selection procedure: 586.96s
Este exemplo ilustra o trade-off entre desempenho e tempo de computação na busca por parâmetros ótimos. Os recursos computacionais são geralmente limitados, e deve-se considerar cuidadosamente quais combinações de hiperparâmetros podem ser testadas dado os recursos disponíveis.
XGBoost¶
O XGBoost é um poderoso algoritmo de aprendizado cujo ajuste, no entanto, depende de muitos hiperparâmetros. Os mais importantes são, sem dúvida, a profundidade máxima da árvore (max_depth), o número de árvores (n_estimators) e a taxa de aprendizado (learning_rate). Por padrão, a profundidade máxima da árvore é definida como 6, o número de árvores como 100 e a taxa de aprendizado como 0,3. Vamos tentar outras combinações, com max_depth no conjunto [3,6,9], n_estimators no conjunto [25,10,100] e learning_rate no conjunto [0.1, 0.3].
classifier = xgboost.XGBClassifier()
parameters = {'clf__max_depth':[3,6,9], 'clf__n_estimators':[25,50,100], 'clf__learning_rate':[0.1, 0.3],
'clf__random_state':[0], 'clf__n_jobs':[1], 'clf__verbosity':[0]}
start_time=time.time()
performances_df=model_selection_wrapper(transactions_df, classifier,
input_features, output_feature,
parameters, scoring,
start_date_training_for_valid,
start_date_training_for_test,
n_folds=n_folds,
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list,
n_jobs=1)
execution_time_boosting = time.time()-start_time
parameters_dict=dict(performances_df['Parameters'])
performances_df['Parameters summary']=[str(parameters_dict[i]['clf__n_estimators'])+
'/'+
str(parameters_dict[i]['clf__learning_rate'])+
'/'+
str(parameters_dict[i]['clf__max_depth'])
for i in range(len(parameters_dict))]
# Rename to performances_df_xgboost for model performance comparison at the end of this notebook
performances_df_xgboost=performances_dfNotebook Cell
performances_df_xgboostA função get_summary_performances fornece o resumo dos melhores parâmetros e os desempenhos correspondentes.
summary_performances_xgboost=get_summary_performances(performances_df_xgboost, parameter_column_name="Parameters summary")
summary_performances_xgboostOs melhores parâmetros obtidos pela validação são os mesmos para AUC ROC, e diferem ligeiramente para a precisão média e CP@100. Os desempenhos de teste correspondentes são, no entanto, equivalentes.
Vamos plotar os desempenhos em função da profundidade máxima da árvore, para um número de árvores definido como 100. Aumentar a profundidade máxima da árvore não afeta claramente os desempenhos. Aumenta ligeiramente os desempenhos para AUC ROC e AP, mas os diminui ligeiramente para CP@100.
performances_df_xgboost_fixed_number_of_trees=performances_df_xgboost[performances_df_xgboost["Parameters summary"].str.startswith("100/0.3")]
summary_performances_fixed_number_of_trees=get_summary_performances(performances_df_xgboost_fixed_number_of_trees, parameter_column_name="Parameters summary")
get_performances_plots(performances_df_xgboost_fixed_number_of_trees,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="Number of trees/Maximum tree depth",
summary_performances=summary_performances_fixed_number_of_trees)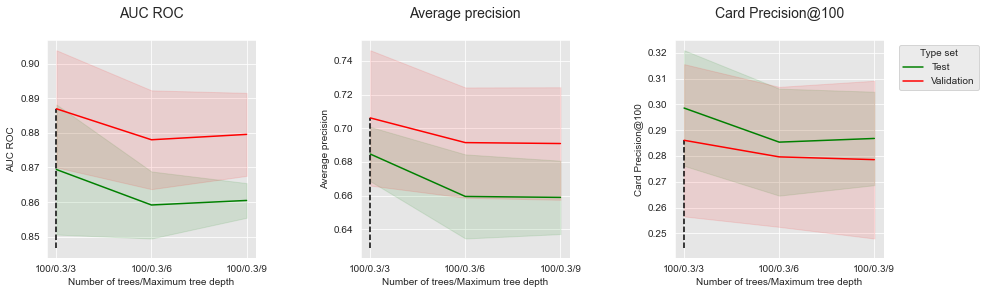
Vamos então plotar os desempenhos em função do número de árvores, para uma profundidade máxima de árvore definida como 5.
performances_df_xgboost_fixed_max_tree_depth=performances_df_xgboost[performances_df_xgboost["Parameters summary"].str.endswith("0.3/3")]
summary_performances_fixed_max_tree_depth=get_summary_performances(performances_df_xgboost_fixed_max_tree_depth, parameter_column_name="Parameters summary")
get_performances_plots(performances_df_xgboost_fixed_max_tree_depth,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="Number of trees/Maximum tree depth",
summary_performances=summary_performances_fixed_max_tree_depth)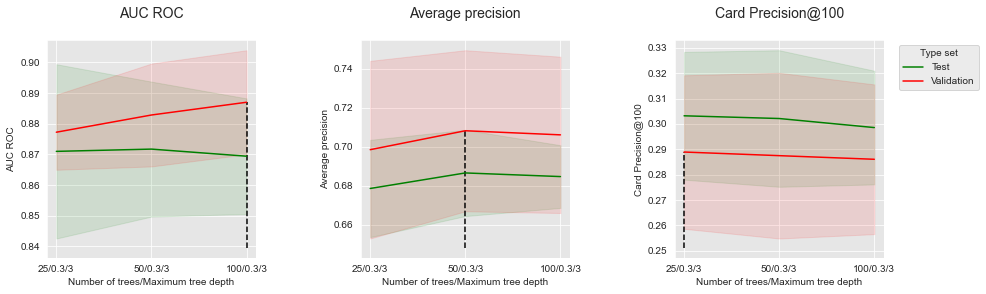
Aumentar o número de árvores de 25 para 50 permite aumentar os desempenhos para todas as métricas de desempenho. Adicionar mais árvores, no entanto, fornece apenas desempenhos ligeiramente maiores para AUC ROC e AP, e diminui ligeiramente os desempenhos para CP@100.
Semelhante às florestas aleatórias, aumentar a profundidade máxima da árvore e o número de árvores tem um custo em termos de tempos de execução. Isso é ilustrado nas duas figuras abaixo.
get_execution_times_plot(performances_df_xgboost_fixed_max_tree_depth,
title="Execution times with varying \n number of trees",
parameter_name="Number of trees/Learning rate/Maximum tree depth")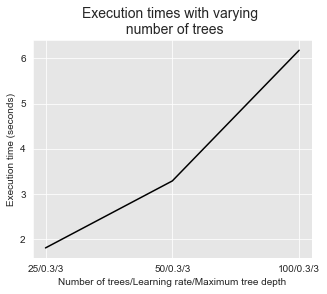
get_execution_times_plot(performances_df_xgboost_fixed_number_of_trees,
title="Execution times with varying \n maximum tree depth",
parameter_name="Number of trees/Learning rate/Maximum tree depth")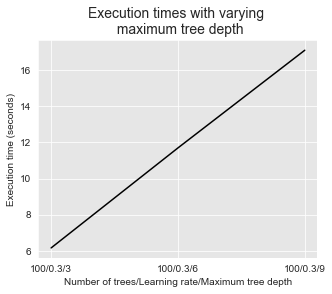
O tempo total de execução foi de mais de 10 minutos usando um único núcleo.
print("Total execution time for the model selection procedure: "+str(round(execution_time_boosting,2))+"s")Total execution time for the model selection procedure: 1251.2s
Comparação de desempenhos de modelos¶
A seção anterior detalhou os desempenhos de diferentes classes de modelos. Vamos comparar esses desempenhos para determinar qual classe de modelo fornece os melhores desempenhos.
Para cada classe de modelo, vamos recuperar o desempenho para três tipos de parâmetros:
Parâmetros padrão: Parâmetros padrão que o
sklearnfornece a uma classe de modelo. Os parâmetros padrão para cada classe de modelo são:Árvore de decisão:
max_depth=None.Regressão logística:
C=1.Floresta aleatória:
n_estimators=100,max_depth=None.XGBoost:
n_estimators=100,max_depth=6,learning_rate=0.3.
Melhores parâmetros estimados: Parâmetros que fornecem os maiores desempenhos no conjunto de validação.
Parâmetros ótimos: Parâmetros que fornecem os maiores desempenhos no conjunto de teste.
A função model_selection_performances abaixo recebe um dicionário de DataFrames de desempenho e uma métrica de desempenho, e recupera os desempenhos correspondentes (média juntamente com o desvio padrão).
performances_df_dictionary={
"Decision Tree": performances_df_dt,
"Logistic Regression": performances_df_lr,
"Random Forest": performances_df_rf,
"XGBoost": performances_df_xgboost
}Notebook Cell
def model_selection_performances(performances_df_dictionary,
performance_metric='AUC ROC',
model_classes=['Decision Tree',
'Logistic Regression',
'Random Forest',
'XGBoost'],
default_parameters_dictionary={
"Decision Tree": 50,
"Logistic Regression": 1,
"Random Forest": "100/50",
"XGBoost": "100/0.3/6"
}):
mean_performances_dictionary={
"Default parameters": [],
"Best validation parameters": [],
"Optimal parameters": []
}
std_performances_dictionary={
"Default parameters": [],
"Best validation parameters": [],
"Optimal parameters": []
}
# For each model class
for model_class in model_classes:
performances_df=performances_df_dictionary[model_class]
# Get the performances for the default paramaters
default_performances=performances_df[performances_df['Parameters summary']==default_parameters_dictionary[model_class]]
default_performances=default_performances.round(decimals=3)
mean_performances_dictionary["Default parameters"].append(default_performances[performance_metric+" Test"].values[0])
std_performances_dictionary["Default parameters"].append(default_performances[performance_metric+" Test Std"].values[0])
# Get the performances for the best estimated parameters
performances_summary=get_summary_performances(performances_df, parameter_column_name="Parameters summary")
mean_std_performances=performances_summary.loc[["Test performance"]][performance_metric].values[0]
mean_std_performances=mean_std_performances.split("+/-")
mean_performances_dictionary["Best validation parameters"].append(float(mean_std_performances[0]))
std_performances_dictionary["Best validation parameters"].append(float(mean_std_performances[1]))
# Get the performances for the boptimal parameters
mean_std_performances=performances_summary.loc[["Optimal test performance"]][performance_metric].values[0]
mean_std_performances=mean_std_performances.split("+/-")
mean_performances_dictionary["Optimal parameters"].append(float(mean_std_performances[0]))
std_performances_dictionary["Optimal parameters"].append(float(mean_std_performances[1]))
# Return the mean performances and their standard deviations
return (mean_performances_dictionary,std_performances_dictionary)Por exemplo, executar a função para a métrica AUC ROC retorna:
model_selection_performances(performances_df_dictionary,
performance_metric='AUC ROC')({'Default parameters': [0.797, 0.868, 0.87, 0.859],
'Best validation parameters': [0.797, 0.868, 0.87, 0.869],
'Optimal parameters': [0.813, 0.868, 0.875, 0.872]},
{'Default parameters': [0.005, 0.015, 0.014, 0.005],
'Best validation parameters': [0.01, 0.02, 0.02, 0.01],
'Optimal parameters': [0.01, 0.02, 0.01, 0.01]})Para melhor visualização, vamos plotar os desempenhos para as quatro classes de modelos e para cada métrica de desempenho como gráficos de barras. A implementação é fornecida com as funções get_model_selection_performance_plot e get_model_selection_performances_plots abaixo.
Notebook Cell
# Get the performance plot for a single performance metric
def get_model_selection_performance_plot(performances_df_dictionary,
ax,
performance_metric,
ylim=[0,1],
model_classes=['Decision Tree',
'Logistic Regression',
'Random Forest',
'XGBoost']):
(mean_performances_dictionary,std_performances_dictionary) = \
model_selection_performances(performances_df_dictionary=performances_df_dictionary,
performance_metric=performance_metric)
# width of the bars
barWidth = 0.3
# The x position of bars
r1 = np.arange(len(model_classes))
r2 = r1+barWidth
r3 = r1+2*barWidth
# Create Default parameters bars (Orange)
ax.bar(r1, mean_performances_dictionary['Default parameters'],
width = barWidth, color = '#CA8035', edgecolor = 'black',
yerr=std_performances_dictionary['Default parameters'], capsize=7, label='Default parameters')
# Create Best validation parameters bars (Red)
ax.bar(r2, mean_performances_dictionary['Best validation parameters'],
width = barWidth, color = '#008000', edgecolor = 'black',
yerr=std_performances_dictionary['Best validation parameters'], capsize=7, label='Best validation parameters')
# Create Optimal parameters bars (Green)
ax.bar(r3, mean_performances_dictionary['Optimal parameters'],
width = barWidth, color = '#2F4D7E', edgecolor = 'black',
yerr=std_performances_dictionary['Optimal parameters'], capsize=7, label='Optimal parameters')
# Set title, and x and y axes labels
ax.set_ylim(ylim[0],ylim[1])
ax.set_xticks(r2+barWidth/2)
ax.set_xticklabels(model_classes, rotation = 45, ha="right", fontsize=12)
ax.set_title(performance_metric+'\n', fontsize=18)
ax.set_xlabel("Model class", fontsize=16)
ax.set_ylabel(performance_metric, fontsize=15)Notebook Cell
def get_model_selection_performances_plots(performances_df_dictionary,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
ylim_list=[[0.6,0.9],[0.2,0.8],[0.2,0.35]],
model_classes=['Decision Tree',
'Logistic Regression',
'Random Forest',
'XGBoost']):
# Create as many graphs as there are performance metrics to display
n_performance_metrics = len(performance_metrics_list)
fig, ax = plt.subplots(1, n_performance_metrics, figsize=(5*n_performance_metrics,4))
parameter_types=['Default parameters','Best validation parameters','Optimal parameters']
# Plot performance metric for each metric in performance_metrics_list
for i in range(n_performance_metrics):
get_model_selection_performance_plot(performances_df_dictionary,
ax[i],
performance_metrics_list[i],
ylim=ylim_list[i],
model_classes=model_classes
)
ax[n_performance_metrics-1].legend(loc='upper left',
labels=parameter_types,
bbox_to_anchor=(1.05, 1),
title="Parameter type",
prop={'size': 12},
title_fontsize=12)
plt.subplots_adjust(wspace=0.5,
hspace=0.8)Isso fornece:
get_model_selection_performances_plots(performances_df_dictionary,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'])
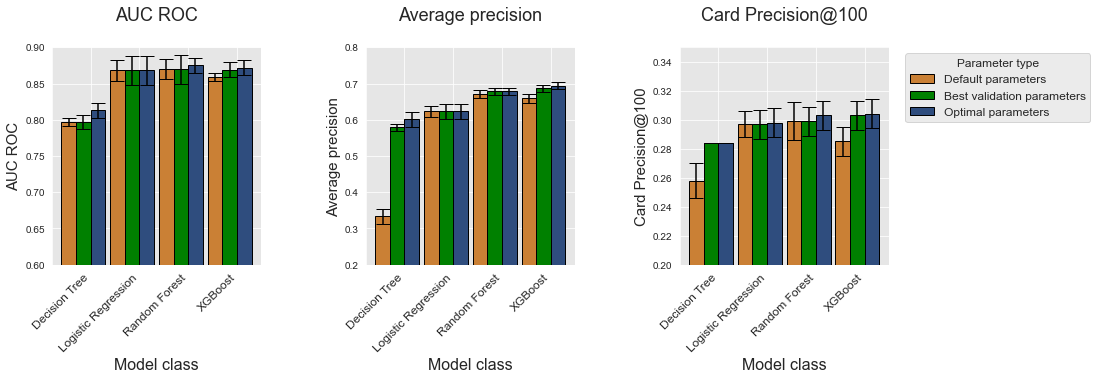
Neste conjunto de dados simulado, o XGBoost fornece os maiores desempenhos em termos de Precisão Média e CP@100, seguido pela floresta aleatória, regressão logística e, por fim, pelas árvores de decisão que têm os menores desempenhos. A diferença em termos de desempenho é mais visível com a métrica de precisão média. Os desempenhos de regressão logística, floresta aleatória e XGBoost são muito similares em termos de AUC ROC.
Vamos plotar os tempos totais de execução do procedimento de seleção de modelos para cada classe de modelo.
execution_times=[execution_time_dt,execution_time_lr,
execution_time_rf,execution_time_boosting]
Notebook Cell
%%capture
fig_model_selection_execution_times_for_each_model_class, ax = plt.subplots(1, 1, figsize=(5,4))
model_classes=['Decision Tree','Logistic Regression','Random Forest','XGBoost']
# width of the bars
barWidth = 0.3
# The x position of bars
r1 = np.arange(len(model_classes))
# Create execution times bars
ax.bar(r1, execution_times[0:4],
width = barWidth, color = 'black', edgecolor = 'black',
capsize=7)
ax.set_xticks(r1+barWidth/2)
ax.set_xticklabels(model_classes, rotation = 45, ha="right", fontsize=12)
ax.set_title('Model selection execution times \n for different model classes', fontsize=18)
ax.set_xlabel("Model class", fontsize=16)
ax.set_ylabel("Execution times (s)", fontsize=15)
fig_model_selection_execution_times_for_each_model_class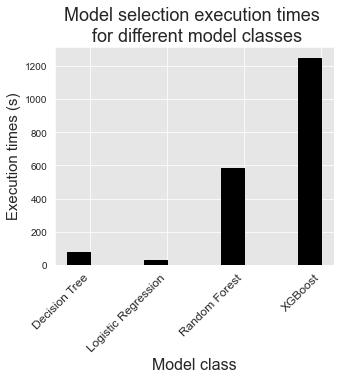
A comparação em termos de tempos de execução é principalmente qualitativa, pois depende em grande medida do número de combinações de parâmetros consideradas no procedimento de seleção de modelos. No entanto, ilustra que a seleção de modelos para modelos complexos como florestas aleatórias ou boosting geralmente requer mais recursos computacionais, pois requerem o ajuste de um número maior de hiperparâmetros.
Busca aleatória¶
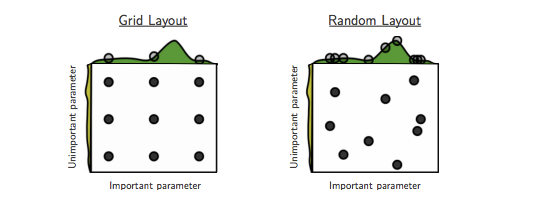
A busca em grade é uma estratégia amplamente usada para otimização de hiperparâmetros. No entanto, ela rapidamente se torna intratável quando o número de hiperparâmetros é alto, pois o número de combinações de parâmetros cresce exponencialmente com o número de parâmetros.
Uma alternativa à busca em grade é a busca aleatória, onde combinações aleatórias de parâmetros são avaliadas para um número fixo de combinações. Além de permitir limitar o número de combinações de parâmetros testadas, as combinações aleatórias foram demonstradas empiricamente e teoricamente como mais eficientes para otimização de hiperparâmetros do que a busca em grade Bergstra & Bengio (2012).
A intuição para a eficiência da busca aleatória é ilustrada na Fig. 3. Essencialmente, a busca aleatória permite explorar mais eficientemente o espaço de hiperparâmetros importantes.
A implementação da busca aleatória no sklearn pode ser realizada usando RandomizedSearchCV em vez de GridSearchCV na busca prequencial. Vamos modificar o prequential_grid_search para uma função prequential_parameters_search mais genérica, adicionando três novos parâmetros:
type_search: ‘grid’ para busca em grade ou ‘random’ para busca aleatória.n_iter: Número de iterações (combinações de parâmetros) para a busca aleatória.random_state: Estado aleatório para reprodutibilidade da busca aleatória.
Notebook Cell
def prequential_parameters_search(transactions_df,
classifier,
input_features, output_feature,
parameters, scoring,
start_date_training,
n_folds=4,
expe_type='Test',
delta_train=7,
delta_delay=7,
delta_assessment=7,
performance_metrics_list_grid=['roc_auc'],
performance_metrics_list=['AUC ROC'],
type_search='grid',
n_iter=10,
random_state=0,
n_jobs=-1):
estimators = [('scaler', sklearn.preprocessing.StandardScaler()), ('clf', classifier)]
pipe = sklearn.pipeline.Pipeline(estimators)
prequential_split_indices=prequentialSplit(transactions_df,
start_date_training=start_date_training,
n_folds=n_folds,
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment)
parameters_search = None
if type_search=="grid":
parameters_search = sklearn.model_selection.GridSearchCV(pipe, parameters, scoring=scoring, cv=prequential_split_indices,
refit=False, n_jobs=n_jobs)
if type_search=="random":
parameters_search = sklearn.model_selection.RandomizedSearchCV(pipe, parameters, scoring=scoring, cv=prequential_split_indices,
refit=False, n_jobs=n_jobs,n_iter=n_iter,random_state=random_state)
X=transactions_df[input_features]
y=transactions_df[output_feature]
parameters_search.fit(X, y)
performances_df=pd.DataFrame()
for i in range(len(performance_metrics_list_grid)):
performances_df[performance_metrics_list[i]+' '+expe_type]=parameters_search.cv_results_['mean_test_'+performance_metrics_list_grid[i]]
performances_df[performance_metrics_list[i]+' '+expe_type+' Std']=parameters_search.cv_results_['std_test_'+performance_metrics_list_grid[i]]
performances_df['Parameters']=parameters_search.cv_results_['params']
performances_df['Execution time']=parameters_search.cv_results_['mean_fit_time']
return performances_df
Notebook Cell
def model_selection_wrapper(transactions_df,
classifier,
input_features, output_feature,
parameters,
scoring,
start_date_training_for_valid,
start_date_training_for_test,
n_folds=4,
delta_train=7,
delta_delay=7,
delta_assessment=7,
performance_metrics_list_grid=['roc_auc'],
performance_metrics_list=['AUC ROC'],
type_search='grid',
n_iter=10,
random_state=0,
n_jobs=-1):
# Get performances on the validation set using prequential validation
performances_df_validation=prequential_parameters_search(transactions_df, classifier,
input_features, output_feature,
parameters, scoring,
start_date_training=start_date_training_for_valid,
n_folds=n_folds,
expe_type='Validation',
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list,
type_search=type_search,
n_iter=n_iter,
random_state=random_state,
n_jobs=n_jobs)
# Get performances on the test set using prequential validation
performances_df_test=prequential_parameters_search(transactions_df, classifier,
input_features, output_feature,
parameters, scoring,
start_date_training=start_date_training_for_test,
n_folds=n_folds,
expe_type='Test',
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list,
type_search=type_search,
n_iter=n_iter,
random_state=random_state,
n_jobs=n_jobs)
# Bind the two resulting DataFrames
performances_df_validation.drop(columns=['Parameters','Execution time'], inplace=True)
performances_df=pd.concat([performances_df_test,performances_df_validation],axis=1)
# And return as a single DataFrame
return performances_df
Vamos executar novamente a seleção de modelos para boosting, mas usando busca aleatória, com 10 combinações de parâmetros.
classifier = xgboost.XGBClassifier()
parameters = {'clf__max_depth':[3,6,9], 'clf__n_estimators':[25,50,100],'clf__learning_rate':[0.1,0.3],
'clf__random_state':[0],'clf__n_jobs':[1],'clf__n_verbosity':[0]}
start_time=time.time()
performances_df=model_selection_wrapper(transactions_df, classifier,
input_features, output_feature,
parameters, scoring,
start_date_training_for_valid,
start_date_training_for_test,
n_folds=n_folds,
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list,
type_search='random',
n_iter=10,
random_state=0,
n_jobs=1)
execution_time_boosting_random = time.time()-start_time
parameters_dict=dict(performances_df['Parameters'])
performances_df['Parameters summary']=[str(parameters_dict[i]['clf__n_estimators'])+
'/'+
str(parameters_dict[i]['clf__learning_rate'])+
'/'+
str(parameters_dict[i]['clf__max_depth'])
for i in range(len(parameters_dict))]
# Rename to performances_df_xgboost_random for model performance comparison
performances_df_xgboost_random=performances_dfNotebook Cell
performances_df_xgboost_randomA função get_summary_performances fornece o resumo dos melhores parâmetros e os desempenhos correspondentes.
summary_performances_xgboost_random=get_summary_performances(performances_df_xgboost_random, parameter_column_name="Parameters summary")
summary_performances_xgboost_randomOs desempenhos são essencialmente os mesmos obtidos com a busca em grade.
# Performances with grid search
summary_performances_xgboostO tempo de execução foi, no entanto, significativamente mais rápido.
print("Total execution time for XGBoost with grid search: "+str(round(execution_time_boosting,2))+"s")
print("Total execution time for XGBoost with random search: "+str(round(execution_time_boosting_random,2))+"s")
Total execution time for XGBoost with grid search: 1251.2s
Total execution time for XGBoost with random search: 690.32s
Salvamento dos resultados¶
Vamos finalmente salvar os resultados de desempenho e os tempos de execução.
performances_df_dictionary={
"Decision Tree": performances_df_dt,
"Logistic Regression": performances_df_lr,
"Random Forest": performances_df_rf,
"XGBoost": performances_df_xgboost,
"XGBoost Random": performances_df_xgboost_random
}
execution_times=[execution_time_dt,
execution_time_lr,
execution_time_rf,
execution_time_boosting,
execution_time_boosting_random]
Ambas as estruturas de dados são salvas como arquivo Pickle.
filehandler = open('performances_model_selection.pkl', 'wb')
pickle.dump((performances_df_dictionary, execution_times), filehandler)
filehandler.close()- Bontempi, G. (2021). Statistical foundations of machine learning, 2nd edition. Université Libre de Bruxelles.
- Bishop, C. M. (2006). Pattern recognition and machine learning. springer.
- Friedman, J., Hastie, T., & Tibshirani, R. (2001). The elements of statistical learning (Vol. 1). Springer series in statistics New York.
- Bergstra, J., & Bengio, Y. (2012). Random search for hyper-parameter optimization. Journal of Machine Learning Research, 13(2).