O conjunto de dados simulado gerado na seção anterior é simples. Ele contém apenas as características essenciais que caracterizam uma transação de cartão de pagamento. São elas: um identificador único para a transação, a data e hora da transação, o valor da transação, um identificador único para o cliente, um número único para o comerciante e uma variável binária que rotula a transação como legítima ou fraudulenta (0 para legítima ou 1 para fraudulenta). A Fig. 1 mostra as três primeiras linhas do conjunto de dados simulado:
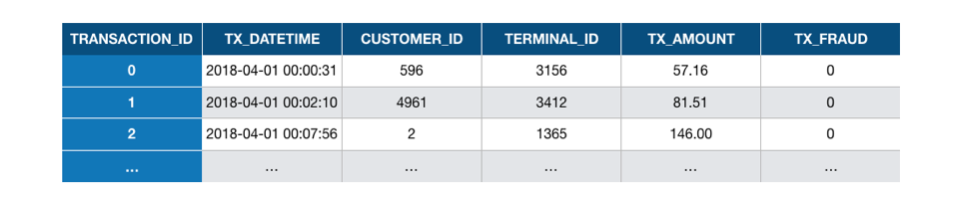
Fig. 1. As três primeiras transações no conjunto de dados simulado usado neste capítulo.
O que cada linha essencialmente resume é que, às 00:00:31, em 1º de abril de 2018, um cliente com ID 596 fez um pagamento de 57,19 a um comerciante com ID 3156, e que a transação não foi fraudulenta. Em seguida, às 00:02:10, em 1º de abril de 2018, um cliente com ID 4961 fez um pagamento de 81,51 a um comerciante com ID 3412, e que a transação não foi fraudulenta. E assim por diante. O conjunto de dados simulado é uma longa lista de tais transações (1,8 milhão no total). A variável transaction_ID é um identificador único para cada transação.
Embora conceitualmente simples para um humano, tal conjunto de características não é adequado para um modelo preditivo de aprendizado de máquina. Os algoritmos de aprendizado de máquina geralmente requerem características numéricas e ordenadas. Numéricas significa que o tipo da variável deve ser um inteiro ou um número real. Ordenadas significa que a ordem dos valores de uma variável é significativa.
Neste conjunto de dados, as únicas características numéricas e ordenadas são o valor da transação e o rótulo de fraude. A data é um timestamp do Pandas e, portanto, não é numérica. Os identificadores para transações, clientes e terminais são numéricos, mas não ordenados: não faria sentido assumir, por exemplo, que o terminal com ID 3548 é “maior” ou “superior” ao terminal com ID 1983. Em vez disso, esses identificadores representam “entidades” distintas, que são referidas como características categóricas.
Infelizmente, não existe um procedimento padrão para lidar com características não numéricas ou categóricas. O tema é conhecido na literatura de aprendizado de máquina como engenharia de características ou transformação de características. Em essência, o objetivo da engenharia de características é projetar novas características que se assumem relevantes para um problema preditivo. O design dessas características geralmente depende do problema e envolve conhecimento de domínio.
Nesta seção, implementaremos três tipos de transformação de características que são conhecidos por serem relevantes para a detecção de fraude em cartões de pagamento.

O primeiro tipo de transformação envolve a variável de data/hora e consiste em criar características binárias que caracterizam períodos potencialmente relevantes. Criaremos duas dessas características. A primeira caracterizará se uma transação ocorre durante um dia de semana ou durante o fim de semana. A segunda caracterizará se uma transação ocorre durante o dia ou à noite. Essas características podem ser úteis, pois foi observado em conjuntos de dados do mundo real que os padrões fraudulentos diferem entre dias de semana e fins de semana, e entre dia e noite.
O segundo tipo de transformação envolve o ID do cliente e consiste em criar características que caracterizam os comportamentos de gastos do cliente. Seguiremos o framework RFM (Recência, Frequência, Valor Monetário) proposto em Van Vlasselaer et al. (2015), e rastrearemos o valor médio de gastos e o número de transações para cada cliente e para três tamanhos de janela temporal. Isso levará à criação de seis novas características.
O terceiro tipo de transformação envolve o ID do terminal e consiste em criar novas características que caracterizam o “risco” associado ao terminal. O risco será definido como o número médio de fraudes observadas no terminal para três tamanhos de janela temporal. Isso levará à criação de três novas características.
A tabela abaixo resume os tipos de transformação que serão realizados e as novas características que serão criadas.
| Nome da característica original | Tipo da característica original | Transformação | Número de novas características | Tipo da(s) nova(s) característica(s) |
|---|---|---|---|---|
| TX_DATE_TIME | Timestamp do Pandas | 0 se a transação ocorrer em um dia de semana, 1 se ocorrer em um fim de semana. A nova característica é chamada TX_DURING_WEEKEND. | 1 | Inteiro (0/1) |
| TX_DATE_TIME | Timestamp do Pandas | 0 se a transação ocorrer entre 6h e 0h, 1 se ocorrer entre 0h e 6h. A nova característica é chamada TX_DURING_NIGHT. | 1 | Inteiro (0/1) |
| CUSTOMER_ID | Variável categórica | Número de transações do cliente nos últimos n dia(s), para n em {1,7,30}. As novas características são chamadas CUSTOMER_ID_NB_TX_nDAY_WINDOW. | 3 | Inteiro |
| CUSTOMER_ID | Variável categórica | Valor médio de gastos nos últimos n dia(s), para n em {1,7,30}. As novas características são chamadas CUSTOMER_ID_AVG_AMOUNT_nDAY_WINDOW. | 3 | Real |
| TERMINAL_ID | Variável categórica | Número de transações no terminal nos últimos n+d dia(s), para n em {1,7,30} e d=7. O parâmetro d é chamado de atraso e será discutido mais adiante neste notebook. As novas características são chamadas TERMINAL_ID_NB_TX_nDAY_WINDOW. | 3 | Inteiro |
| TERMINAL_ID | Variável categórica | Número médio de fraudes no terminal nos últimos n+d dia(s), para n em {1,7,30} e d=7. O parâmetro d é chamado de atraso e será discutido mais adiante neste notebook. As novas características são chamadas TERMINAL_ID_RISK_nDAY_WINDOW. | 3 | Real |
As seções seguintes fornecem a implementação de cada uma dessas três transformações. Após as transformações, um conjunto de 14 novas características será criado. Note que algumas características são resultado de funções de agregação sobre os valores de outras características ou condições (mesmo cliente, janela temporal fornecida). Essas características são frequentemente referidas como características agregadas.
Notebook Cell
# Initialization: Load shared functions and simulated data
# Load shared functions
!curl -O https://raw.githubusercontent.com/Fraud-Detection-Handbook/fraud-detection-handbook/main/Chapter_References/shared_functions.py
%run shared_functions.py
# Get simulated data from Github repository
if not os.path.exists("simulated-data-raw"):
!git clone https://github.com/Fraud-Detection-Handbook/simulated-data-raw
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 31567 100 31567 0 0 135k 0 --:--:-- --:--:-- --:--:-- 135k
Cloning into 'simulated-data-raw'...
remote: Enumerating objects: 189, done.
remote: Counting objects: 100% (189/189), done.
remote: Compressing objects: 100% (187/187), done.
remote: Total 189 (delta 0), reused 186 (delta 0), pack-reused 0
Receiving objects: 100% (189/189), 28.04 MiB | 3.13 MiB/s, done.
Carregamento do conjunto de dados¶
Vamos primeiro carregar os dados de transação simulados no notebook anterior. Carregaremos os arquivos de transação de abril a setembro. Os arquivos podem ser carregados usando a função read_from_files no notebook de funções compartilhadas. A função foi colocada neste notebook pois será usada frequentemente ao longo deste livro.
A função recebe como entrada a pasta onde os arquivos de dados estão localizados e as datas que definem o período a ser carregado (entre BEGIN_DATE e END_DATE). Ela retorna um DataFrame de transações. As transações são ordenadas cronologicamente.
DIR_INPUT='./simulated-data-raw/data/'
BEGIN_DATE = "2018-04-01"
END_DATE = "2018-09-30"
print("Load files")
%time transactions_df=read_from_files(DIR_INPUT, BEGIN_DATE, END_DATE)
print("{0} transactions loaded, containing {1} fraudulent transactions".format(len(transactions_df),transactions_df.TX_FRAUD.sum()))
Load files
CPU times: user 3.1 s, sys: 696 ms, total: 3.79 s
Wall time: 4.13 s
1754155 transactions loaded, containing 14681 fraudulent transactions
transactions_df.head()Transformações de data e hora¶
Criaremos duas novas características binárias a partir das datas e horas das transações:
A primeira caracterizará se uma transação ocorre durante um dia de semana (valor 0) ou um fim de semana (1), e será chamada
TX_DURING_WEEKENDA segunda caracterizará se uma transação ocorre durante o dia (0) ou durante a noite (1). A noite é definida como as horas entre 0h e 6h. Será chamada
TX_DURING_NIGHT.
Para a característica TX_DURING_WEEKEND, definimos uma função is_weekend que recebe como entrada um timestamp do Pandas e retorna 1 se a data for durante um fim de semana, ou 0 caso contrário. O objeto timestamp convenientemente fornece a função weekday para ajudar no cálculo desse valor.
def is_weekend(tx_datetime):
# Transform date into weekday (0 is Monday, 6 is Sunday)
weekday = tx_datetime.weekday()
# Binary value: 0 if weekday, 1 if weekend
is_weekend = weekday>=5
return int(is_weekend)
É então simples calcular essa característica para todas as transações usando a função apply do Pandas.
%time transactions_df['TX_DURING_WEEKEND']=transactions_df.TX_DATETIME.apply(is_weekend)CPU times: user 7.54 s, sys: 247 ms, total: 7.79 s
Wall time: 7.94 s
Seguimos a mesma lógica para implementar a característica TX_DURING_NIGHT. Primeiro, uma função is_night que recebe como entrada um timestamp do Pandas e retorna 1 se o horário for noturno, ou 0 caso contrário. O objeto timestamp convenientemente fornece a propriedade hour para ajudar no cálculo desse valor.
def is_night(tx_datetime):
# Get the hour of the transaction
tx_hour = tx_datetime.hour
# Binary value: 1 if hour less than 6, and 0 otherwise
is_night = tx_hour<=6
return int(is_night)%time transactions_df['TX_DURING_NIGHT']=transactions_df.TX_DATETIME.apply(is_night)CPU times: user 7.09 s, sys: 221 ms, total: 7.31 s
Wall time: 7.47 s
Vamos verificar se essas características foram calculadas corretamente.
transactions_df[transactions_df.TX_TIME_DAYS>=30]O dia 2018-05-01 foi uma segunda-feira, e o 2018-09-30 foi um domingo. Essas datas estão corretamente sinalizadas como dia de semana e fim de semana, respectivamente. A característica de dia e noite também está corretamente definida para as primeiras transações, que ocorrem logo após 0h, e as últimas transações que ocorrem logo antes de 0h.
Transformações do ID do cliente¶
Vamos agora prosseguir com as transformações do ID do cliente. Nos inspiraremos no framework RFM (Recência, Frequência, Valor Monetário) proposto em Van Vlasselaer et al. (2015), e calcularemos duas dessas características em três janelas temporais. A primeira característica será o número de transações que ocorrem dentro de uma janela temporal (Frequência). A segunda será o valor médio gasto nessas transações (Valor Monetário). As janelas temporais serão definidas em um, sete e trinta dias. Isso gerará seis novas características. Note que essas janelas temporais poderiam ser otimizadas posteriormente junto com os modelos usando um procedimento de seleção de modelos (Capítulo 5).
Vamos implementar essas transformações escrevendo uma função get_customer_spending_behaviour_features. A função recebe como entradas o conjunto de transações de um cliente e um conjunto de tamanhos de janela. Ela retorna um DataFrame com as seis novas características. Nossa implementação baseia-se na função rolling do Pandas, que facilita o cálculo de agregados em uma janela temporal.
Notebook Cell
def get_customer_spending_behaviour_features(customer_transactions, windows_size_in_days=[1,7,30]):
# Let us first order transactions chronologically
customer_transactions=customer_transactions.sort_values('TX_DATETIME')
# The transaction date and time is set as the index, which will allow the use of the rolling function
customer_transactions.index=customer_transactions.TX_DATETIME
# For each window size
for window_size in windows_size_in_days:
# Compute the sum of the transaction amounts and the number of transactions for the given window size
SUM_AMOUNT_TX_WINDOW=customer_transactions['TX_AMOUNT'].rolling(str(window_size)+'d').sum()
NB_TX_WINDOW=customer_transactions['TX_AMOUNT'].rolling(str(window_size)+'d').count()
# Compute the average transaction amount for the given window size
# NB_TX_WINDOW is always >0 since current transaction is always included
AVG_AMOUNT_TX_WINDOW=SUM_AMOUNT_TX_WINDOW/NB_TX_WINDOW
# Save feature values
customer_transactions['CUSTOMER_ID_NB_TX_'+str(window_size)+'DAY_WINDOW']=list(NB_TX_WINDOW)
customer_transactions['CUSTOMER_ID_AVG_AMOUNT_'+str(window_size)+'DAY_WINDOW']=list(AVG_AMOUNT_TX_WINDOW)
# Reindex according to transaction IDs
customer_transactions.index=customer_transactions.TRANSACTION_ID
# And return the dataframe with the new features
return customer_transactions
Vamos calcular esses agregados para o primeiro cliente.
spending_behaviour_customer_0=get_customer_spending_behaviour_features(transactions_df[transactions_df.CUSTOMER_ID==0])
spending_behaviour_customer_0Podemos verificar que as novas características são consistentes com o perfil do cliente (ver o notebook anterior). Para o cliente 0, o valor médio era mean_amount=62.26, e a frequência de transação era mean_nb_tx_per_day=2.18. Esses valores são de fato bem correspondidos pelas características CUSTOMER_ID_NB_TX_30DAY_WINDOW e CUSTOMER_ID_AVG_AMOUNT_30DAY_WINDOW, especialmente após 30 dias.
Vamos agora gerar essas características para todos os clientes. Isso é simples usando os métodos groupby e apply do Pandas.
%time transactions_df=transactions_df.groupby('CUSTOMER_ID').apply(lambda x: get_customer_spending_behaviour_features(x, windows_size_in_days=[1,7,30]))
transactions_df=transactions_df.sort_values('TX_DATETIME').reset_index(drop=True)
CPU times: user 1min 2s, sys: 1.21 s, total: 1min 3s
Wall time: 1min 7s
transactions_dfTransformações do ID do terminal¶
Por fim, vamos prosseguir com as transformações do ID do terminal. O principal objetivo será extrair uma pontuação de risco que avalia a exposição de um determinado ID de terminal a transações fraudulentas. A pontuação de risco será definida como o número médio de transações fraudulentas que ocorreram em um ID de terminal ao longo de uma janela temporal. Assim como nas transformações do ID do cliente, usaremos três tamanhos de janela: 1, 7 e 30 dias.
Ao contrário das transformações do ID do cliente, as janelas temporais não precederão diretamente uma determinada transação. Em vez disso, elas serão deslocadas para trás por um período de atraso. O período de atraso leva em conta o fato de que, na prática, as transações fraudulentas só são descobertas após uma investigação de fraude ou uma reclamação do cliente. Portanto, os rótulos fraudulentos, necessários para calcular a pontuação de risco, só estão disponíveis após esse período de atraso. Como primeira aproximação, esse período de atraso será definido como uma semana. As motivações para o período de atraso serão discutidas com mais detalhes no Capítulo 5, Estratégias de validação.
Vamos realizar o cálculo das pontuações de risco definindo uma função get_count_risk_rolling_window. A função recebe como entradas o DataFrame de transações para um determinado ID de terminal, o período de atraso e uma lista de tamanhos de janela. Na primeira etapa, o número de transações e de transações fraudulentas é calculado para o período de atraso (NB_TX_DELAY e NB_FRAUD_DELAY). Na segunda etapa, o número de transações e de transações fraudulentas é calculado para cada tamanho de janela mais o período de atraso (NB_TX_DELAY_WINDOW e NB_FRAUD_DELAY_WINDOW). O número de transações e de transações fraudulentas que ocorreram para um determinado tamanho de janela, deslocado para trás pelo período de atraso, é então obtido simplesmente calculando as diferenças das quantidades obtidas para o período de atraso e o tamanho de janela mais o período de atraso:
NB_FRAUD_WINDOW=NB_FRAUD_DELAY_WINDOW-NB_FRAUD_DELAY
NB_TX_WINDOW=NB_TX_DELAY_WINDOW-NB_TX_DELAYA pontuação de risco é finalmente obtida calculando a proporção de transações fraudulentas para cada tamanho de janela (ou 0 se nenhuma transação ocorreu para a janela fornecida):
RISK_WINDOW=NB_FRAUD_WINDOW/NB_TX_WINDOWAlém da pontuação de risco, a função também retorna o número de transações para cada tamanho de janela. Isso resulta na adição de seis novas características: o risco e o número de transações, para três tamanhos de janela.
def get_count_risk_rolling_window(terminal_transactions, delay_period=7, windows_size_in_days=[1,7,30], feature="TERMINAL_ID"):
terminal_transactions=terminal_transactions.sort_values('TX_DATETIME')
terminal_transactions.index=terminal_transactions.TX_DATETIME
NB_FRAUD_DELAY=terminal_transactions['TX_FRAUD'].rolling(str(delay_period)+'d').sum()
NB_TX_DELAY=terminal_transactions['TX_FRAUD'].rolling(str(delay_period)+'d').count()
for window_size in windows_size_in_days:
NB_FRAUD_DELAY_WINDOW=terminal_transactions['TX_FRAUD'].rolling(str(delay_period+window_size)+'d').sum()
NB_TX_DELAY_WINDOW=terminal_transactions['TX_FRAUD'].rolling(str(delay_period+window_size)+'d').count()
NB_FRAUD_WINDOW=NB_FRAUD_DELAY_WINDOW-NB_FRAUD_DELAY
NB_TX_WINDOW=NB_TX_DELAY_WINDOW-NB_TX_DELAY
RISK_WINDOW=NB_FRAUD_WINDOW/NB_TX_WINDOW
terminal_transactions[feature+'_NB_TX_'+str(window_size)+'DAY_WINDOW']=list(NB_TX_WINDOW)
terminal_transactions[feature+'_RISK_'+str(window_size)+'DAY_WINDOW']=list(RISK_WINDOW)
terminal_transactions.index=terminal_transactions.TRANSACTION_ID
# Replace NA values with 0 (all undefined risk scores where NB_TX_WINDOW is 0)
terminal_transactions.fillna(0,inplace=True)
return terminal_transactions
transactions_df[transactions_df.TX_FRAUD==1]Vamos calcular essas seis características para o primeiro ID de terminal que contém pelo menos uma fraude:
# Get the first terminal ID that contains frauds
transactions_df[transactions_df.TX_FRAUD==0].TERMINAL_ID[0]3156get_count_risk_rolling_window(transactions_df[transactions_df.TERMINAL_ID==3059], delay_period=7, windows_size_in_days=[1,7,30])Podemos verificar que a primeira fraude ocorreu em 2018/09/10, e que as pontuações de risco só começam a ser contadas com um atraso de uma semana.
Vamos finalmente gerar essas características para todos os terminais. Isso é simples usando os métodos groupby e apply do Pandas.
%time transactions_df=transactions_df.groupby('TERMINAL_ID').apply(lambda x: get_count_risk_rolling_window(x, delay_period=7, windows_size_in_days=[1,7,30], feature="TERMINAL_ID"))
transactions_df=transactions_df.sort_values('TX_DATETIME').reset_index(drop=True)
CPU times: user 2min 27s, sys: 2.23 s, total: 2min 29s
Wall time: 2min 41s
transactions_dfSalvamento do conjunto de dados¶
Vamos finalmente salvar o conjunto de dados, dividido em lotes diários, usando o formato pickle.
DIR_OUTPUT = "./simulated-data-transformed/"
if not os.path.exists(DIR_OUTPUT):
os.makedirs(DIR_OUTPUT)
start_date = datetime.datetime.strptime("2018-04-01", "%Y-%m-%d")
for day in range(transactions_df.TX_TIME_DAYS.max()+1):
transactions_day = transactions_df[transactions_df.TX_TIME_DAYS==day].sort_values('TX_TIME_SECONDS')
date = start_date + datetime.timedelta(days=day)
filename_output = date.strftime("%Y-%m-%d")+'.pkl'
# Protocol=4 required for Google Colab
transactions_day.to_pickle(DIR_OUTPUT+filename_output, protocol=4)O conjunto de dados gerado também está disponível no Github em https://github.com/Fraud-Detection-Handbook/simulated-data-transformed.
- Van Vlasselaer, V., Bravo, C., Caelen, O., Eliassi-Rad, T., Akoglu, L., Snoeck, M., & Baesens, B. (2015). APATE: A novel approach for automated credit card transaction fraud detection using network-based extensions. Decision Support Systems, 75, 38–48.