Esta seção apresenta um simulador de dados de transações legítimas e fraudulentas. Este simulador será usado ao longo do restante deste livro para motivar e avaliar a eficiência de diferentes técnicas de detecção de fraude de forma reprodutível.
Uma simulação é necessariamente uma aproximação da realidade. Comparado à complexidade das dinâmicas subjacentes aos dados de transações de cartão de pagamento do mundo real, o simulador de dados que apresentamos abaixo segue um design simples.
Este design simples é uma escolha. Primeiro, ter regras simples para gerar transações e comportamentos fraudulentos ajudará a interpretar os tipos de padrões que diferentes técnicas de detecção de fraude podem identificar. Segundo, embora simples em seu design, o simulador de dados gerará conjuntos de dados desafiadores de se lidar.
Os conjuntos de dados simulados destacarão a maioria dos problemas que os praticantes de detecção de fraude enfrentam usando dados do mundo real. Em particular, eles incluirão desequilíbrio de classes (menos de 1% de transações fraudulentas), uma mistura de características numéricas e categóricas (com características categóricas envolvendo um número muito grande de valores), relações não triviais entre características e cenários de fraude dependentes do tempo.
Escolhas de design¶
Características das transações¶
Nosso foco será nas características mais essenciais de uma transação. Em essência, uma transação de cartão de pagamento consiste em qualquer valor pago a um comerciante por um cliente em um determinado momento. As seis principais características que resumem uma transação são:
O ID da transação: Um identificador único para a transação
A data e hora: Data e hora em que a transação ocorre
O ID do cliente: O identificador do cliente. Cada cliente tem um identificador único
O ID do terminal: O identificador do comerciante (ou mais precisamente do terminal). Cada terminal tem um identificador único
O valor da transação: O valor da transação.
O rótulo de fraude: Uma variável binária, com o valor 0 para uma transação legítima ou o valor 1 para uma transação fraudulenta.
Essas características serão referidas como TRANSACTION_ID, TX_DATETIME, CUSTOMER_ID, TERMINAL_ID, TX_AMOUNT e TX_FRAUD.
O objetivo do simulador de dados de transações será gerar uma tabela de transações com essas características. Esta tabela será referida como a tabela de transações rotuladas. Tal tabela é ilustrada na Fig. 1.
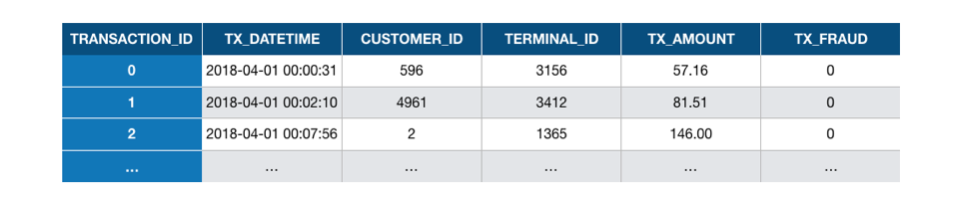
Fig. 1. Exemplo de tabela de transações rotuladas. Cada transação é representada como uma linha na tabela,
juntamente com seu rótulo (variável TX_FRAUD, 0 para legítimas e 1 para transações fraudulentas).
Notebook Cell
# Necessary imports for this notebook
import os
import numpy as np
import pandas as pd
import datetime
import time
import random
# For plotting
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('darkgrid', {'axes.facecolor': '0.9'})
Geração de perfis de clientes¶
Cada cliente será definido pelas seguintes propriedades:
CUSTOMER_ID: O ID único do cliente(
x_customer_id,y_customer_id): Um par de coordenadas reais (x_customer_id,y_customer_id) em uma grade de 100 * 100, que define a localização geográfica do cliente(
mean_amount,std_amount): A média e o desvio padrão dos valores de transação para o cliente, assumindo que os valores de transação seguem uma distribuição normal. Omean_amountserá extraído de uma distribuição uniforme (5,100) e ostd_amountserá definido comomean_amountdividido por dois.mean_nb_tx_per_day: O número médio de transações por dia para o cliente, assumindo que o número de transações por dia segue uma distribuição de Poisson. Esse número será extraído de uma distribuição uniforme (0,4).
A função generate_customer_profiles_table fornece uma implementação para gerar uma tabela de perfis de clientes. Ela recebe como entrada o número de clientes para os quais gerar um perfil e um estado aleatório para reprodutibilidade. Retorna um DataFrame contendo as propriedades de cada cliente.
Processo de geração de transações¶
A simulação consistirá em cinco etapas principais:
Geração de perfis de clientes: Cada cliente é diferente em seus hábitos de gastos. Isso será simulado definindo algumas propriedades para cada cliente. As principais propriedades serão sua localização geográfica, frequência de gastos e valores de gastos. As propriedades do cliente serão representadas como uma tabela, referida como a tabela de perfis de clientes.
Geração de perfis de terminais: As propriedades dos terminais consistirão simplesmente em uma localização geográfica. As propriedades dos terminais serão representadas como uma tabela, referida como a tabela de perfis de terminais.
Associação de perfis de clientes a terminais: Assumiremos que os clientes só realizam transações em terminais que estão dentro de um raio de de suas localizações geográficas. Isso pressupõe simplesmente que um cliente só realiza transações em terminais que estão geograficamente próximos de sua localização. Esta etapa consistirá em adicionar uma característica ‘list_terminals’ a cada perfil de cliente, que contém o conjunto de terminais que um cliente pode usar.
Geração de transações: O simulador percorrerá o conjunto de perfis de clientes e gerará transações de acordo com suas propriedades (frequências e valores de gastos, e terminais disponíveis). Isso resultará em uma tabela de transações.
Geração de cenários de fraude: Esta última etapa rotulará as transações como legítimas ou fraudulentas. Isso será feito seguindo três diferentes cenários de fraude.
O processo de geração de transações é ilustrado abaixo.
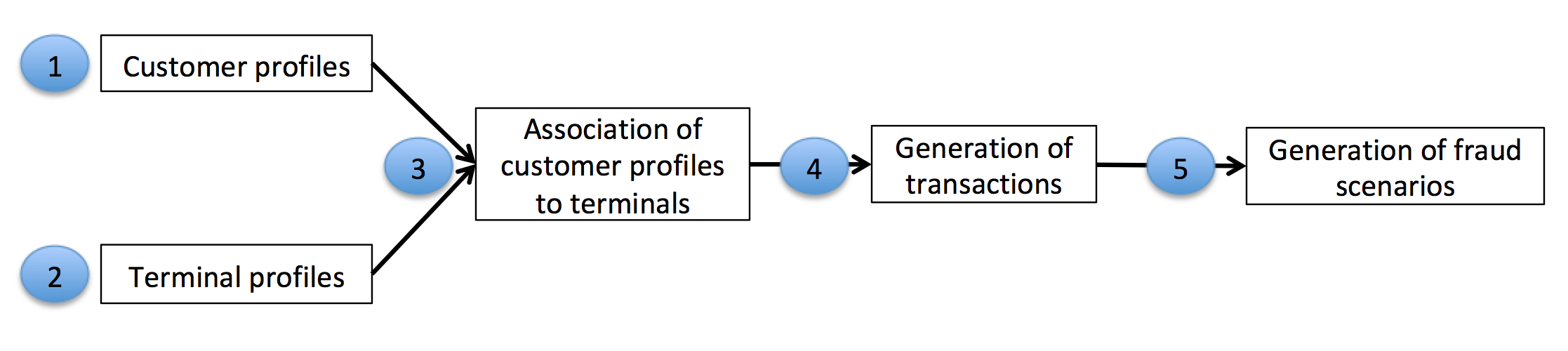
Fig. 2. Processo de geração de transações. Os perfis de clientes e terminais são usados para gerar
um conjunto de transações. A etapa final, que gera cenários de fraude, fornece a tabela de transações rotuladas.
As seções seguintes detalham a implementação de cada uma dessas etapas.
Notebook Cell
def generate_customer_profiles_table(n_customers, random_state=0):
np.random.seed(random_state)
customer_id_properties=[]
# Generate customer properties from random distributions
for customer_id in range(n_customers):
x_customer_id = np.random.uniform(0,100)
y_customer_id = np.random.uniform(0,100)
mean_amount = np.random.uniform(5,100) # Arbitrary (but sensible) value
std_amount = mean_amount/2 # Arbitrary (but sensible) value
mean_nb_tx_per_day = np.random.uniform(0,4) # Arbitrary (but sensible) value
customer_id_properties.append([customer_id,
x_customer_id, y_customer_id,
mean_amount, std_amount,
mean_nb_tx_per_day])
customer_profiles_table = pd.DataFrame(customer_id_properties, columns=['CUSTOMER_ID',
'x_customer_id', 'y_customer_id',
'mean_amount', 'std_amount',
'mean_nb_tx_per_day'])
return customer_profiles_tableComo exemplo, vamos gerar uma tabela de perfis de clientes para cinco clientes:
n_customers = 5
customer_profiles_table = generate_customer_profiles_table(n_customers, random_state = 0)
customer_profiles_tableGeração de perfis de terminais¶
Cada terminal será definido pelas seguintes propriedades:
TERMINAL_ID: O ID do terminal(
x_terminal_id,y_terminal_id): Um par de coordenadas reais (x_terminal_id,y_terminal_id) em uma grade de 100 * 100, que define a localização geográfica do terminal
A função generate_terminal_profiles_table fornece uma implementação para gerar uma tabela de perfis de terminais. Ela recebe como entrada o número de terminais para os quais gerar um perfil e um estado aleatório para reprodutibilidade. Retorna um DataFrame contendo as propriedades de cada terminal.
Notebook Cell
def generate_terminal_profiles_table(n_terminals, random_state=0):
np.random.seed(random_state)
terminal_id_properties=[]
# Generate terminal properties from random distributions
for terminal_id in range(n_terminals):
x_terminal_id = np.random.uniform(0,100)
y_terminal_id = np.random.uniform(0,100)
terminal_id_properties.append([terminal_id,
x_terminal_id, y_terminal_id])
terminal_profiles_table = pd.DataFrame(terminal_id_properties, columns=['TERMINAL_ID',
'x_terminal_id', 'y_terminal_id'])
return terminal_profiles_tableComo exemplo, vamos gerar uma tabela de terminais para cinco terminais:
n_terminals = 5
terminal_profiles_table = generate_terminal_profiles_table(n_terminals, random_state = 0)
terminal_profiles_tableAssociação de perfis de clientes a terminais¶
Vamos agora associar os terminais aos perfis de clientes. Em nosso design, os clientes só podem realizar transações em terminais que estão dentro de um raio de r de suas localizações geográficas.
Vamos primeiro escrever uma função, chamada get_list_terminals_within_radius, que encontra esses terminais para um perfil de cliente. A função receberá como entrada um perfil de cliente (qualquer linha na tabela de perfis de clientes), um array que contém a localização geográfica de todos os terminais, e o raio r. Ela retornará a lista de terminais dentro de um raio de r para esse cliente.
Notebook Cell
def get_list_terminals_within_radius(customer_profile, x_y_terminals, r):
# Use numpy arrays in the following to speed up computations
# Location (x,y) of customer as numpy array
x_y_customer = customer_profile[['x_customer_id','y_customer_id']].values.astype(float)
# Squared difference in coordinates between customer and terminal locations
squared_diff_x_y = np.square(x_y_customer - x_y_terminals)
# Sum along rows and compute suared root to get distance
dist_x_y = np.sqrt(np.sum(squared_diff_x_y, axis=1))
# Get the indices of terminals which are at a distance less than r
available_terminals = list(np.where(dist_x_y<r)[0])
# Return the list of terminal IDs
return available_terminals
Como exemplo, vamos obter a lista de terminais que estão dentro de um raio do último cliente:
# We first get the geographical locations of all terminals as a numpy array
x_y_terminals = terminal_profiles_table[['x_terminal_id','y_terminal_id']].values.astype(float)
# And get the list of terminals within radius of $50$ for the last customer
get_list_terminals_within_radius(customer_profiles_table.iloc[4], x_y_terminals=x_y_terminals, r=50)[2, 3]A lista contém o terceiro e o quarto terminais, que são de fato os únicos dentro de um raio de 50 do último cliente.
terminal_profiles_tablePara melhor visualização, vamos plotar
As localizações de todos os terminais (em azul)
A localização do último cliente (em vermelho)
A região dentro do raio de 50 do último cliente (em verde)
Notebook Cell
%%capture
terminals_available_to_customer_fig, ax = plt.subplots(figsize=(5,5))
# Plot locations of terminals
ax.scatter(terminal_profiles_table.x_terminal_id.values,
terminal_profiles_table.y_terminal_id.values,
color='blue', label = 'Locations of terminals')
# Plot location of the last customer
customer_id=4
ax.scatter(customer_profiles_table.iloc[customer_id].x_customer_id,
customer_profiles_table.iloc[customer_id].y_customer_id,
color='red',label="Location of last customer")
ax.legend(loc = 'upper left', bbox_to_anchor=(1.05, 1))
# Plot the region within a radius of 50 of the last customer
circ = plt.Circle((customer_profiles_table.iloc[customer_id].x_customer_id,
customer_profiles_table.iloc[customer_id].y_customer_id), radius=50, color='g', alpha=0.2)
ax.add_patch(circ)
fontsize=15
ax.set_title("Green circle: \n Terminals within a radius of 50 \n of the last customer")
ax.set_xlim([0, 100])
ax.set_ylim([0, 100])
ax.set_xlabel('x_terminal_id', fontsize=fontsize)
ax.set_ylabel('y_terminal_id', fontsize=fontsize)
terminals_available_to_customer_fig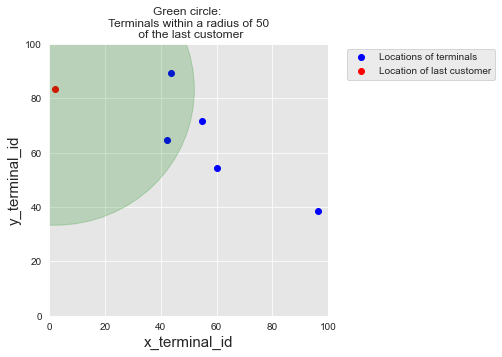
Calcular a lista de terminais disponíveis para cada cliente é então simples, usando a função apply do pandas. Armazenamos os resultados como uma nova coluna available_terminals na tabela de perfis de clientes.
customer_profiles_table['available_terminals']=customer_profiles_table.apply(lambda x : get_list_terminals_within_radius(x, x_y_terminals=x_y_terminals, r=50), axis=1)
customer_profiles_tableVale notar que o raio controla o número de terminais que estarão em média disponíveis para cada cliente. À medida que o número de terminais aumenta, esse raio deve ser adaptado para corresponder ao número médio desejado de terminais disponíveis por cliente em uma simulação.
Geração de transações¶
Os perfis de clientes agora contêm todas as informações necessárias para gerar transações. A geração de transações será feita por uma função generate_transactions_table que recebe como entrada um perfil de cliente, uma data de início e um número de dias para os quais gerar transações. Ela retornará uma tabela de transações, que segue o formato apresentado acima (sem o rótulo de transação, que será adicionado na geração de cenários de fraude).
Notebook Cell
def generate_transactions_table(customer_profile, start_date = "2018-04-01", nb_days = 10):
customer_transactions = []
random.seed(int(customer_profile.CUSTOMER_ID))
np.random.seed(int(customer_profile.CUSTOMER_ID))
# For all days
for day in range(nb_days):
# Random number of transactions for that day
nb_tx = np.random.poisson(customer_profile.mean_nb_tx_per_day)
# If nb_tx positive, let us generate transactions
if nb_tx>0:
for tx in range(nb_tx):
# Time of transaction: Around noon, std 20000 seconds. This choice aims at simulating the fact that
# most transactions occur during the day.
time_tx = int(np.random.normal(86400/2, 20000))
# If transaction time between 0 and 86400, let us keep it, otherwise, let us discard it
if (time_tx>0) and (time_tx<86400):
# Amount is drawn from a normal distribution
amount = np.random.normal(customer_profile.mean_amount, customer_profile.std_amount)
# If amount negative, draw from a uniform distribution
if amount<0:
amount = np.random.uniform(0,customer_profile.mean_amount*2)
amount=np.round(amount,decimals=2)
if len(customer_profile.available_terminals)>0:
terminal_id = random.choice(customer_profile.available_terminals)
customer_transactions.append([time_tx+day*86400, day,
customer_profile.CUSTOMER_ID,
terminal_id, amount])
customer_transactions = pd.DataFrame(customer_transactions, columns=['TX_TIME_SECONDS', 'TX_TIME_DAYS', 'CUSTOMER_ID', 'TERMINAL_ID', 'TX_AMOUNT'])
if len(customer_transactions)>0:
customer_transactions['TX_DATETIME'] = pd.to_datetime(customer_transactions["TX_TIME_SECONDS"], unit='s', origin=start_date)
customer_transactions=customer_transactions[['TX_DATETIME','CUSTOMER_ID', 'TERMINAL_ID', 'TX_AMOUNT','TX_TIME_SECONDS', 'TX_TIME_DAYS']]
return customer_transactions
Vamos por exemplo gerar transações para o primeiro cliente, por cinco dias, a partir da data 2018-04-01:
transaction_table_customer_0=generate_transactions_table(customer_profiles_table.iloc[0],
start_date = "2018-04-01",
nb_days = 5)
transaction_table_customer_0Podemos fazer uma verificação rápida de que as transações geradas seguem as propriedades do perfil do cliente:
Os IDs dos terminais são de fato aqueles na lista de terminais disponíveis (0, 1, 2 e 3)
Os valores das transações parecem seguir os parâmetros de valor do cliente (
mean_amount=62.26 estd_amount=31.13)O número de transações por dia varia de acordo com os parâmetros de frequência de transação do cliente (
mean_nb_tx_per_day=2.18).
Vamos agora gerar as transações para todos os clientes. Isso é simples usando os métodos groupby e apply do pandas:
transactions_df=customer_profiles_table.groupby('CUSTOMER_ID').apply(lambda x : generate_transactions_table(x.iloc[0], nb_days=5)).reset_index(drop=True)
transactions_dfIsso nos dá um conjunto de 65 transações, com 5 clientes, 5 terminais e 5 dias.
Escalando para um conjunto de dados maior¶
Agora temos todos os blocos de construção para gerar um conjunto de dados maior. Vamos escrever uma função generate_dataset, que cuidará de executar todas as etapas anteriores. Ela irá
receber como entradas o número desejado de clientes, terminais e dias, bem como a data de início e o raio
rretornar os perfis de clientes e terminais gerados e o DataFrame de transações.
Notebook Cell
def generate_dataset(n_customers = 10000, n_terminals = 1000000, nb_days=90, start_date="2018-04-01", r=5):
start_time=time.time()
customer_profiles_table = generate_customer_profiles_table(n_customers, random_state = 0)
print("Time to generate customer profiles table: {0:.2}s".format(time.time()-start_time))
start_time=time.time()
terminal_profiles_table = generate_terminal_profiles_table(n_terminals, random_state = 1)
print("Time to generate terminal profiles table: {0:.2}s".format(time.time()-start_time))
start_time=time.time()
x_y_terminals = terminal_profiles_table[['x_terminal_id','y_terminal_id']].values.astype(float)
customer_profiles_table['available_terminals'] = customer_profiles_table.apply(lambda x : get_list_terminals_within_radius(x, x_y_terminals=x_y_terminals, r=r), axis=1)
# With Pandarallel
#customer_profiles_table['available_terminals'] = customer_profiles_table.parallel_apply(lambda x : get_list_closest_terminals(x, x_y_terminals=x_y_terminals, r=r), axis=1)
customer_profiles_table['nb_terminals']=customer_profiles_table.available_terminals.apply(len)
print("Time to associate terminals to customers: {0:.2}s".format(time.time()-start_time))
start_time=time.time()
transactions_df=customer_profiles_table.groupby('CUSTOMER_ID').apply(lambda x : generate_transactions_table(x.iloc[0], nb_days=nb_days)).reset_index(drop=True)
# With Pandarallel
#transactions_df=customer_profiles_table.groupby('CUSTOMER_ID').parallel_apply(lambda x : generate_transactions_table(x.iloc[0], nb_days=nb_days)).reset_index(drop=True)
print("Time to generate transactions: {0:.2}s".format(time.time()-start_time))
# Sort transactions chronologically
transactions_df=transactions_df.sort_values('TX_DATETIME')
# Reset indices, starting from 0
transactions_df.reset_index(inplace=True,drop=True)
transactions_df.reset_index(inplace=True)
# TRANSACTION_ID are the dataframe indices, starting from 0
transactions_df.rename(columns = {'index':'TRANSACTION_ID'}, inplace = True)
return (customer_profiles_table, terminal_profiles_table, transactions_df)
Vamos gerar um conjunto de dados com
5000 clientes
10000 terminais
183 dias de transações (o que corresponde a um período simulado de 2018/04/01 a 2018/09/30)
A data de início é arbitrariamente fixada em 2018/04/01. O raio é definido como 5, o que corresponde a cerca de 100 terminais disponíveis para cada cliente.
Leva cerca de 3 minutos para gerar este conjunto de dados em um laptop padrão.
(customer_profiles_table, terminal_profiles_table, transactions_df)=\
generate_dataset(n_customers = 5000,
n_terminals = 10000,
nb_days=183,
start_date="2018-04-01",
r=5)
Time to generate customer profiles table: 0.062s
Time to generate terminal profiles table: 0.041s
Time to associate terminals to customers: 0.95s
Time to generate transactions: 7e+01s
Um total de 1754155 transações foram geradas.
transactions_df.shape(1754155, 7)Note que esse número é baixo comparado a sistemas de detecção de fraude do mundo real, onde milhões de transações podem precisar ser processadas a cada dia. No entanto, será suficiente para os propósitos deste livro, em particular para manter tempos de execução razoáveis.
transactions_dfComo verificação de sanidade, vamos plotar a distribuição dos valores de transação e dos tempos de transação.
Notebook Cell
%%capture
distribution_amount_times_fig, ax = plt.subplots(1, 2, figsize=(18,4))
amount_val = transactions_df[transactions_df.TX_TIME_DAYS<10]['TX_AMOUNT'].sample(n=10000).values
time_val = transactions_df[transactions_df.TX_TIME_DAYS<10]['TX_TIME_SECONDS'].sample(n=10000).values
sns.distplot(amount_val, ax=ax[0], color='r', hist = True, kde = False)
ax[0].set_title('Distribution of transaction amounts', fontsize=14)
ax[0].set_xlim([min(amount_val), max(amount_val)])
ax[0].set(xlabel = "Amount", ylabel="Number of transactions")
# We divide the time variables by 86400 to transform seconds to days in the plot
sns.distplot(time_val/86400, ax=ax[1], color='b', bins = 100, hist = True, kde = False)
ax[1].set_title('Distribution of transaction times', fontsize=14)
ax[1].set_xlim([min(time_val/86400), max(time_val/86400)])
ax[1].set_xticks(range(10))
ax[1].set(xlabel = "Time (days)", ylabel="Number of transactions")
distribution_amount_times_fig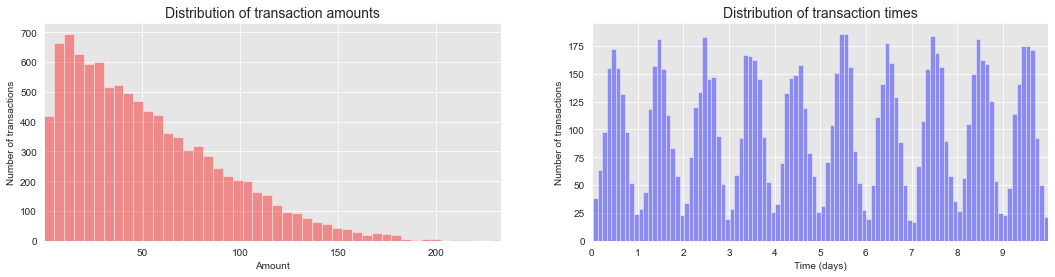
A distribuição dos valores de transação tem a maior parte de sua massa para valores pequenos. A distribuição dos tempos de transação segue uma distribuição gaussiana diariamente, centrada ao meio-dia. Essas duas distribuições estão de acordo com os parâmetros de simulação usados nas seções anteriores.
Geração de cenários de fraude¶
Esta última etapa da simulação adiciona transações fraudulentas ao conjunto de dados, usando os seguintes cenários de fraude:
Cenário 1: Qualquer transação cujo valor seja superior a 220 é uma fraude. Este cenário não é inspirado em um cenário do mundo real. Em vez disso, fornecerá um padrão de fraude óbvio que deve ser detectado por qualquer detector de fraude de linha de base. Isso será útil para validar a implementação de uma técnica de detecção de fraude.
Cenário 2: Todo dia, uma lista de dois terminais é sorteada aleatoriamente. Todas as transações nesses terminais nos próximos 28 dias serão marcadas como fraudulentas. Este cenário simula o uso criminoso de um terminal, por meio de phishing, por exemplo. Detectar este cenário será possível adicionando características que rastreiam o número de transações fraudulentas no terminal. Como o terminal está comprometido apenas por 28 dias, estratégias adicionais envolvendo deriva de conceito precisarão ser projetadas para lidar eficientemente com este cenário.
Cenário 3: Todo dia, uma lista de 3 clientes é sorteada aleatoriamente. Nos próximos 14 dias, 1/3 de suas transações têm seus valores multiplicados por 5 e marcados como fraudulentos. Este cenário simula uma fraude sem presença do cartão, onde as credenciais de um cliente foram vazadas. O cliente continua a realizar transações, e transações de valores mais altos são feitas pelo fraudador que tenta maximizar seus ganhos. Detectar este cenário exigirá a adição de características que rastreiam os hábitos de gastos do cliente. Assim como no cenário 2, como o cartão está apenas temporariamente comprometido, estratégias adicionais envolvendo deriva de conceito também devem ser projetadas.
Notebook Cell
def add_frauds(customer_profiles_table, terminal_profiles_table, transactions_df):
# By default, all transactions are genuine
transactions_df['TX_FRAUD']=0
transactions_df['TX_FRAUD_SCENARIO']=0
# Scenario 1
transactions_df.loc[transactions_df.TX_AMOUNT>220, 'TX_FRAUD']=1
transactions_df.loc[transactions_df.TX_AMOUNT>220, 'TX_FRAUD_SCENARIO']=1
nb_frauds_scenario_1=transactions_df.TX_FRAUD.sum()
print("Number of frauds from scenario 1: "+str(nb_frauds_scenario_1))
# Scenario 2
for day in range(transactions_df.TX_TIME_DAYS.max()):
compromised_terminals = terminal_profiles_table.TERMINAL_ID.sample(n=2, random_state=day)
compromised_transactions=transactions_df[(transactions_df.TX_TIME_DAYS>=day) &
(transactions_df.TX_TIME_DAYS<day+28) &
(transactions_df.TERMINAL_ID.isin(compromised_terminals))]
transactions_df.loc[compromised_transactions.index,'TX_FRAUD']=1
transactions_df.loc[compromised_transactions.index,'TX_FRAUD_SCENARIO']=2
nb_frauds_scenario_2=transactions_df.TX_FRAUD.sum()-nb_frauds_scenario_1
print("Number of frauds from scenario 2: "+str(nb_frauds_scenario_2))
# Scenario 3
for day in range(transactions_df.TX_TIME_DAYS.max()):
compromised_customers = customer_profiles_table.CUSTOMER_ID.sample(n=3, random_state=day).values
compromised_transactions=transactions_df[(transactions_df.TX_TIME_DAYS>=day) &
(transactions_df.TX_TIME_DAYS<day+14) &
(transactions_df.CUSTOMER_ID.isin(compromised_customers))]
nb_compromised_transactions=len(compromised_transactions)
random.seed(day)
index_fauds = random.sample(list(compromised_transactions.index.values),k=int(nb_compromised_transactions/3))
transactions_df.loc[index_fauds,'TX_AMOUNT']=transactions_df.loc[index_fauds,'TX_AMOUNT']*5
transactions_df.loc[index_fauds,'TX_FRAUD']=1
transactions_df.loc[index_fauds,'TX_FRAUD_SCENARIO']=3
nb_frauds_scenario_3=transactions_df.TX_FRAUD.sum()-nb_frauds_scenario_2-nb_frauds_scenario_1
print("Number of frauds from scenario 3: "+str(nb_frauds_scenario_3))
return transactions_df
Vamos adicionar transações fraudulentas usando esses cenários:
%time transactions_df = add_frauds(customer_profiles_table, terminal_profiles_table, transactions_df)Number of frauds from scenario 1: 978
Number of frauds from scenario 2: 9099
Number of frauds from scenario 3: 4604
CPU times: user 1min 14s, sys: 210 ms, total: 1min 14s
Wall time: 1min 15s
Percentual de transações fraudulentas:
transactions_df.TX_FRAUD.mean()0.008369271814634397Número de transações fraudulentas:
transactions_df.TX_FRAUD.sum()14681Um total de 14681 transações foram marcadas como fraudulentas. Isso equivale a 0,8% das transações. Note que a soma das fraudes de cada cenário não é igual ao total de transações fraudulentas. Isso ocorre porque as mesmas transações podem ter sido marcadas como fraudulentas por dois ou mais cenários de fraude.
Nosso conjunto de dados de transações simuladas está agora completo, com um rótulo de fraude adicionado a todas as transações.
transactions_df.head()transactions_df[transactions_df.TX_FRAUD_SCENARIO==1].shape(973, 9)transactions_df[transactions_df.TX_FRAUD_SCENARIO==2].shape(9077, 9)transactions_df[transactions_df.TX_FRAUD_SCENARIO==3].shape(4631, 9)Vamos verificar como o número de transações, o número de transações fraudulentas e o número de cartões comprometidos variam diariamente.
Notebook Cell
def get_stats(transactions_df):
#Number of transactions per day
nb_tx_per_day=transactions_df.groupby(['TX_TIME_DAYS'])['CUSTOMER_ID'].count()
#Number of fraudulent transactions per day
nb_fraud_per_day=transactions_df.groupby(['TX_TIME_DAYS'])['TX_FRAUD'].sum()
#Number of fraudulent cards per day
nb_fraudcard_per_day=transactions_df[transactions_df['TX_FRAUD']>0].groupby(['TX_TIME_DAYS']).CUSTOMER_ID.nunique()
return (nb_tx_per_day,nb_fraud_per_day,nb_fraudcard_per_day)
(nb_tx_per_day,nb_fraud_per_day,nb_fraudcard_per_day)=get_stats(transactions_df)
n_days=len(nb_tx_per_day)
tx_stats=pd.DataFrame({"value":pd.concat([nb_tx_per_day/50,nb_fraud_per_day,nb_fraudcard_per_day])})
tx_stats['stat_type']=["nb_tx_per_day"]*n_days+["nb_fraud_per_day"]*n_days+["nb_fraudcard_per_day"]*n_days
tx_stats=tx_stats.reset_index()Notebook Cell
%%capture
sns.set(style='darkgrid')
sns.set(font_scale=1.4)
fraud_and_transactions_stats_fig = plt.gcf()
fraud_and_transactions_stats_fig.set_size_inches(15, 8)
sns_plot = sns.lineplot(x="TX_TIME_DAYS", y="value", data=tx_stats, hue="stat_type", hue_order=["nb_tx_per_day","nb_fraud_per_day","nb_fraudcard_per_day"], legend=False)
sns_plot.set_title('Total transactions, and number of fraudulent transactions \n and number of compromised cards per day', fontsize=20)
sns_plot.set(xlabel = "Number of days since beginning of data generation", ylabel="Number")
sns_plot.set_ylim([0,300])
labels_legend = ["# transactions per day (/50)", "# fraudulent txs per day", "# fraudulent cards per day"]
sns_plot.legend(loc='upper left', labels=labels_legend,bbox_to_anchor=(1.05, 1), fontsize=15)
fraud_and_transactions_stats_fig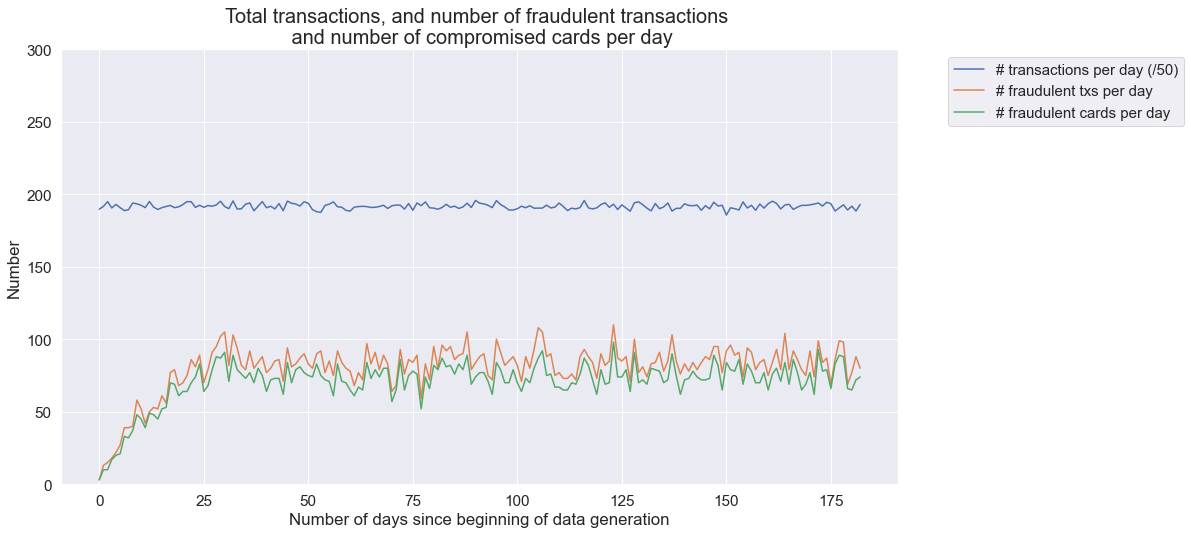
Esta simulação gerou cerca de 10000 transações por dia. O número de transações fraudulentas por dia é de cerca de 85, e o número de cartões fraudulentos cerca de 80. Vale notar que o primeiro mês tem um número menor de transações fraudulentas, o que se deve ao fato de que as fraudes dos cenários 2 e 3 abrangem períodos de 28 e 14 dias, respectivamente.
O conjunto de dados resultante é interessante: apresenta desequilíbrio de classes (menos de 1% de transações fraudulentas), uma mistura de características numéricas e categóricas, relações não triviais entre características e cenários de fraude dependentes do tempo.
Vamos finalmente salvar o conjunto de dados para reutilização no restante deste livro.
Salvamento do conjunto de dados¶
Em vez de salvar todo o conjunto de dados de transações, dividimos o conjunto de dados em lotes diários. Isso permitirá posteriormente o carregamento de períodos específicos em vez de todo o conjunto de dados. O formato pickle é usado, em vez do CSV, para acelerar os tempos de carregamento. Todos os arquivos são salvos na pasta DIR_OUTPUT. Os nomes dos arquivos são as datas, com a extensão .pkl.
DIR_OUTPUT = "./simulated-data-raw/"
if not os.path.exists(DIR_OUTPUT):
os.makedirs(DIR_OUTPUT)
start_date = datetime.datetime.strptime("2018-04-01", "%Y-%m-%d")
for day in range(transactions_df.TX_TIME_DAYS.max()+1):
transactions_day = transactions_df[transactions_df.TX_TIME_DAYS==day].sort_values('TX_TIME_SECONDS')
date = start_date + datetime.timedelta(days=day)
filename_output = date.strftime("%Y-%m-%d")+'.pkl'
# Protocol=4 required for Google Colab
transactions_day.to_pickle(DIR_OUTPUT+filename_output, protocol=4)O conjunto de dados gerado também está disponível no Github em https://github.com/Fraud-Detection-Handbook/simulated-data-raw.