Esta seção reporta os desempenhos obtidos em dados do mundo real usando procedimentos de seleção de modelos. O conjunto de dados é o mesmo do Capítulo 3, Seção 5. Primeiro reportamos o desempenho de treinamento versus o desempenho de teste para árvores de decisão. Em seguida, comparamos os ganhos de desempenho que podem ser obtidos com a validação prequencial, para árvores de decisão, regressão logística, florestas aleatórias e árvores de boosting.
Notebook Cell
# Initialization: Load shared functions and simulated data
# Load shared functions
!curl -O https://raw.githubusercontent.com/Fraud-Detection-Handbook/fraud-detection-handbook/main/Chapter_References/shared_functions.py
%run shared_functions.py
#%run ../Chapter_References/shared_functions.ipynb
# Get simulated data from Github repository
if not os.path.exists("simulated-data-transformed"):
!git clone https://github.com/Fraud-Detection-Handbook/simulated-data-transformed
Desempenho de treinamento versus desempenho de teste¶
Na Seção 2.1 deste capítulo, ilustramos o fenômeno de sobreajuste com árvores de decisão comparando os desempenhos de treinamento e teste quando a profundidade máxima da árvore é aumentada. Realizamos os mesmos experimentos em dados do mundo real e salvamos o DataFrame de desempenho resultante como arquivo Pickle em performances_train_test_real_world_data.pkl. Vamos primeiro carregar o arquivo.
filehandler = open('images/performances_train_test_real_world_data.pkl', 'rb')
performances_df = pickle.load(filehandler)O DataFrame contém as mesmas informações da Seção 2.1, para os dados de transações do mundo real.
Notebook Cell
performances_dfVamos plotar os desempenhos em termos de AUC ROC, Precisão Média e CP@100, usando a função get_performances_plots.
get_performances_plots(performances_df,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Train'],expe_type_color_list=['#008000','#2F4D7E'])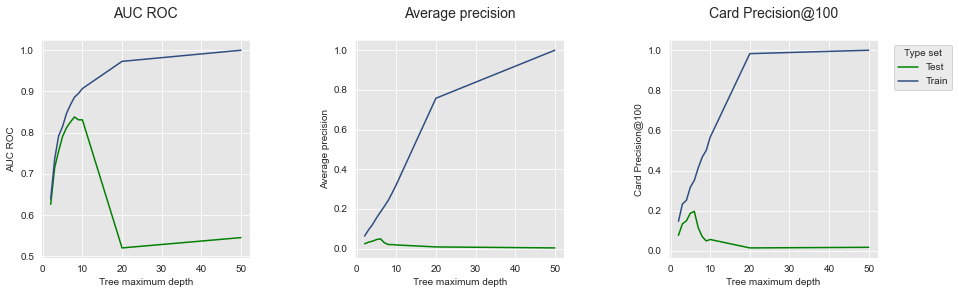
Observamos que os resultados são qualitativamente muito similares aos obtidos nos dados simulados. O fenômeno de sobreajuste está claramente presente: À medida que a profundidade da árvore aumenta, o desempenho também aumenta para todas as métricas (linhas azuis), atingindo desempenhos ótimos para uma profundidade de 50. O desempenho de teste, no entanto, atinge seu pico para uma profundidade de árvore entre 5 e 10, e depois diminui para valores maiores do parâmetro.
Graças à reprodutibilidade dos experimentos, notamos que os desempenhos obtidos para uma profundidade de árvore de 2 e 50 correspondem aos reportados no Capítulo 3.
Desempenhos de modelos por classe de modelo¶
Vamos explorar mais extensivamente como a seleção de modelos melhora os desempenhos usando a validação prequencial em dados do mundo real. Reportamos a seguir os resultados para as quatro classes de modelos, seguindo a mesma configuração experimental da seção anterior. Os resultados estão disponíveis no arquivo Pickle performances_model_selection_real_world_data.pkl. Vamos primeiro carregar o arquivo.
filehandler = open('images/performances_model_selection_real_world_data.pkl', 'rb')
(performances_df_dictionary, execution_times) = pickle.load(filehandler)Os resultados estão no mesmo formato da seção anterior. Os desempenhos são resumidos como um dicionário no performances_df_dictionary, onde as chaves correspondem aos modelos.
performances_df_dictionary.keys()dict_keys(['Decision Tree', 'Random Forest', 'XGBoost', 'Logistic Regression'])Os tempos de execução para cada modelo são armazenados na lista execution_times.
execution_times[1617.0470759868622,
694.7196891307831,
3615.5994658470154,
8788.51293516159,
5527.099639177322]Árvores de decisão¶
Os desempenhos de validação e teste em função da profundidade da árvore são reportados abaixo, juntamente com o resumo dos parâmetros ótimos e desempenhos.
performances_df_dt=performances_df_dictionary['Decision Tree']
summary_performances_dt=get_summary_performances(performances_df_dt, parameter_column_name="Parameters summary")
get_performances_plots(performances_df_dt,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
summary_performances=summary_performances_dt)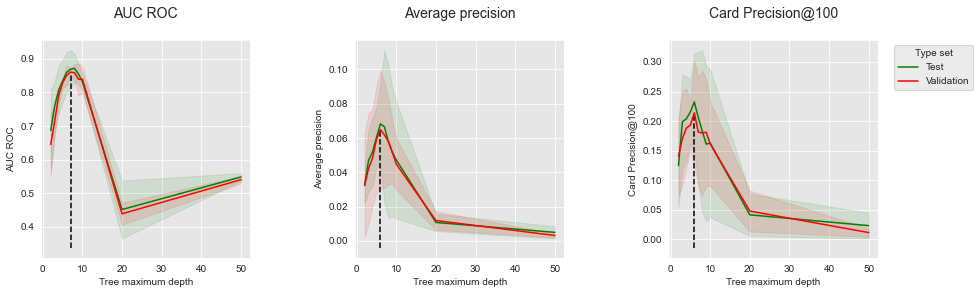
summary_performances_dtSemelhante aos resultados do conjunto de dados simulado, os desempenhos de validação fornecem boas estimativas dos desempenhos de teste. A profundidade ótima da árvore, entre 6 e 9 dependendo da métrica de desempenho, é maior do que com os dados simulados. Isso pode ser explicado pelas relações mais complexas entre as características de entrada e o rótulo de fraude no conjunto de dados do mundo real.
Regressão logística¶
Os desempenhos de validação e teste em função do valor de regularização são reportados abaixo, juntamente com o resumo dos parâmetros ótimos e desempenhos.
performances_df_lr=performances_df_dictionary['Logistic Regression']
summary_performances_lr=get_summary_performances(performances_df_lr, parameter_column_name="Parameters summary")
get_performances_plots(performances_df_lr,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name='Regularization value',
summary_performances=summary_performances_lr)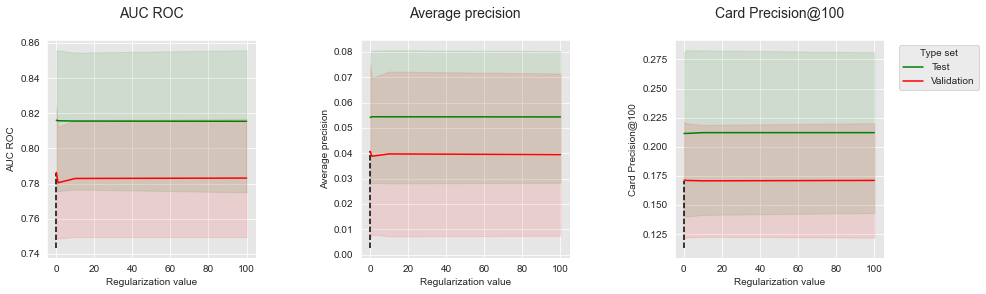
summary_performances_lrSemelhante ao conjunto de dados simulado, o valor de regularização tem pouca influência nos desempenhos. Os desempenhos são estáveis ao longo da faixa de valores de regularização testados.
Floresta aleatória¶
Dois parâmetros diferentes são avaliados para florestas aleatórias: A profundidade da árvore (parâmetro max_depth), assumindo valores no conjunto [5,10,20,50], e o número de árvores (parâmetro n_estimators), assumindo valores no conjunto [25,50,100]. No geral, os parâmetros ótimos são uma combinação de 100 árvores com uma profundidade máxima de 10.
performances_df_rf=performances_df_dictionary['Random Forest']
summary_performances_rf=get_summary_performances(performances_df_rf, parameter_column_name="Parameters summary")
summary_performances_rfPara melhor visualização, seguimos a mesma abordagem do conjunto de dados simulado. Vamos primeiro reportar os desempenhos em função da profundidade da árvore, para um número fixo de 100 árvores.
performances_df_rf_fixed_number_of_trees=performances_df_rf[performances_df_rf["Parameters summary"].str.startswith("100")]
summary_performances_fixed_number_of_trees=get_summary_performances(performances_df_rf_fixed_number_of_trees, parameter_column_name="Parameters summary")
get_performances_plots(performances_df_rf_fixed_number_of_trees,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="Number of trees/Maximum tree depth",
summary_performances=summary_performances_fixed_number_of_trees)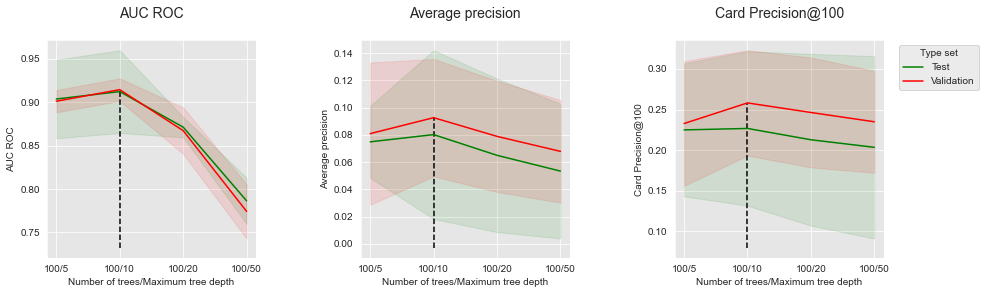
Semelhante ao conjunto de dados simulado, os desempenhos primeiro aumentam com a profundidade da árvore, antes de atingir um ótimo e diminuir. A profundidade ótima da árvore é encontrada em torno de 10.
Vamos então reportar os desempenhos em função do número de árvores, para uma profundidade fixa de 10.
performances_df_rf_fixed_max_tree_depth=performances_df_rf[performances_df_rf["Parameters summary"].str.endswith("10")]
summary_performances_fixed_max_tree_depth=get_summary_performances(performances_df_rf_fixed_max_tree_depth, parameter_column_name="Parameters summary")
get_performances_plots(performances_df_rf_fixed_max_tree_depth,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="Number of trees/Maximum tree depth",
summary_performances=summary_performances_fixed_max_tree_depth)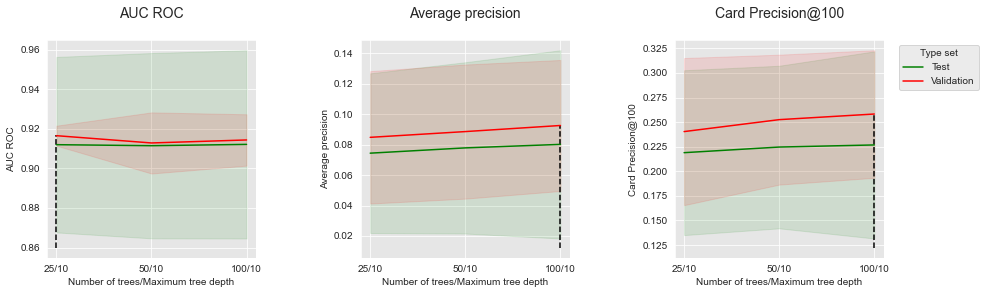
Aumentar o número de árvores permite aumentar ligeiramente a Precisão Média e o CP@100. No entanto, tem pouca influência no AUC ROC, para o qual 25 árvores já fornecem desempenhos ótimos.
XGBoost¶
Três parâmetros diferentes são avaliados para boosting: A profundidade da árvore (parâmetro max_depth) assumindo valores no conjunto [3,6,9], o número de árvores (parâmetro n_estimators) assumindo valores no conjunto [25,50,100] e a taxa de aprendizado (parâmetro learning_rate) assumindo valores no conjunto [0.1, 0.3]. Os parâmetros ótimos são uma combinação de 100 árvores com uma profundidade máxima de 6 e uma taxa de aprendizado de 0,1, exceto para o CP@100 onde 50 árvores fornecem o melhor desempenho.
performances_df_xgboost=performances_df_dictionary['XGBoost']
summary_performances_xgboost=get_summary_performances(performances_df_xgboost, parameter_column_name="Parameters summary")
summary_performances_xgboostPara melhor visualização, seguimos a mesma abordagem do conjunto de dados simulado. Vamos primeiro reportar os desempenhos em função da profundidade da árvore, para um número fixo de 100 árvores e uma taxa de aprendizado de 0,1.
performances_df_xgboost_fixed_number_of_trees=performances_df_xgboost[performances_df_xgboost["Parameters summary"].str.startswith("100/0.1")]
summary_performances_fixed_number_of_trees=get_summary_performances(performances_df_xgboost_fixed_number_of_trees, parameter_column_name="Parameters summary")
get_performances_plots(performances_df_xgboost_fixed_number_of_trees,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="Number of trees/Maximum tree depth",
summary_performances=summary_performances_fixed_number_of_trees)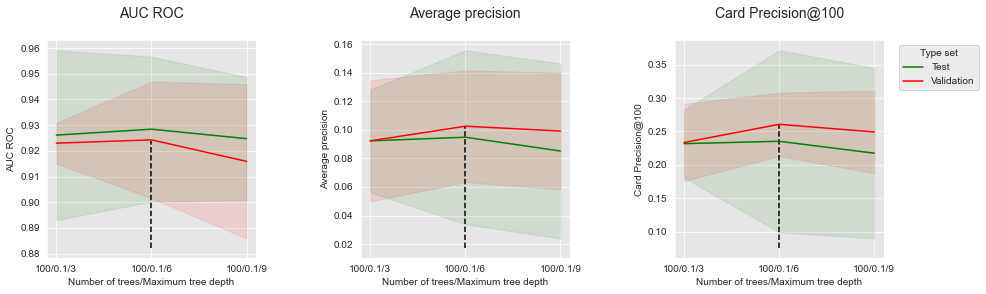
Semelhante ao conjunto de dados simulado, os desempenhos primeiro aumentam com a profundidade da árvore, antes de atingir um ótimo e diminuir. A profundidade ótima da árvore é encontrada em torno de 6.
Vamos então reportar os desempenhos em função do número de árvores, para uma profundidade fixa de 6 e uma taxa de aprendizado de 0,1.
performances_df_xgboost_fixed_max_tree_depth=performances_df_xgboost[performances_df_xgboost["Parameters summary"].str.endswith("0.1/6")]
summary_performances_fixed_max_tree_depth=get_summary_performances(performances_df_xgboost_fixed_max_tree_depth, parameter_column_name="Parameters summary")
get_performances_plots(performances_df_xgboost_fixed_max_tree_depth,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="Number of trees/Maximum tree depth",
summary_performances=summary_performances_fixed_max_tree_depth)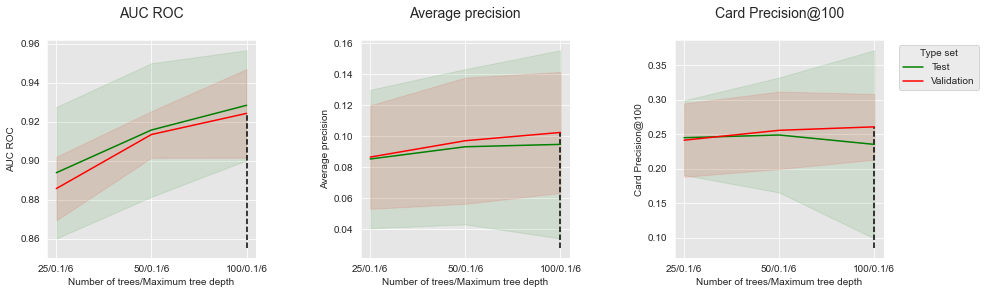
Aumentar o número de árvores permite aumentar o AUC ROC e a Precisão Média. No entanto, notamos que para o CP@100, ocorre uma diminuição de desempenho após 50 árvores para o conjunto de teste.
Comparação de desempenhos de modelos: Resumo¶
Vamos finalmente comparar os desempenhos das diferentes classes de modelos. Semelhante ao conjunto de dados simulado, plotamos os desempenhos para as quatro classes de modelos e para cada métrica de desempenho como gráficos de barras usando a função get_model_selection_performances_plots.
get_model_selection_performances_plots(performances_df_dictionary,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
ylim_list=[[0.5,1],[0,0.2],[0,0.35]],
model_classes=['Decision Tree',
'Logistic Regression',
'Random Forest',
'XGBoost'])
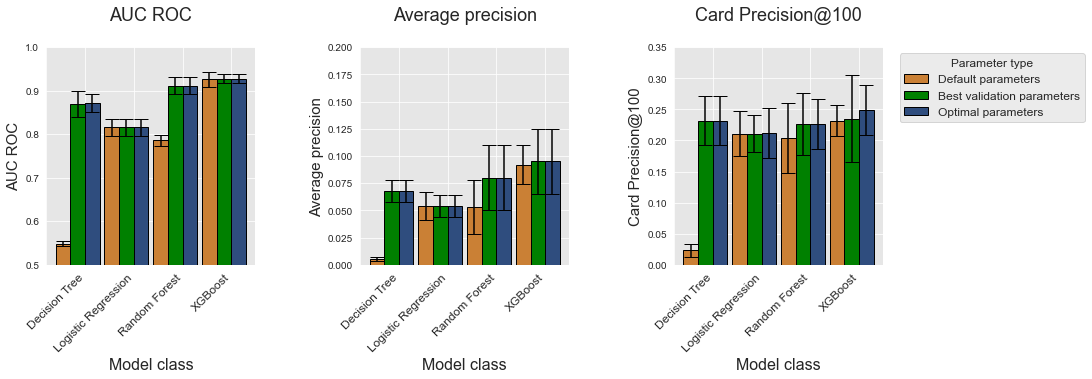
Como nos dados simulados, o XGBoost é a classe de modelo que fornece os melhores desempenhos para as três métricas (parâmetros ótimos, representados com barras azuis). Vale notar, no entanto, que para o CP@100, os parâmetros ótimos do XGBoost não são de fato encontrados pelo procedimento de seleção de modelos, resultando em desempenhos menores. Os desempenhos reais em termos de CP@100 são ligeiramente melhores do que as florestas aleatórias e equivalentes às árvores de decisão.
Este é um resultado que vale a pena considerar: Graças à seleção de modelos, o modelo de árvore de decisão é tão eficiente quanto o XGBoost, e mais eficiente do que as florestas aleatórias em termos de CP@100. Os tempos de execução para árvores de decisão são, no entanto, muito menores do que os de florestas aleatórias e XGBoost, como reportado abaixo.
Notebook Cell
%%capture
fig_model_selection_execution_times_for_each_model_class, ax = plt.subplots(1, 1, figsize=(5,4))
model_classes=['Decision Tree','Logistic Regression','Random Forest','XGBoost']
# width of the bars
barWidth = 0.3
# The x position of bars
r1 = np.arange(len(model_classes))
# Create execution times bars
ax.bar(r1, execution_times[0:4],
width = barWidth, color = 'black', edgecolor = 'black',
capsize=7)
ax.set_xticks(r1+barWidth/2)
ax.set_xticklabels(model_classes, rotation = 45, ha="right", fontsize=12)
ax.set_title('Model selection execution times \n for different model classes', fontsize=18)
ax.set_xlabel("Model class", fontsize=16)
ax.set_ylabel("Execution times (s)", fontsize=15)
fig_model_selection_execution_times_for_each_model_class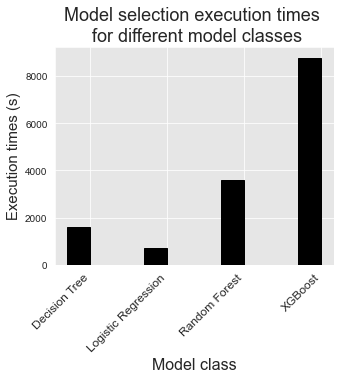
Deve-se ter em mente que os experimentos foram realizados em um servidor de 40 núcleos, com computação paralela habilitada para florestas aleatórias e XGBoost. Portanto, o procedimento de seleção de modelos para árvores de decisão é de fato uma a duas ordens de magnitude mais rápido do que para florestas aleatórias e XGBoost.
Como observação final, notamos que os modelos de regressão logística foram os mais rápidos de treinar, mas também forneceram os piores desempenhos para todas as métricas.