A detecção de fraudes em cartões de crédito (CCFD) é como procurar agulhas em um palheiro. Requer encontrar, entre milhões de transações diárias, quais são fraudulentas. Devido à quantidade cada vez maior de dados, agora é quase impossível para um especialista humano detectar padrões significativos a partir dos dados de transação. Por esse motivo, o uso de técnicas de aprendizado de máquina agora é generalizado no campo de detecção de fraudes, onde a extração de informações de grandes conjuntos de dados é necessária Lucas & Jurgovsky (2020)Priscilla & Prabha (2019)Carcillo (2018)Dal Pozzolo (2015).
O Aprendizado de Máquina (ML) é o estudo de algoritmos que melhoram automaticamente por meio da experiência Bontempi (2021)Friedman et al. (2001). O ML está intimamente relacionado aos campos da Estatística, Reconhecimento de Padrões e Mineração de Dados. Ao mesmo tempo, surge como um subcampo da ciência da computação e da inteligência artificial e dá atenção especial à parte algorítmica do processo de extração de conhecimento. O ML desempenha um papel fundamental em muitas disciplinas científicas e suas aplicações fazem parte de nossa vida diária. É usado, por exemplo, para filtrar spam de e-mail, para previsão do tempo, em diagnóstico médico, recomendação de produtos, detecção de rosto, detecção de fraude, etc Dal Pozzolo (2015)Bishop (2006).
A capacidade das técnicas de ML de enfrentar efetivamente os desafios levantados pela CCFD levou a um grande e crescente corpo de pesquisa na última década. Conforme relatado na Fig. 1, milhares de artigos relacionados a este tópico foram publicados entre 2010 e 2020, com cerca de 1500 artigos publicados apenas em 2020.
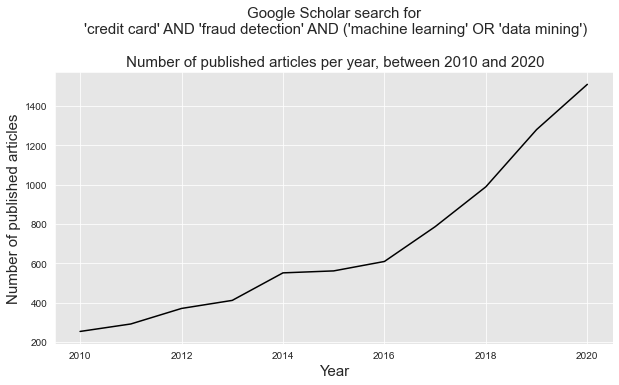
Fig. 1. Número de artigos publicados sobre o tema aprendizado de máquina e detecção de fraude em cartão de crédito entre 2010 e 2020. Fonte: Google Scholar.
Esta seção tem como objetivo fornecer uma visão geral deste corpo de pesquisa recente, resumindo os principais desafios de pesquisa e os principais conceitos de aprendizado de máquina que podem ser usados para resolvê-los.
Pesquisas recentes¶
Para ter uma ideia do estado atual da pesquisa sobre ML para CCFD, pesquisamos no Google Scholar todas as revisões e pesquisas feitas sobre este tópico nos últimos cinco anos. Usando a seguinte pesquisa booleana: ("machine learning" OR "data mining") AND "credit card" AND "fraud detection" AND (review OR survey) e restringindo o período de pesquisa de 2015 a 2021, identificamos dez revisões/pesquisas que relatamos na tabela a seguir.
| Título | Data | Referência |
|---|---|---|
| Uma pesquisa sobre técnicas de detecção de fraude em cartão de crédito: Perspectiva orientada a dados e técnicas | 2016 | Zojaji et al. (2016) |
| Uma pesquisa sobre técnicas de detecção de fraude em cartão de crédito baseadas em aprendizado de máquina e inspiradas na natureza | 2017 | Adewumi & Akinyelu (2017) |
| Uma pesquisa sobre detecção de fraude em cartão de crédito usando aprendizado de máquina | 2018 | Popat & Chaudhary (2018) |
| Uma revisão do estado da arte das técnicas de aprendizado de máquina para pesquisa de detecção de fraudes | 2018 | Sinayobye et al. (2018) |
| Detecção de fraude em cartão de crédito: Estado da arte | 2018 | Sadgali et al. (2018) |
| Uma pesquisa sobre diferentes métodos de mineração de dados e aprendizado de máquina para detecção de fraude em cartão de crédito | 2018 | Patil & Lilhore (2018) |
| Uma revisão sistemática das abordagens de mineração de dados para detecção de fraude em cartão de crédito | 2018 | Mekterović et al. (2018) |
| Uma pesquisa abrangente sobre técnicas de aprendizado de máquina e abordagens de autenticação de usuário para detecção de fraude em cartão de crédito | 2019 | Yousefi et al. (2019) |
| Detecção de fraude em cartão de crédito: uma revisão sistemática | 2019 | Priscilla & Prabha (2019) |
| Detecção de fraude em cartão de crédito usando aprendizado de máquina: Uma pesquisa | 2020 | Lucas & Jurgovsky (2020) |
Um conjunto de dez pesquisas em cinco anos pode ser considerado alto. O fato de tantas pesquisas terem sido publicadas em um período tão curto (em particular para as cinco pesquisas publicadas em 2018) reflete a rápida evolução do tópico de ML para CCFD e a necessidade que equipes de pesquisadores independentes sentiram em sintetizar o estado da pesquisa neste campo.
Dado o objetivo comum dessas pesquisas, vale a pena notar que um alto grau de redundância pode ser encontrado em termos de conteúdo. Em particular, todas elas enfatizam um conjunto comum de metodologias e desafios, que apresentamos nas próximas duas seções. Primeiro, cobrimos a metodologia de linha de base, ou seja, o fluxo de trabalho comum que é normalmente seguido em artigos que tratam do uso de técnicas de ML para abordar a CCFD. Em seguida, resumimos os desafios que caracterizam este tópico.
Metodologia de linha de base - Aprendizado supervisionado¶
Um grande número de técnicas de ML pode ser usado para resolver o problema da CCFD. Isso se reflete diretamente na enorme quantidade de artigos publicados sobre o tema na última década. Apesar desse grande volume de trabalhos de pesquisa, a maioria das abordagens propostas segue uma metodologia de ML de linha de base comum Patil & Lilhore (2018)Friedman et al. (2001)Bishop (2006), que resumimos na Fig. 2.
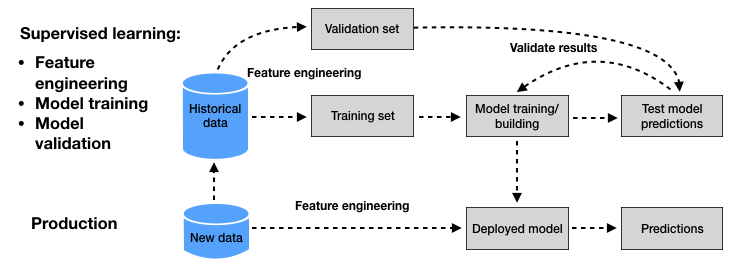
Fig. 2. ML para CCFD: Metodologia de linha de base seguida pela maioria das abordagens propostas nas pesquisas recentes sobre o tema.
Na detecção de fraudes em cartões de crédito, os dados geralmente consistem em dados de transação, coletados, por exemplo, por um processador de pagamentos ou um banco. Os dados da transação podem ser divididos em três grupos Lucas & Jurgovsky (2020)Adewumi & Akinyelu (2017)Van Vlasselaer et al. (2015)
Características relacionadas à conta: incluem, por exemplo, o número da conta, a data de abertura da conta, o limite do cartão, a data de validade do cartão, etc.
Características relacionadas à transação: incluem, por exemplo, o número de referência da transação, o número da conta, o valor da transação, o número do terminal (ou seja, POS), a hora da transação, etc. Do terminal, também se pode obter uma categoria adicional de informações: características relacionadas ao comerciante, como seu código de categoria (restaurante, supermercado, ...) ou sua localização.
Características relacionadas ao cliente: incluem, por exemplo, o número do cliente, o tipo de cliente (perfil baixo, perfil alto, ...), etc.
Em sua forma mais simples, uma transação de cartão de pagamento consiste em qualquer valor pago a um comerciante por um cliente em um determinado momento. Um conjunto de dados históricos de transações pode ser representado como uma tabela, como ilustrado na Fig. 3. Para detecção de fraudes, também é geralmente assumido que a legitimidade de todas as transações é conhecida (ou seja, se a transação foi genuína ou fraudulenta). Isso geralmente é representado por um rótulo binário, com valor 0 para uma transação genuína e valor 1 para transações fraudulentas.
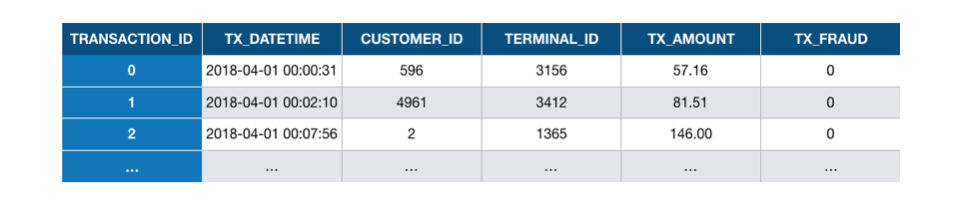
Fig. 3. Exemplo de dados de transação representados como uma tabela. Cada linha corresponde a uma transação de um cliente para um terminal. A última variável é o rótulo, que indica se a transação foi genuína (0) ou fraudulenta (1).
Dois estágios podem ser distinguidos no projeto de um sistema de detecção de fraudes baseado em ML. O primeiro estágio consiste em construir um modelo de predição a partir de um conjunto de dados históricos rotulados (Fig. 2, parte superior). Este processo é chamado de aprendizado supervisionado, uma vez que o rótulo das transações (genuínas ou fraudulentas) é conhecido. No segundo estágio, o modelo de predição obtido do processo de aprendizado supervisionado é usado para prever o rótulo de novas transações (Fig. 2, parte inferior).
Formalmente, um modelo de predição é uma função paramétrica com parâmetros , também chamada de hipótese, que recebe uma entrada de um domínio de entrada e produz uma predição sobre um domínio de saída Carcillo (2018)Dal Pozzolo (2015):
O domínio de entrada geralmente difere do espaço de dados brutos de transação por dois motivos. Primeiro, por razões matemáticas, a maioria dos algoritmos de aprendizado supervisionado exige que o domínio de entrada seja de valor real, ou seja, , o que requer a transformação de características de transação que não são números reais (como timestamps, variáveis
Para detecção de fraudes, o domínio de saída geralmente é a classe prevista para uma determinada entrada , ou seja, . Dado que a classe de saída é binária, esses modelos de predição também são chamados de classificadores binários. Alternativamente, a saída também pode ser expressa como uma probabilidade de fraude, com , ou mais geralmente como uma pontuação de risco, com , onde valores mais altos expressam riscos maiores de fraude.
O treinamento (ou construção) de um modelo de predição consiste em encontrar os parâmetros que fornecem o melhor desempenho. O desempenho de um modelo de predição é avaliado usando uma função de perda, que compara o rótulo verdadeiro com o rótulo previsto para uma entrada . Em problemas de classificação binária, uma função de perda comum é a função de perda zero/um , que atribui uma perda igual a um no caso de predição errada e zero caso contrário:
Para obter uma estimativa justa do desempenho de um modelo de predição, uma prática metodológica importante, conhecida como validação, é avaliar o desempenho de um modelo de predição em dados que não foram usados
O procedimento de aprendizado supervisionado normalmente consiste em treinar um conjunto de modelos de predição e estimar seus desempenhos usando o conjunto de validação. No final do procedimento, o modelo que se presume fornecer o melhor desempenho (ou seja, a menor perda no conjunto de validação) é selecionado e usado para fornecer previsões sobre novas transações (consulte a Fig. 2).
Existe uma vasta gama de métodos para projetar e treinar modelos de predição. Isso explica em parte a grande literatura de pesquisa sobre ML para CCFD, onde os artigos geralmente se concentram em um ou dois métodos de predição. A pesquisa de Priscilla et al. em 2019 Priscilla & Prabha (2019) fornece uma boa visão geral dos métodos de aprendizado de máquina que foram considerados para o problema da CCFD. A pesquisa deles cobriu cerca de cem artigos de pesquisa, identificando para cada artigo quais técnicas de ML foram usadas, veja a Fig. 4.
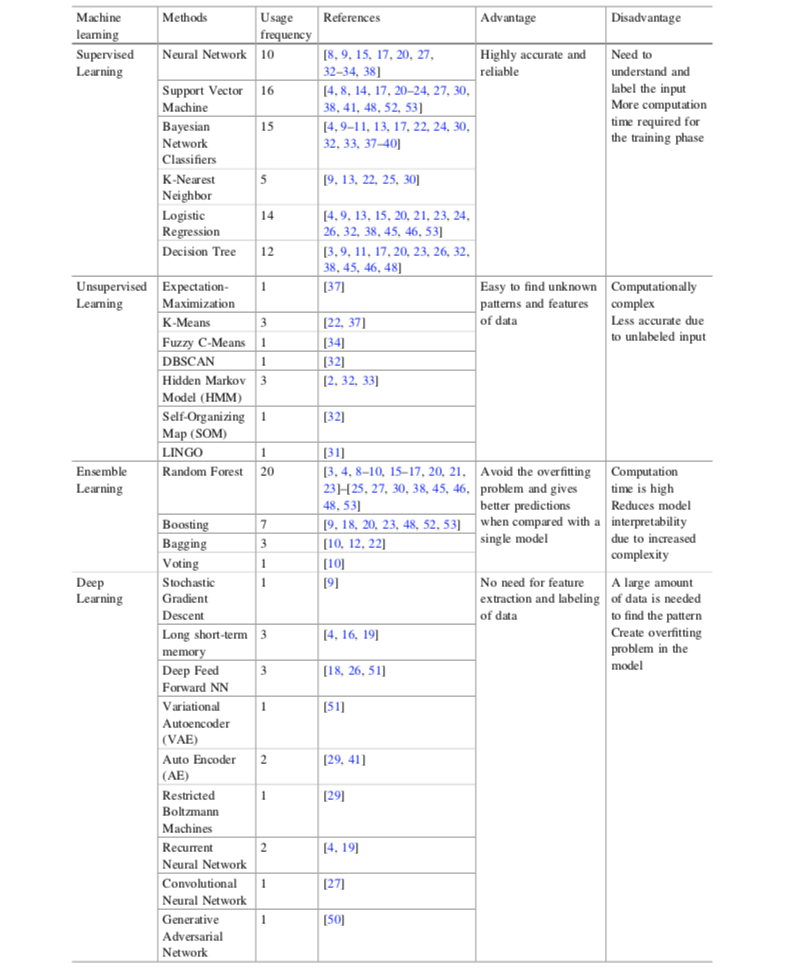
Fig. 4. Frequência de uso de técnicas de ML na CCFD. Fonte: Priscilla et al., 2019 {cite}`priscilla2019credit`. As referências fornecidas na tabela estão em {cite}`priscilla2019credit`.
A classificação das técnicas de aprendizado em categorias de ‘alto nível’ não é um exercício simples, pois muitas vezes existem conexões metodológicas, algorítmicas ou históricas entre elas. Priscilla et al. optaram por dividir as abordagens em quatro grupos: aprendizado supervisionado, aprendizado não supervisionado, aprendizado de conjunto e aprendizado profundo. Pode-se argumentar que o aprendizado de conjunto e o aprendizado profundo fazem parte do aprendizado supervisionado, uma vez que exigem que os rótulos sejam conhecidos. Além disso, o aprendizado profundo e as redes neurais podem ser considerados parte da mesma categoria.
Cobrir todas as técnicas de ML está fora do escopo deste livro. Em vez disso, nosso objetivo é fornecer uma estrutura de referência e reproduzível para a CCFD. Decidimos, com base em nossos trabalhos de pesquisa, cobrir cinco tipos de métodos: regressão logística (LR), árvores de decisão (DT), florestas aleatórias (RF), Boosting e redes neurais/aprendizado profundo (NN/DL). LR e DT foram escolhidos devido à sua simplicidade e interpretabilidade. RF e Boosting foram escolhidos por serem atualmente considerados o estado da arte em termos de desempenho. Os métodos NN/DL foram escolhidos por fornecerem direções de pesquisa promissoras.
Visão geral dos desafios¶
A CCFD com ML é um problema notoriamente difícil. Resumimos abaixo os desafios comumente destacados nas revisões sobre o tópico Lucas & Jurgovsky (2020)Priscilla & Prabha (2019)Mekterović et al. (2018)Adewumi & Akinyelu (2017)Zojaji et al. (2016).
Desequilíbrio de classes: os dados da transação contêm muito mais transações legítimas do que fraudulentas: a porcentagem de transações fraudulentas em um conjunto de dados do mundo real é normalmente bem inferior a 1%. Aprender com dados desequilibrados é uma tarefa difícil, pois a maioria dos algoritmos de aprendizado não lida bem com grandes diferenças entre as classes. Lidar com o desequilíbrio de classes requer o uso de estratégias de aprendizado adicionais, como amostragem ou ponderação de perdas, um tópico conhecido como aprendizagem desbalanceada.
Desvio de conceito: os padrões de transação e fraude mudam com o tempo. Por um lado, os hábitos de consumo dos usuários de cartão de crédito são diferentes durante a semana, fins de semana, períodos de férias e, de modo mais geral, evoluem com o tempo. Por outro lado, os fraudadores adotam novas técnicas à medida que as antigas se tornam obsoletas. Essas mudanças dependentes do tempo nas distribuições de transações e fraudes são chamadas de desvio de conceito. O desvio de conceito requer o projeto de estratégias de aprendizado que possam lidar com mudanças temporais nas distribuições estatísticas, um tópico conhecido como aprendizado online. O problema do desvio de conceito é acentuado na prática pelos feedbacks atrasados (consulte a seção Sistema de detecção de fraude de cartão de crédito).
Requisitos de tempo quase real: os sistemas de detecção de fraude devem ser capazes de detectar rapidamente transações fraudulentas. Dado o volume potencialmente alto de dados de transação (milhões de transações por dia), podem ser necessários tempos de classificação tão baixos quanto dezenas de milissegundos. Este desafio está intimamente relacionado à paralelização e escalabilidade dos sistemas de detecção de fraude.
Recursos categóricos: os dados transacionais geralmente contêm vários recursos categóricos, como o ID de um cliente, um terminal, o tipo de cartão e assim por diante. Os recursos categóricos não são bem tratados pelos algoritmos de aprendizado de máquina e devem ser transformados em recursos numéricos. As estratégias comuns para transformar recursos categóricos incluem agregação de recursos, transformação baseada em grafos ou abordagens de aprendizado profundo, como incorporação de recursos.
Modelagem sequencial: cada terminal e/ou cliente gera um fluxo de dados sequenciais com características únicas. Um desafio importante da detecção de fraudes consiste em modelar esses fluxos para caracterizar melhor seus comportamentos esperados e detectar quando ocorrem comportamentos anormais. A modelagem pode ser feita agregando recursos ao longo do tempo (por exemplo, acompanhando a frequência média ou os valores de transação de um cliente) ou contando com modelos de predição sequencial (como modelos ocultos de Markov ou redes neurais recorrentes, por exemplo).
Sobreposição de classes: os dois últimos desafios podem ser associados ao desafio mais geral de sobreposição entre as duas classes. Apenas com informações brutas sobre uma transação, distinguir entre uma transação fraudulenta ou genuína é quase impossível. Esse problema é comumente resolvido usando técnicas de engenharia de recursos, que adicionam informações contextuais às informações de pagamento brutas.
Medidas de desempenho: as medidas padrão para sistemas de classificação, como o erro médio de classificação incorreta ou a AUC ROC, não são adequadas para problemas de detecção devido ao problema de desequilíbrio de classes e à complexa estrutura de custos da detecção de fraudes. Um sistema de detecção de fraudes deve ser capaz de maximizar a detecção de transações fraudulentas e, ao mesmo tempo, minimizar o número de fraudes previstas incorretamente (falsos positivos). Muitas vezes, é necessário considerar várias medidas para avaliar o desempenho geral de um sistema de detecção de fraudes. Apesar de seu papel central no projeto de um sistema de detecção de fraudes, atualmente não há consenso sobre qual conjunto de medidas de desempenho deve ser usado.
Falta de conjuntos de dados públicos: por razões óbvias de confidencialidade, as transações de cartão de crédito do mundo real não podem ser compartilhadas publicamente. Existe apenas um conjunto de dados compartilhado publicamente, que foi disponibilizado no Kaggle Kaggle (2016) por nossa equipe em 2016. Apesar de suas limitações (apenas dois dias de dados e recursos ofuscados), o conjunto de dados tem sido amplamente utilizado na literatura de pesquisa e é um dos mais votados e baixados no Kaggle. A escassez de conjuntos de dados para detecção de fraudes também é verdadeira com dados simulados: ainda não há simuladores ou conjuntos de dados simulados de referência disponíveis. Como resultado, a maioria dos trabalhos de pesquisa não pode ser reproduzida, tornando impossível a comparação de diferentes técnicas por pesquisadores independentes.
- Lucas, Y., & Jurgovsky, J. (2020). Credit card fraud detection using machine learning: A survey. arXiv Preprint arXiv:2010.06479.
- Priscilla, C. V., & Prabha, D. P. (2019). Credit Card Fraud Detection: A Systematic Review. International Conference on Information, Communication and Computing Technology, 290–303.
- Carcillo, F. (2018). Beyond Supervised Learning in Credit Card Fraud Detection: A Dive into Semi-supervised and Distributed Learning. Université libre de Bruxelles.
- Dal Pozzolo, A. (2015). Adaptive machine learning for credit card fraud detection. Université libre de Bruxelles.
- Bontempi, G. (2021). Statistical foundations of machine learning, 2nd edition. Université Libre de Bruxelles.
- Friedman, J., Hastie, T., & Tibshirani, R. (2001). The elements of statistical learning (Vol. 1). Springer series in statistics New York.
- Bishop, C. M. (2006). Pattern recognition and machine learning. springer.
- Zojaji, Z., Atani, R. E., Monadjemi, A. H., & others. (2016). A survey of credit card fraud detection techniques: data and technique oriented perspective. arXiv Preprint arXiv:1611.06439.
- Adewumi, A. O., & Akinyelu, A. A. (2017). A survey of machine-learning and nature-inspired based credit card fraud detection techniques. International Journal of System Assurance Engineering and Management, 8(2), 937–953.
- Popat, R. R., & Chaudhary, J. (2018). A survey on credit card fraud detection using machine learning. 2018 2nd International Conference on Trends in Electronics and Informatics (ICOEI), 1120–1125.
- Sinayobye, J. O., Kiwanuka, F., & Kyanda, S. K. (2018). A state-of-the-art review of machine learning techniques for fraud detection research. 2018 IEEE/ACM Symposium on Software Engineering in Africa (SEiA), 11–19.
- Sadgali, I., Sael, N., & Benabbou, F. (2018). Detection of credit card fraud: State of art. International Journal of Computer Science and Network Security, 18(11), 76–83.
- Patil, V., & Lilhore, U. K. (2018). A survey on different data mining & machine learning methods for credit card fraud detection. International Journal of Scientific Research in Computer Science, Engineering and Information Technology, 3(5), 320–325.
- Mekterović, I., Brkić, L., & Baranović, M. (2018). A systematic review of data mining approaches to credit card fraud detection. WSEAS Transactions on Business and Economics, 15, 437–444.
- Yousefi, N., Alaghband, M., & Garibay, I. (2019). A Comprehensive Survey on Machine Learning Techniques and User Authentication Approaches for Credit Card Fraud Detection. arXiv Preprint arXiv:1912.02629.