Esta seção relata os desempenhos obtidos em dados do mundo real usando arquiteturas de redes neurais. O conjunto de dados é o mesmo do Capítulo 3, Seção 5. Os resultados são relatados seguindo a metodologia de busca em grade prequencial usada nas seções anteriores com dados simulados.
Primeiramente relatamos os desempenhos da rede neural feed-forward, da rede neural convolucional, da memória de longa e curta duração e do LSTM com Atenção. Também consideramos variações nos hiperparâmetros:
Rede Neural Feed-forward: 2 camadas, 500 neurônios, nível de dropout de 0 ou 0,2, Adam com taxa de aprendizado de 0,001 ou 0,0001, 5, 10 ou 20 épocas e tamanho de lote de 64, 128 ou 256.Rede Neural Convolucional: 2 camadas convolucionais com 200 filtros de tamanho 2, 1 camada oculta com 500 neurônios, nível de dropout de 0 ou 0,2, Adam com taxa de aprendizado de 0,001 ou 0,0001, 5, 10 ou 20 épocas e tamanho de lote de 64, 128 ou 256.Memória de Longa e Curta Duração: 1 camada recorrente com 200 neurônios para o estado oculto, 1 camada oculta com 500 neurônios, nível de dropout de 0 ou 0,2, Adam com taxa de aprendizado de 0,001 ou 0,0001, 5, 10 ou 20 épocas e tamanho de lote de 64, 128 ou 256.Memória de Longa e Curta Duração com Atenção: 1 camada recorrente com 200 neurônios para o estado oculto, 1 camada oculta com 500 neurônios, nível de dropout de 0 ou 0,2, Adam com taxa de aprendizado de 0,001 ou 0,0001, 5, 10 ou 20 épocas e tamanho de lote de 64, 128 ou 256.
Por fim, relatamos os resultados globais e os comparamos com as outras linhas de base supervisionadas (árvore de decisão, regressão logística, floresta aleatória e XGBoost).
# Initialization: Load shared functions
# Load shared functions
!curl -O https://raw.githubusercontent.com/Fraud-Detection-Handbook/fraud-detection-handbook/main/Chapter_References/shared_functions.py
%run shared_functions.py
#%run ../Chapter_References/shared_functions.ipynbRede neural feed-forward¶
filehandler = open('performances_model_selection_nn_real_data.pkl', 'rb')
(performances_df_dictionary, execution_times) = pickle.load(filehandler)Os resultados da rede feed-forward são apresentados abaixo. Vamos primeiro analisar as tendências globais com o resumo de desempenho.
performances_df_nn = performances_df_dictionary['Neural Network']summary_performances_nn=get_summary_performances(performances_df_nn, parameter_column_name="Parameters summary")
summary_performances_nnAssim como para os dados sintéticos, o conjunto ótimo de hiperparâmetros depende fortemente da métrica. A menor taxa de aprendizado 0.0001 e o maior número de épocas 20 são ligeiramente favorecidos. Vamos considerar esses valores e visualizar o impacto do tamanho do lote e do nível de dropout.
parameters_dict=dict(performances_df_nn['Parameters'])
performances_df_nn['Parameters summary']=[
str(parameters_dict[i]['clf__batch_size'])
for i in range(len(parameters_dict))]
performances_df_nn_subset = performances_df_nn[performances_df_nn['Parameters'].apply(lambda x:x['clf__lr']== 0.0001 and x['clf__module__hidden_size']==500 and x['clf__module__num_layers']==2 and x['clf__module__p']==0.2 and x['clf__max_epochs']==20).values]
summary_performances_nn_subset=get_summary_performances(performances_df_nn_subset, parameter_column_name="Parameters summary")
indexes_summary = summary_performances_nn_subset.index.values
indexes_summary[0] = 'Best estimated parameters'
summary_performances_nn_subset.rename(index = dict(zip(np.arange(len(indexes_summary)),indexes_summary)))
get_performances_plots(performances_df_nn_subset,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="batch size",
summary_performances=summary_performances_nn_subset)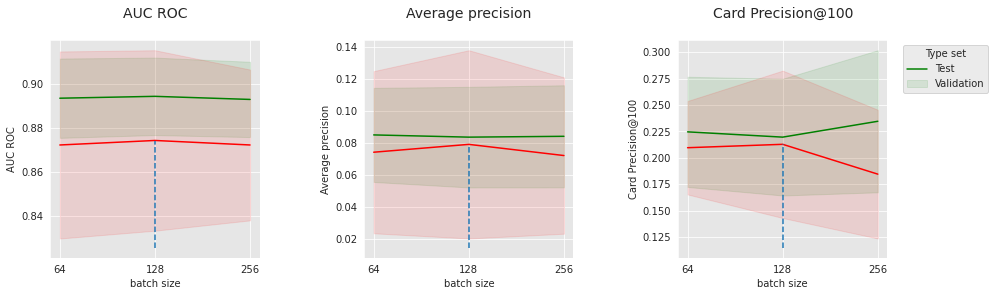
parameters_dict=dict(performances_df_nn['Parameters'])
performances_df_nn['Parameters summary']=[
str(parameters_dict[i]['clf__module__p'])
for i in range(len(parameters_dict))]
performances_df_nn_subset = performances_df_nn[performances_df_nn['Parameters'].apply(lambda x:x['clf__lr']== 0.0001 and x['clf__module__hidden_size']==500 and x['clf__module__num_layers']==2 and x['clf__max_epochs']==20 and x['clf__batch_size']==128).values]
summary_performances_nn_subset=get_summary_performances(performances_df_nn_subset, parameter_column_name="Parameters summary")
indexes_summary = summary_performances_nn_subset.index.values
indexes_summary[0] = 'Best estimated parameters'
summary_performances_nn_subset.rename(index = dict(zip(np.arange(len(indexes_summary)),indexes_summary)))
get_performances_plots(performances_df_nn_subset,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
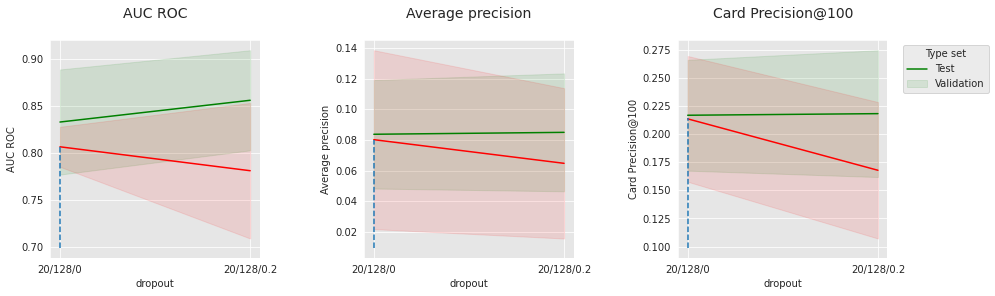
parameter_name="Dropout",
summary_performances=summary_performances_nn_subset)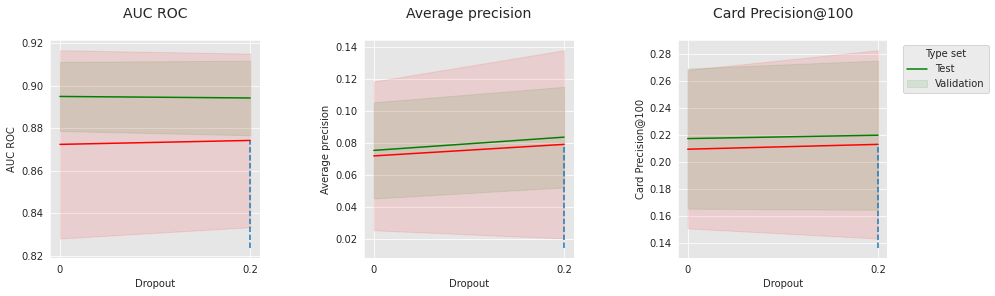
Semelhante aos resultados em dados sintéticos, esses hiperparâmetros relacionados à otimização todos têm pontos ótimos que dependem uns dos outros. Isso confirma a importância do ajuste para este tipo de modelo.
No geral, nossa simples rede neural feed-forward alcança um desempenho competitivo. É comparável à linha de base da Floresta Aleatória nos dados do mundo real (comparação global ao final), o que é muito promissor para aplicações em sistemas de detecção de fraude incremental.
Modelos sequenciais¶
Vamos agora analisar o desempenho dos modelos sequenciais em dados do mundo real em relação a alguns de seus parâmetros de otimização.
filehandler = open('performances_model_selection_seq_model_real_data.pkl', 'rb')
(performances_df_dictionary_seq_model, execution_times) = pickle.load(filehandler)performances_df_cnn=performances_df_dictionary_seq_model['CNN']
summary_performances_cnn=get_summary_performances(performances_df_cnn, parameter_column_name="Parameters summary")
performances_df_lstm=performances_df_dictionary_seq_model['LSTM']
summary_performances_lstm=get_summary_performances(performances_df_lstm, parameter_column_name="Parameters summary")
performances_df_lstm_attn=performances_df_dictionary_seq_model['LSTM_Attention']
summary_performances_lstm_attn=get_summary_performances(performances_df_lstm_attn, parameter_column_name="Parameters summary")Rede Neural Convolucional¶
Começamos com a rede neural convolucional 1D. O resumo de desempenho e o impacto do tamanho do lote, número de épocas e dropout são analisados.
summary_performances_cnnparameters_dict=dict(performances_df_cnn['Parameters'])
performances_df_cnn['Parameters summary']=[str(parameters_dict[i]['clf__max_epochs'])+
'/'+
str(parameters_dict[i]['clf__batch_size'])+
'/'+
str(parameters_dict[i]['clf__module__p'])
for i in range(len(parameters_dict))]
performances_df_cnn_subset = performances_df_cnn[performances_df_cnn['Parameters'].apply(lambda x:x['clf__lr']== 0.0001 and x['clf__module__num_filters']==200 and x['clf__max_epochs']==10 and x['clf__module__num_conv']==2 and x['clf__module__p']==0.2).values]
summary_performances_cnn_subset=get_summary_performances(performances_df_cnn_subset, parameter_column_name="Parameters summary")
indexes_summary = summary_performances_cnn_subset.index.values
indexes_summary[0] = 'Best estimated parameters'
summary_performances_cnn_subset.rename(index = dict(zip(np.arange(len(indexes_summary)),indexes_summary)))
get_performances_plots(performances_df_cnn_subset,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="batch size",
summary_performances=summary_performances_cnn_subset)
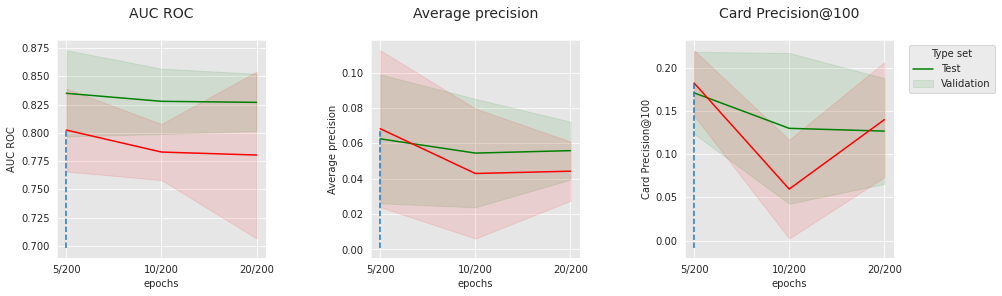
performances_df_cnn_subset = performances_df_cnn[performances_df_cnn['Parameters'].apply(lambda x:x['clf__lr']== 0.0001 and x['clf__module__num_filters']==200 and x['clf__batch_size']==128 and x['clf__module__num_conv']==2 and x['clf__module__p']==0.2).values]
summary_performances_cnn_subset=get_summary_performances(performances_df_cnn_subset, parameter_column_name="Parameters summary")
indexes_summary = summary_performances_cnn_subset.index.values
indexes_summary[0] = 'Best estimated parameters'
summary_performances_cnn_subset.rename(index = dict(zip(np.arange(len(indexes_summary)),indexes_summary)))
get_performances_plots(performances_df_cnn_subset,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="epochs",
summary_performances=summary_performances_cnn_subset)
performances_df_cnn_subset = performances_df_cnn[performances_df_cnn['Parameters'].apply(lambda x:x['clf__lr']== 0.0001 and x['clf__module__num_filters']==200 and x['clf__batch_size']==128 and x['clf__module__num_conv']==2 and x['clf__max_epochs']==20).values]
summary_performances_cnn_subset=get_summary_performances(performances_df_cnn_subset, parameter_column_name="Parameters summary")
indexes_summary = summary_performances_cnn_subset.index.values
indexes_summary[0] = 'Best estimated parameters'
summary_performances_cnn_subset.rename(index = dict(zip(np.arange(len(indexes_summary)),indexes_summary)))
get_performances_plots(performances_df_cnn_subset,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="dropout",
summary_performances=summary_performances_cnn_subset)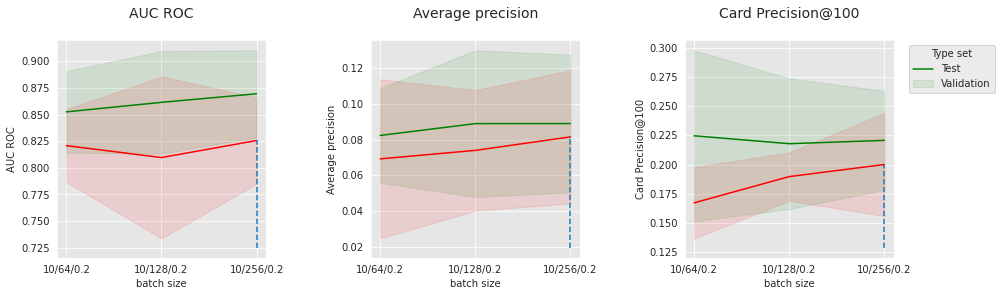
Semelhante à rede neural regular, o desempenho depende altamente dos parâmetros de otimização. Um pequeno nível de dropout parece ser benéfico, em particular no conjunto de teste, onde a distribuição está mais distante da distribuição de treinamento.
No geral, exceto pela AUC ROC, a rede neural convolucional 1D é capaz de superar a rede neural feed-forward e obter uma Precisão Média muito competitiva.
Memória de Longa e Curta Duração (LSTM)¶
Vamos continuar com o LSTM.
summary_performances_lstmA memória de longa e curta duração globalmente supera a rede neural convolucional nos conjuntos de teste e obtém a melhor precisão média no geral.
parameters_dict=dict(performances_df_lstm['Parameters'])
performances_df_lstm['Parameters summary']=[str(parameters_dict[i]['clf__max_epochs'])
for i in range(len(parameters_dict))]
performances_df_lstm_subset = performances_df_lstm[performances_df_lstm['Parameters'].apply(lambda x:x['clf__lr']== 0.0001 and x['clf__batch_size']==256 and x['clf__module__hidden_size_lstm']==200 and x['clf__module__p']==0.2).values]
summary_performances_lstm_subset=get_summary_performances(performances_df_lstm_subset, parameter_column_name="Parameters summary")
indexes_summary = summary_performances_lstm_subset.index.values
indexes_summary[0] = 'Best estimated parameters'
summary_performances_lstm_subset.rename(index = dict(zip(np.arange(len(indexes_summary)),indexes_summary)))
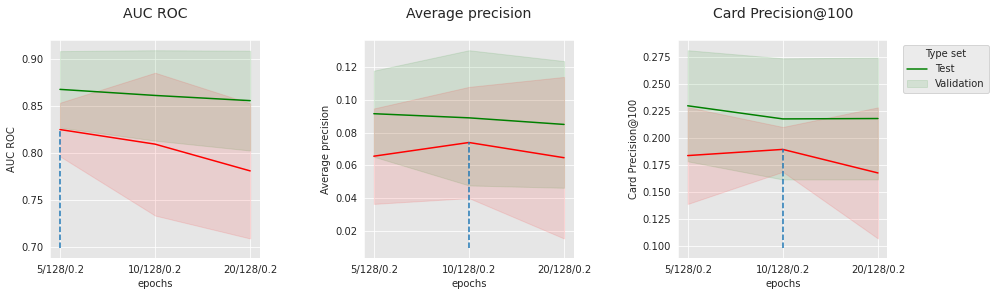
get_performances_plots(performances_df_lstm_subset,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="epochs",
summary_performances=summary_performances_lstm_subset)
performances_df_lstm_subset = performances_df_lstm[performances_df_lstm['Parameters'].apply(lambda x:x['clf__lr']== 0.001 and x['clf__batch_size']==64 and x['clf__module__hidden_size_lstm']==200 and x['clf__module__p']==0.2).values]
summary_performances_lstm_subset=get_summary_performances(performances_df_lstm_subset, parameter_column_name="Parameters summary")
indexes_summary = summary_performances_lstm_subset.index.values
indexes_summary[0] = 'Best estimated parameters'
summary_performances_lstm_subset.rename(index = dict(zip(np.arange(len(indexes_summary)),indexes_summary)))
get_performances_plots(performances_df_lstm_subset,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="epochs",
summary_performances=summary_performances_lstm_subset)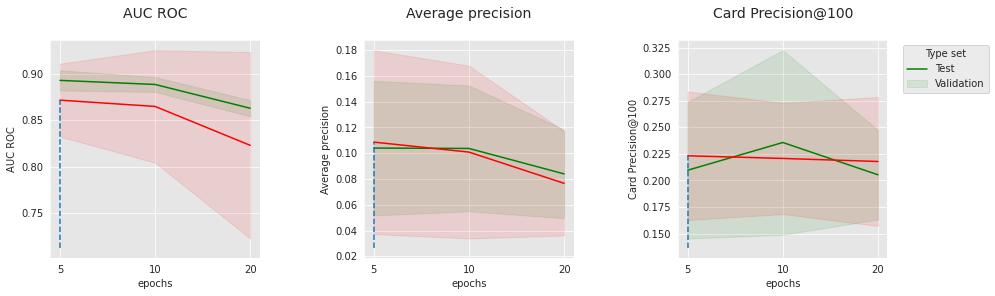
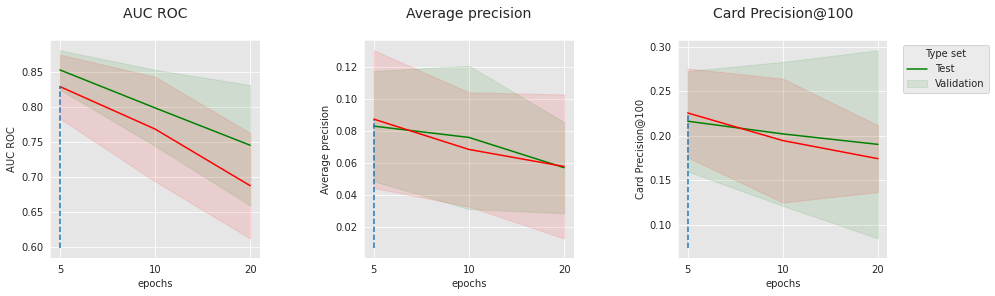
Os gráficos acima mostram a evolução das três métricas com o número de épocas, para os dois conjuntos extremos de hiperparâmetros relacionados à “convergência”. Nos gráficos superiores, a taxa de aprendizado é 0.0001 e o tamanho do lote é 256. Nos gráficos inferiores, a taxa de aprendizado é 0.001 e o tamanho do lote é 64. O melhor desempenho é obtido para a menor taxa de aprendizado, o maior tamanho de lote e o menor número de épocas, o que sugere que reduzir a velocidade de convergência ou o número de épocas poderia potencialmente melhorar ainda mais o desempenho. Apesar disso, o desempenho ótimo nos conjuntos de teste já é muito competitivo com a linha de base (veja os resultados ao final desta seção).
LSTM com Atenção¶
Para o LSTM com Atenção, realizamos finalmente a mesma análise que para o LSTM regular. Os resultados, mostrados abaixo, são ligeiramente melhores e também poderiam ser melhorados realizando menos passos de otimização ou desacelerando a convergência.
summary_performances_lstm_attnparameters_dict=dict(performances_df_lstm_attn['Parameters'])
performances_df_lstm_attn['Parameters summary']=[str(parameters_dict[i]['clf__max_epochs'])+
'/'+
str(parameters_dict[i]['clf__module__hidden_size_lstm'])
for i in range(len(parameters_dict))]
performances_df_lstm_attn_subset = performances_df_lstm_attn[performances_df_lstm_attn['Parameters'].apply(lambda x:x['clf__lr']== 0.0001 and x['clf__batch_size']==256 and x['clf__module__hidden_size_lstm']==200 and x['clf__module__p']==0.2).values]
summary_performances_lstm_attn_subset=get_summary_performances(performances_df_lstm_attn_subset, parameter_column_name="Parameters summary")
indexes_summary = summary_performances_lstm_attn_subset.index.values
indexes_summary[0] = 'Best estimated parameters'
summary_performances_lstm_attn_subset.rename(index = dict(zip(np.arange(len(indexes_summary)),indexes_summary)))
get_performances_plots(performances_df_lstm_attn_subset,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="hidden states size",
summary_performances=summary_performances_lstm_attn_subset)
performances_df_lstm_attn_subset = performances_df_lstm_attn[performances_df_lstm_attn['Parameters'].apply(lambda x:x['clf__lr']== 0.001 and x['clf__batch_size']==64 and x['clf__module__hidden_size_lstm']==200 and x['clf__module__p']==0.2).values]
summary_performances_lstm_attn_subset=get_summary_performances(performances_df_lstm_attn_subset, parameter_column_name="Parameters summary")
indexes_summary = summary_performances_lstm_attn_subset.index.values
indexes_summary[0] = 'Best estimated parameters'
summary_performances_lstm_attn_subset.rename(index = dict(zip(np.arange(len(indexes_summary)),indexes_summary)))
get_performances_plots(performances_df_lstm_attn_subset,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="epochs",
summary_performances=summary_performances_lstm_attn_subset)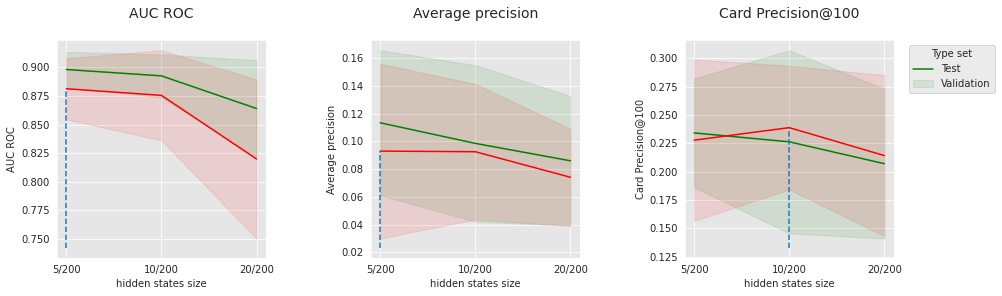
Comparação global¶
Para contrastar os resultados obtidos no conjunto de dados simulado nas seções anteriores, vamos também fazer aqui uma comparação completa das abordagens (linhas de base e modelos de aprendizado profundo) nos dados do mundo real. Em particular, vamos complementar os resultados acima com os obtidos com modelos de linha de base (Regressão Logística, Árvore de Decisão, Floresta Aleatória e XGBoost) e exibir tudo em uma tabela global.
# Load performance results for decision tree, logistic regression, random forest and XGBoost
filehandler = open('../Chapter_5_ModelValidationAndSelection/images/performances_model_selection_real_world_data.pkl', 'rb')
(performances_df_dictionary, execution_times) = pickle.load(filehandler)
# Load performance results for feed-forward neural network
filehandler = open('performances_model_selection_nn_real_data.pkl', 'rb')
(performances_df_dictionary_nn, execution_times_nn) = pickle.load(filehandler)
# Load performance results for CNN, LSTM and LSTM with Attention
filehandler = open('performances_model_selection_seq_model_real_data.pkl', 'rb')
(performances_df_dictionary_seq_model, execution_times_seq_model) = pickle.load(filehandler)performances_df_dt=performances_df_dictionary['Decision Tree']
summary_performances_dt=get_summary_performances(performances_df_dt, parameter_column_name="Parameters summary")
performances_df_lr=performances_df_dictionary['Logistic Regression']
summary_performances_lr=get_summary_performances(performances_df_lr, parameter_column_name="Parameters summary")
performances_df_rf=performances_df_dictionary['Random Forest']
summary_performances_rf=get_summary_performances(performances_df_rf, parameter_column_name="Parameters summary")
performances_df_xgboost=performances_df_dictionary['XGBoost']
summary_performances_xgboost=get_summary_performances(performances_df_xgboost, parameter_column_name="Parameters summary")
performances_df_nn=performances_df_dictionary_nn['Neural Network']
summary_performances_nn=get_summary_performances(performances_df_nn, parameter_column_name="Parameters summary")
performances_df_cnn=performances_df_dictionary_seq_model['CNN']
summary_performances_cnn=get_summary_performances(performances_df_cnn, parameter_column_name="Parameters summary")
performances_df_lstm=performances_df_dictionary_seq_model['LSTM']
summary_performances_lstm=get_summary_performances(performances_df_lstm, parameter_column_name="Parameters summary")
performances_df_lstm_attention=performances_df_dictionary_seq_model['LSTM_Attention']
summary_performances_lstm_attention=get_summary_performances(performances_df_lstm_attention, parameter_column_name="Parameters summary")
summary_test_performances = pd.concat([summary_performances_dt.iloc[2,:],
summary_performances_lr.iloc[2,:],
summary_performances_rf.iloc[2,:],
summary_performances_xgboost.iloc[2,:],
summary_performances_nn.iloc[2,:],
summary_performances_cnn.iloc[2,:],
summary_performances_lstm.iloc[2,:],
summary_performances_lstm_attention.iloc[2,:],
],axis=1)
summary_test_performances.columns=['Decision Tree', 'Logistic Regression', 'Random Forest', 'XGBoost',
'Neural Network', 'CNN', 'LSTM', 'LSTM with Attention']
summary_test_performancesAs conclusões aqui são diferentes dos resultados obtidos com os dados simulados. Parece que todos os modelos baseados em redes neurais têm um desempenho melhor do que a Regressão Logística e a Árvore de Decisão para as três métricas.
Em comparação com XGBoost e Floresta Aleatória, os modelos sequenciais são melhores em termos de Precisão Média, similares em termos de Precisão de Cartão@100 e piores em termos de AUC-ROC.
Os modelos sequenciais são melhores do que a rede feed-forward regular, sugerindo que a informação trazida pelo histórico de transações é relevante para detecção de fraude. O LSTM tem um desempenho melhor do que a CNN para o conjunto de hiperparâmetros escolhidos, e a Atenção traz um pequeno valor adicional.
A competitividade das arquiteturas de aprendizado profundo vem ao grande custo de hiperoptimização e ajuste, mas é definitivamente valiosa por todas as razões mencionadas na introdução (por exemplo, aprendizado incremental).