Na detecção de fraude em cartão de crédito, a escolha das características é crucial para uma classificação precisa. Considerável esforço de pesquisa tem sido dedicado ao desenvolvimento de características relevantes para caracterizar padrões fraudulentos. Estratégias de engenharia de características baseadas em agregações de características tornaram-se comumente adotadas Bahnsen et al. (2016). A agregação de características estabelece uma conexão entre a transação atual e outras transações relacionadas, calculando estatísticas sobre suas variáveis. Elas frequentemente originam-se de regras complexas definidas a partir de conhecimento de especialistas, e muitos experimentos relatam que melhoram significativamente a detecção Dal Pozzolo et al. (2014)Jurgovsky et al. (2018)Dastidar et al. (2020).
Usar agregação de características para detecção de fraude faz parte de um tópico de pesquisa denominado “detecção de fraude ciente do contexto”, onde se considera o contexto (por exemplo, o histórico do titular do cartão) associado a uma transação para tomar a decisão. Isso permite, por exemplo, fornecer insights sobre as propriedades da transação em relação aos padrões de compra habituais do titular do cartão e/ou terminal, o que é intuitivamente uma informação relevante.
Detecção de fraude ciente do contexto¶
O contexto é estabelecido com base em uma variável de referência (landmark variable), que na maioria dos casos é o ID do cliente. Concretamente, começa-se construindo a sequência de transações históricas, ordenadas cronologicamente da mais antiga para a atual, que têm o mesmo valor para a variável de referência que a transação atual.
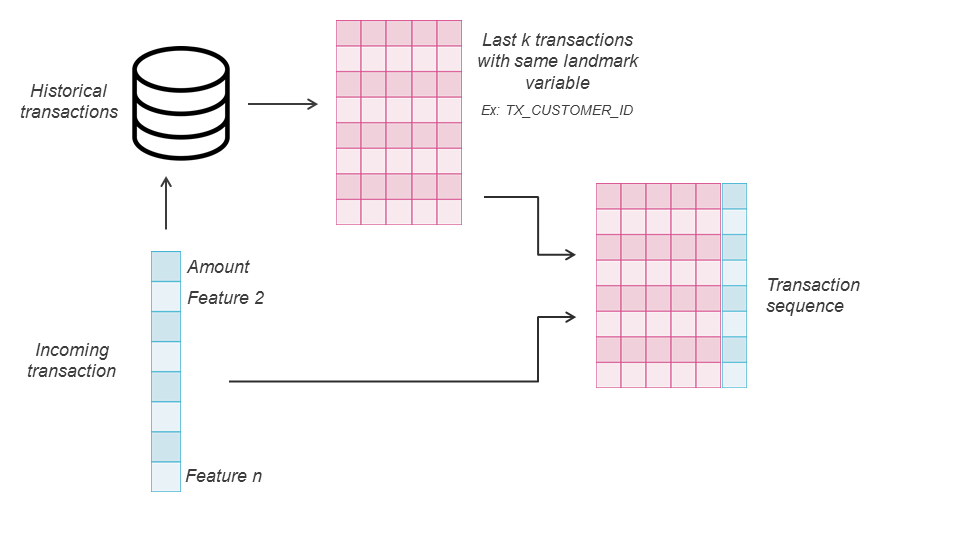
Toda essa sequência é a base bruta para abordagens cientes do contexto. De fato, o processo geral baseia-se na construção de novas características ou representações para cada transação dada com base em sua sequência contextual. No entanto, as abordagens podem ser divididas em duas categorias amplas: a primeira (Representações de Especialistas) baseando-se no conhecimento de domínio de especialistas para criar regras e construir agregações de características, e a segunda (Representações Automáticas) orientada para estratégias automatizadas de extração de características com modelos de aprendizado profundo.
Representações de especialistas¶
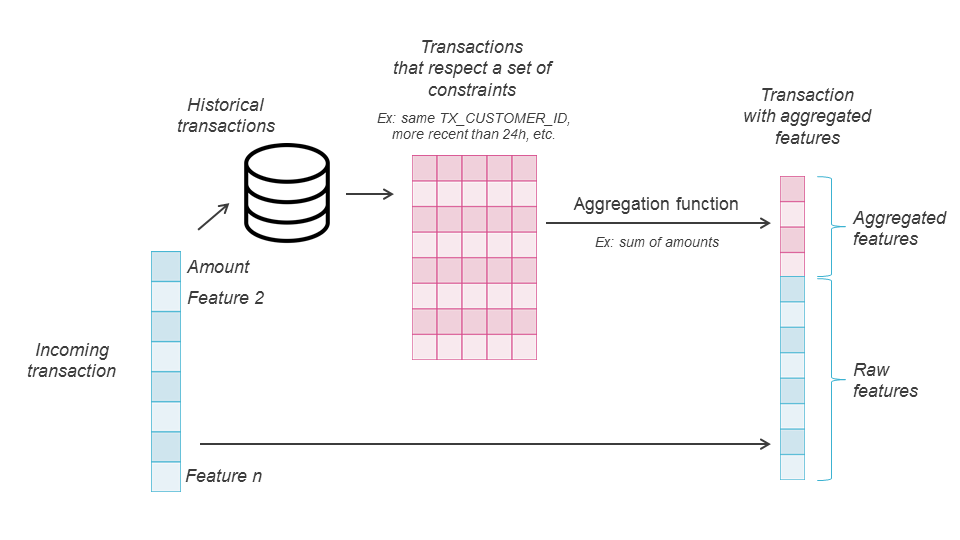
Para construir características de especialistas a partir da sequência base, uma camada de seleção que depende de restrições de especialistas (mesmo código de categoria de comerciante, mesmo país, mais recente do que uma semana, etc.) é primeiro aplicada para obter uma subsequência mais específica. Em seguida, uma função de agregação (soma, média, ...) é calculada sobre os valores de uma característica escolhida (por exemplo, valor) na subsequência. Para mais detalhes, Bahnsen et al. (2016) fornece uma definição formal de tais agregações de características. As características de especialistas não são necessariamente transferíveis em qualquer domínio de detecção de fraude, pois dependem de características específicas que podem não estar sempre disponíveis. No entanto, na prática, as características de referência, as características de restrição e as características agregadas são frequentemente escolhidas de um conjunto de atributos frequentes, compreendendo Tempo, Valor, País, Categoria do Comerciante, ID do Cliente, tipo de transação.
Representações automáticas¶
A outra família de abordagens cientes do contexto considera a sequência diretamente como entrada em um modelo e deixa-o aprender automaticamente as conexões certas para otimizar a detecção de fraude. A vantagem de não depender do conhecimento humano para construir as características relevantes é obviamente economizar os recursos custosos e facilitar a adaptabilidade e a manutenção. Além disso, os modelos podem ser direcionados para arquiteturas grandes e aprender relações de variáveis muito complexas automaticamente a partir dos dados. No entanto, requer um conjunto de dados suficientemente grande para identificar corretamente os padrões relevantes. Caso contrário, as representações de características não são muito precisas ou úteis.
Uma técnica de linha de base para uso automático de dados contextuais seria explorar a sequência de transações em sua totalidade (por exemplo, achatando-a em um conjunto de características), mas isso remove a informação sobre a ordem e poderia levar a um espaço de características de dimensão muito alta. Uma estratégia mais popular consiste em (1) transformar as sequências em sequências de tamanho fixo e (2) usar uma família especial de modelos que são capazes de lidar com sequências naturalmente e resumi-las em representações vetoriais relevantes para classificação de fraude.
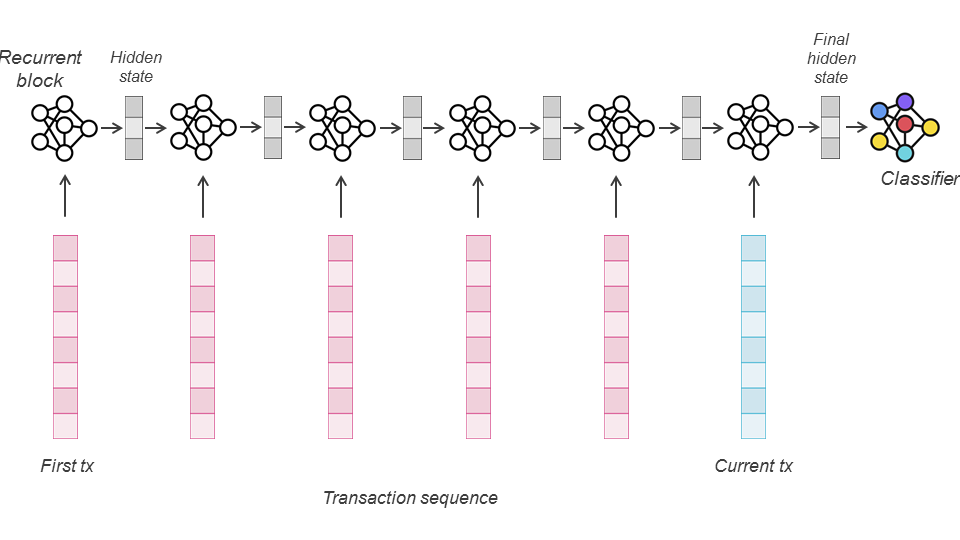
Essa estratégia é frequentemente referida como aprendizado sequencial, o estudo de algoritmos de aprendizado para dados sequenciais. A dependência sequencial entre pontos de dados é aprendida no nível algorítmico. Isso inclui métodos de janela deslizante, que frequentemente tendem a ignorar a ordem entre os pontos de dados dentro da janela, mas também modelos que são projetados explicitamente para considerar a ordem sequencial entre pontos de dados consecutivos (por exemplo, uma Cadeia de Markov). Tais modelos podem ser encontrados na família de arquiteturas de aprendizado profundo sob a categoria de redes neurais recorrentes. O vínculo entre elementos consecutivos da sequência é incorporado no design da arquitetura recorrente, onde o cálculo do estado/camada oculta de um evento mais recente depende dos estados ocultos de eventos anteriores.
Os métodos de janela deslizante incluem arquiteturas como redes neurais convolucionais 1D (1D-CNN), e os métodos sequenciais incluem arquiteturas como a memória de longa e curta duração (LSTM). Tais arquiteturas provaram ser muito eficientes no contexto de detecção de fraude no passado Jurgovsky et al. (2018).
Nesta seção, o objetivo é explorar o aprendizado automático de representação a partir de sequências de transações dos titulares de cartões e sua aplicação na detecção de fraude ciente do contexto. O conteúdo começa com os aspectos práticos de construção do pipeline para gerenciar dados sequenciais. Em seguida, três arquiteturas são exploradas sucessivamente: uma 1D-CNN, um LSTM e um modelo mais complexo que usa um LSTM com Atenção Bahdanau et al. (2014). A seção conclui com perspectivas de outras possibilidades de modelagem, como autoencoders sequência-a-sequência Sutskever et al. (2014)Alazizi et al. (2020), ou outras combinações dos modelos explorados.
Processamento de dados¶
Com modelagem de sequências, a construção do pipeline de processamento de dados tem importância especial. Em particular, como explicado na introdução, seu papel é criar as sequências de entrada para que os modelos sequenciais aprendam as representações.
A variável de referência mais popular para estabelecer a sequência é o ID do cliente. De fato, pela própria definição de fraude em cartão de crédito como um pagamento feito por alguém que não é o titular do cartão, faz mais sentido examinar o histórico do cliente para determinar quando um pagamento com cartão é fraudulento.
Portanto, o objetivo aqui é estabelecer Datasets e DataLoaders que forneçam, dado um índice de transação no conjunto de dados, a sequência de transações anteriores (incluindo a referenciada pelo índice) do mesmo titular do cartão. Além disso, como os modelos geralmente lidam com sequências de tamanho fixo, o comprimento da sequência será um parâmetro, e sequências muito longas (resp. muito curtas) serão cortadas (resp. preenchidas com padding).
Como de costume, vamos começar carregando um período fixo de treinamento e validação do conjunto de dados processado.
# Initialization: Load shared functions and simulated data
# Load shared functions
!curl -O https://raw.githubusercontent.com/Fraud-Detection-Handbook/fraud-detection-handbook/main/Chapter_References/shared_functions.py
%run shared_functions.py
# Get simulated data from Github repository
if not os.path.exists("simulated-data-transformed"):
!git clone https://github.com/Fraud-Detection-Handbook/simulated-data-transformed % Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 63257 100 63257 0 0 537k 0 --:--:-- --:--:-- --:--:-- 532k
DIR_INPUT='simulated-data-transformed/data/'
BEGIN_DATE = "2018-06-11"
END_DATE = "2018-09-14"
print("Load files")
%time transactions_df=read_from_files(DIR_INPUT, BEGIN_DATE, END_DATE)
print("{0} transactions loaded, containing {1} fraudulent transactions".format(len(transactions_df),transactions_df.TX_FRAUD.sum()))
output_feature="TX_FRAUD"
input_features=['TX_AMOUNT','TX_DURING_WEEKEND', 'TX_DURING_NIGHT', 'CUSTOMER_ID_NB_TX_1DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_1DAY_WINDOW', 'CUSTOMER_ID_NB_TX_7DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_7DAY_WINDOW', 'CUSTOMER_ID_NB_TX_30DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_30DAY_WINDOW', 'TERMINAL_ID_NB_TX_1DAY_WINDOW',
'TERMINAL_ID_RISK_1DAY_WINDOW', 'TERMINAL_ID_NB_TX_7DAY_WINDOW',
'TERMINAL_ID_RISK_7DAY_WINDOW', 'TERMINAL_ID_NB_TX_30DAY_WINDOW',
'TERMINAL_ID_RISK_30DAY_WINDOW']Load files
CPU times: user 311 ms, sys: 237 ms, total: 548 ms
Wall time: 570 ms
919767 transactions loaded, containing 8195 fraudulent transactions
# Set the starting day for the training period, and the deltas
start_date_training = datetime.datetime.strptime("2018-07-25", "%Y-%m-%d")
delta_train=7
delta_delay=7
delta_test=7
delta_valid = delta_test
start_date_training_with_valid = start_date_training+datetime.timedelta(days=-(delta_delay+delta_valid))
(train_df, valid_df)=get_train_test_set(transactions_df,start_date_training_with_valid,
delta_train=delta_train,delta_delay=delta_delay,delta_test=delta_test)
# By default, scales input data
(train_df, valid_df)=scaleData(train_df, valid_df,input_features)input_features['TX_AMOUNT',
'TX_DURING_WEEKEND',
'TX_DURING_NIGHT',
'CUSTOMER_ID_NB_TX_1DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_1DAY_WINDOW',
'CUSTOMER_ID_NB_TX_7DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_7DAY_WINDOW',
'CUSTOMER_ID_NB_TX_30DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_30DAY_WINDOW',
'TERMINAL_ID_NB_TX_1DAY_WINDOW',
'TERMINAL_ID_RISK_1DAY_WINDOW',
'TERMINAL_ID_NB_TX_7DAY_WINDOW',
'TERMINAL_ID_RISK_7DAY_WINDOW',
'TERMINAL_ID_NB_TX_30DAY_WINDOW',
'TERMINAL_ID_RISK_30DAY_WINDOW']Desta vez, adicionalmente às características acima, a construção das sequências exigirá dois campos adicionais dos DataFrames:
CUSTOMER_ID: a variável de referência que será usada para selecionar transações passadas.TX_DATETIME: a variável de tempo que permitirá construir sequências em ordem cronológica.
dates = train_df['TX_DATETIME'].valuescustomer_ids = train_df['CUSTOMER_ID'].valuesExistem múltiplas maneiras de implementar a criação de sequências para treinamento/validação. Uma maneira é pré-calcular, para cada transação, os índices das transações anteriores da sequência e armazená-los. Em seguida, construir as sequências de características dinamicamente a partir dos índices.
Aqui propomos alguns passos para prosseguir, mas tenha em mente que outras soluções são igualmente válidas.
Definindo o comprimento da sequência¶
O primeiro passo é definir um comprimento de sequência. Na literatura, 5 ou 10 são dois valores que frequentemente são escolhidos Jurgovsky et al. (2018). Isso pode ser um parâmetro a ajustar mais tarde, mas aqui, vamos arbitrariamente defini-lo como 5 para começar.
seq_len = 5Ordenando os elementos cronologicamente¶
Em nosso caso, as transações já estão ordenadas, mas no caso mais geral, para construir as sequências, é necessário ordenar todas as transações cronologicamente e manter os índices de ordenação:
indices_sort = np.argsort(dates)
sorted_dates = dates[indices_sort]
sorted_ids = customer_ids[indices_sort]Separando os dados de acordo com a variável de referência (ID do cliente)¶
Após a ordenação, o conjunto de dados é uma grande sequência com todas as transações de todos os titulares de cartões. Podemos separá-la em várias sequências que cada uma contém apenas as transações de um único titular de cartão. Por fim, cada sequência de cliente pode ser transformada em várias sequências de tamanho fixo usando uma janela deslizante e padding.
Para separar o conjunto de dados, vamos obter a lista de clientes:
unique_customer_ids = np.unique(sorted_ids)unique_customer_ids[0:10]array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])Para cada cliente, a subsequência associada pode ser selecionada com uma máscara booleana. Aqui está, por exemplo, a sequência de IDs de transações para o cliente 0.
idx = 0
current_customer_id = unique_customer_ids[idx]
customer_mask = sorted_ids == current_customer_id
# this is the full sequence of transaction indices (after sort) for customer 0
customer_full_seq = np.where(customer_mask)[0]
# this is the full sequence of transaction indices (before sort) for customer 0
customer_full_seq_original_indices = indices_sort[customer_full_seq]
customer_full_seq_original_indicesarray([ 1888, 10080, 12847, 15627, 18908, 22842, 37972, 42529, 44495,
48980, 58692, 63977])Transformando uma sequência de cliente em sequências de tamanho fixo¶
A sequência acima é a sequência completa para o cliente 0. Mas o objetivo é ter, para cada transação i dessa sequência, uma sequência de tamanho fixo que termina com a transação i, que será usada como entrada no modelo sequencial para prever o rótulo da transação i. No exemplo acima:
Para a transação 1888: as 4 transações anteriores são [nenhuma, nenhuma, nenhuma, nenhuma] (Nota: nenhuma pode ser substituída por um valor padrão como -1). Portanto, a sequência [nenhuma, nenhuma, nenhuma, nenhuma, 1888] será criada.
Para a transação 10080, a sequência será [nenhuma, nenhuma, nenhuma, 1888, 10080]
...
Para a transação 37972, a sequência será [12847, 15627, 18908, 22842, 37972]
Etc.
Usar uma janela deslizante (ou janela rolante) permite obter essas sequências:
def rolling_window(array, window):
a = np.concatenate([np.ones((window-1,))*-1,array])
shape = a.shape[:-1] + (a.shape[-1] - window + 1, window)
strides = a.strides + (a.strides[-1],)
return np.lib.stride_tricks.as_strided(a, shape=shape, strides=strides).astype(int)customer_all_seqs = rolling_window(customer_full_seq_original_indices,seq_len)customer_all_seqsarray([[ -1, -1, -1, -1, 1888],
[ -1, -1, -1, 1888, 10080],
[ -1, -1, 1888, 10080, 12847],
[ -1, 1888, 10080, 12847, 15627],
[ 1888, 10080, 12847, 15627, 18908],
[10080, 12847, 15627, 18908, 22842],
[12847, 15627, 18908, 22842, 37972],
[15627, 18908, 22842, 37972, 42529],
[18908, 22842, 37972, 42529, 44495],
[22842, 37972, 42529, 44495, 48980],
[37972, 42529, 44495, 48980, 58692],
[42529, 44495, 48980, 58692, 63977]])Gerando as sequências de características de transações dinamicamente a partir das sequências de índices¶
A partir das sequências de índices e das características de cada transação (disponíveis em x_train), a construção das sequências de características é direta. Vamos fazê-lo para a 6ª sequência:
customer_all_seqs[5]array([10080, 12847, 15627, 18908, 22842])x_train = torch.FloatTensor(train_df[input_features].values)sixth_sequence = x_train[customer_all_seqs[5],:]sixth_sequencetensor([[ 0.6965, -0.6306, 2.1808, -0.8466, 0.0336, -1.1665, 0.0176, -0.9341,
0.2310, -0.9810, -0.0816, -0.3445, -0.1231, -0.2491, -0.1436],
[ 0.0358, -0.6306, -0.4586, -0.8466, 0.4450, -1.1665, 0.1112, -0.8994,
0.2278, 0.0028, -0.0816, 0.6425, -0.1231, -0.0082, -0.1436],
[ 1.1437, -0.6306, -0.4586, -0.3003, 0.7595, -1.0352, 0.2462, -0.8994,
0.2458, 1.9702, -0.0816, 1.3005, -0.1231, 1.7989, -0.1436],
[ 0.3645, -0.6306, -0.4586, 0.2461, 0.6804, -1.0352, 0.3186, -0.8647,
0.2514, 1.9702, -0.0816, 0.3135, -0.1231, -0.8514, -0.1436],
[ 0.3348, -0.6306, -0.4586, -0.3003, 0.7462, -1.1665, 0.2494, -0.8994,
0.2262, -0.9810, -0.0816, -2.3185, -0.1231, -1.5743, -0.1436]])sixth_sequence.shapetorch.Size([5, 15])Nota: Aqui, a sequência de índices (customer_all_seqs[5]) era composta de índices válidos. Quando há índices inválidos (-1), a ideia é colocar uma “transação de padding” (por exemplo, com todas as características iguais a zero ou iguais ao valor médio que têm no conjunto de treinamento) na sequência final. Para obter um código homogêneo que possa ser usado tanto para índices válidos quanto inválidos, pode-se anexar a “transação de padding” a x_train no final e substituir todos os -1 pelo índice desta transação adicionada.
Implementação eficiente com pandas e groupby¶
Os passos acima são descritos para fins educacionais, pois permitem entender todas as operações necessárias para construir as sequências de transações. Na prática, porque esse processo requer um laço demorado sobre todos os IDs de Clientes, é melhor depender de um dataframe e usar a função groupby do pandas. Mais precisamente, a ideia é agrupar os elementos do dataframe de transações por ID de Cliente e usar a função shift para determinar, para cada transação, as que ocorreram antes. Para não editar o dataframe original, vamos primeiro criar um novo que contenha apenas as características necessárias.
df_ids_dates = pd.DataFrame({'CUSTOMER_ID': customer_ids,
'TX_DATETIME': dates})
#checking if the transaction are chronologically ordered
datetime_diff = (df_ids_dates["TX_DATETIME"] - df_ids_dates["TX_DATETIME"].shift(1)).iloc[1:].dt.total_seconds()
assert (datetime_diff >= 0).all()Vamos agora adicionar uma nova coluna com os índices de linha iniciais, que serão usados mais tarde com a função shift.
df_ids_dates["tmp_index"] = np.arange(len(df_ids_dates))df_ids_dates.head()O próximo passo é agrupar os elementos por ID de Cliente:
df_groupby_customer_id = df_ids_dates.groupby("CUSTOMER_ID")Agora é possível calcular um tmp_index deslocado em relação ao agrupamento por CUSTOMER_ID. Por exemplo, deslocar por 0 fornece o índice da transação atual e deslocar por 1 fornece o índice da transação anterior (ou NaN se a transação atual for a primeira transação do cliente).
df_groupby_customer_id["tmp_index"].shift(0)0 0
1 1
2 2
3 3
4 4
...
66923 66923
66924 66924
66925 66925
66926 66926
66927 66927
Name: tmp_index, Length: 66928, dtype: int64df_groupby_customer_id["tmp_index"].shift(1)0 NaN
1 NaN
2 NaN
3 NaN
4 NaN
...
66923 66805.0
66924 64441.0
66925 66777.0
66926 63338.0
66927 60393.0
Name: tmp_index, Length: 66928, dtype: float64Para obter as sequências completas de índices, a única coisa a fazer é iterar sobre o parâmetro de deslocamento, de seq_len - 1 a 0.
sequence_indices = pd.DataFrame(
{
"tx_{}".format(n): df_groupby_customer_id["tmp_index"].shift(seq_len - n - 1)
for n in range(seq_len)
}
)
sequence_indices = sequence_indices.fillna(-1).astype(int)sequence_indices.head()Como verificação de sanidade, vamos ver se este método calcula as mesmas sequências que o método anterior para as transações 12847, 15627 e 18908, que eram (ver 4.2.4):
[ -1, -1, 1888, 10080, 12847]
[ -1, 1888, 10080, 12847, 15627]
[ 1888, 10080, 12847, 15627, 18908]
print(sequence_indices.loc[12847].values)
print(sequence_indices.loc[15627].values)
print(sequence_indices.loc[18908].values)[ -1 -1 1888 10080 12847]
[ -1 1888 10080 12847 15627]
[ 1888 10080 12847 15627 18908]
Gerenciando a criação de sequências em um torch Dataset¶
Agora que o processo está pronto e testado, o passo final é implementá-lo dentro de um Dataset torch para usá-lo em um laço de treinamento. Para simplificar o uso, vamos considerar a estratégia de padding com “zeros” como padrão. O pré-cálculo de índices e a criação da transação de padding (uma transação com todas as características zeradas) serão feitos na inicialização. Em seguida, a função __getitem__ construirá a sequência de características dinamicamente.
if torch.cuda.is_available():
DEVICE = "cuda"
else:
DEVICE = "cpu"
print("Selected device is",DEVICE)Selected device is cuda
class FraudSequenceDataset(torch.utils.data.Dataset):
def __init__(self, x,y,customer_ids, dates, seq_len, padding_mode = 'zeros', output=True):
'Initialization'
# x,y,customer_ids, and dates must have the same length
# storing the features x in self.features and adding the "padding" transaction at the end
if padding_mode == "mean":
self.features = torch.vstack([x, x.mean(axis=0)])
elif padding_mode == "zeros":
self.features = torch.vstack([x, torch.zeros(x[0,:].shape)])
else:
raise ValueError('padding_mode must be "mean" or "zeros"')
self.y = y
self.customer_ids = customer_ids
self.dates = dates
self.seq_len = seq_len
self.output = output
#===== computing sequences ids =====
df_ids_dates = pd.DataFrame({'CUSTOMER_ID':customer_ids,
'TX_DATETIME':dates})
df_ids_dates["tmp_index"] = np.arange(len(df_ids_dates))
df_groupby_customer_id = df_ids_dates.groupby("CUSTOMER_ID")
sequence_indices = pd.DataFrame(
{
"tx_{}".format(n): df_groupby_customer_id["tmp_index"].shift(seq_len - n - 1)
for n in range(seq_len)
}
)
#replaces -1 (padding) with the index of the padding transaction (last index of self.features)
self.sequences_ids = sequence_indices.fillna(len(self.features) - 1).values.astype(int)
def __len__(self):
'Denotes the total number of samples'
# not len(self.features) because of the added padding transaction
return len(self.customer_ids)
def __getitem__(self, index):
'Generates one sample of data'
# Select sample index
tx_ids = self.sequences_ids[index]
if self.output:
#transposing because the CNN considers the channel dimension before the sequence dimension
return self.features[tx_ids,:].transpose(0,1).to(DEVICE), self.y[index].to(DEVICE)
else:
return self.features[tx_ids,:].transpose(0,1).to(DEVICE)Como verificação de sanidade, vamos testar o Dataset dentro de um DataLoader
x_train = torch.FloatTensor(train_df[input_features].values)
x_valid = torch.FloatTensor(valid_df[input_features].values)
y_train = torch.FloatTensor(train_df[output_feature].values)
y_valid = torch.FloatTensor(valid_df[output_feature].values)SEED = 42
seed_everything(SEED)train_loader_params = {'batch_size': 64,
'shuffle': True,
'num_workers': 0}
# Generators
training_set = FraudSequenceDataset(x_train, y_train,train_df['CUSTOMER_ID'].values, train_df['TX_DATETIME'].values,seq_len,padding_mode = "zeros")
training_generator = torch.utils.data.DataLoader(training_set, **train_loader_params)Vamos ver como o primeiro lote de treinamento se parece:
x_batch, y_batch = next(iter(training_generator))x_batch.shapetorch.Size([64, 15, 5])y_batch.shapetorch.Size([64])A forma de x_batch é (batch_size= 64, número de características= 15, seq_len= 5), que é a entrada esperada para uma rede convolucional 1D ou um modelo recorrente como um LSTM.
Rede neural convolucional para detecção de fraude¶
As redes neurais convolucionais (CNN) são redes neurais com camadas convolucionais específicas que permitem (1) detectar padrões ou formas específicas em regiões da entrada e (2) reduzir a complexidade espacial ao lidar com entradas grandes (por exemplo, uma imagem com milhões de pixels).
Para isso, elas substituem a camada totalmente conectada regular por uma camada de filtros convolucionais que realiza uma operação de convolução sobre os neurônios de entrada.
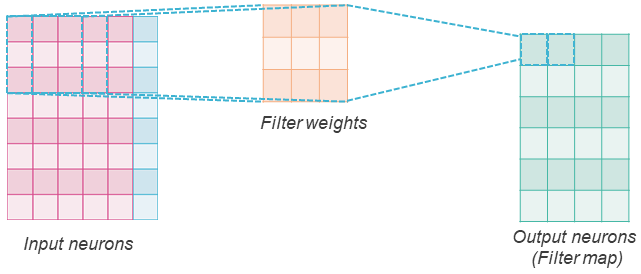
Uma camada convolucional tem num_filters filtros, com pesos de uma dimensão escolhida. Se considerarmos uma camada convolucional 2D, cada filtro tem 2 dimensões (largura e altura). No exemplo acima, consideramos uma entrada 8x6 e um filtro 3x3. A operação de convolução consiste em deslizar o filtro sobre a entrada da esquerda para a direita e de cima para baixo, e cada vez calcular a soma ponderada do trecho de entrada usando os pesos do filtro e aplicar uma função de ativação para obter uma saída similar a um neurônio regular. Na figura, representamos com quadrados pontilhados à esquerda os dois primeiros trechos de entrada pelos quais o filtro passa e à direita as duas saídas correspondentes. Aqui consideramos um parâmetro stride de 1, o que significa que o filtro desliza 1 entrada por vez. Não há padding, portanto o filtro não desliza para fora da entrada, e o resultado é um mapa de características de dimensão (8-(3-1))x(6-(3-1)), ou seja, 6x4. Mas pode-se aplicar padding (considerando que os valores fora da entrada são zeros) para que o mapa de características de saída tenha a mesma dimensão que a entrada.
A operação de convolução pode ser vista como um filtro varrendo a entrada para identificar um padrão específico. Os pesos dos filtros são aprendidos pelo modelo. Ter múltiplos filtros permite capturar múltiplos padrões que são úteis para reduzir a perda na tarefa em questão.
Para resumir as informações nas camadas finais ou economizar memória nas intermediárias, os mapas de características obtidos podem ser agregados em mapas menores com camadas de pooling (média, máxima).
Convoluções 1D¶
Nota: Embora não representado na figura, se a entrada for uma imagem, a entrada é de fato tridimensional (um mapa 2D de 3 características também chamadas de canais, ou seja, níveis RGB). O usuário define apenas 2 dimensões para o filtro (ao longo das direções de “deslizamento”), mas os filtros são na realidade tridimensionais também, a última dimensão correspondendo à dimensão do canal.
As convoluções 2D são usadas apenas para analisar entradas para as quais faz sentido deslizar ao longo de 2 dimensões. Em nosso caso, para lidar com sequências de transações, só faz sentido deslizar ao longo do eixo da sequência. Portanto, para detecção de fraude, recorremos a convoluções 1D e definimos uma única dimensão de filtro (com comprimento igual ao número de elementos consecutivos da sequência nos quais o filtro procura padrões).
Empilhando camadas convolucionais¶
Pode-se empilhar camadas convolucionais assim como camadas totalmente conectadas. Por exemplo, vamos considerar uma sequência de transação de entrada com 5 transações e 15 características para cada transação. Se for definida uma rede neural convolucional com uma primeira camada convolucional 1D com 100 filtros de comprimento 2 e uma segunda camada convolucional com 50 filtros de comprimento 2. Sem padding, as dimensões sucessivas dos mapas de características serão as seguintes:
A dimensão da entrada é (5,15): 5 é o comprimento da sequência e 15 é o número de canais.
A dimensão de saída da primeira camada convolucional é (4,100): cada filtro de dimensão (2,15) produzirá um mapa de características 1D com 5-(2-1) = 4 características.
A dimensão de saída da segunda camada convolucional é (3,50): cada filtro de dimensão (2,100) produzirá um mapa de características 1D com 4-(2-1) = 3 características.
Com padding, podemos garantir que o comprimento da sequência não mude e obter as dimensões (5,100) e (5,50) em vez de (4,100) e (3,50).
Classificação com uma rede neural convolucional¶
As camadas convolucionais produzem características de alto nível que detectam a presença de padrões ou combinações de padrões dentro da entrada. Essas características podem ser consideradas como agregados de características automáticos e podem então ser usadas em uma camada totalmente conectada regular final para classificação, após uma operação de achatamento. Esta operação pode ser feita usando um operador de pooling ao longo da dimensão da sequência ou com um operador de achatamento que simplesmente concatena os canais de todos os elementos da sequência em um único vetor global.
Implementação¶
As camadas convolucionais são definidas como camadas regulares. Em vez de usar o módulo torch.nn.Linear, usa-se as camadas específicas para redes neurais convolucionais:
torch.nn.Conv1d: este módulo define uma camada convolucional. Os parâmetros são o número de canais de entrada, o número de filtros e a dimensão dos filtros.torch.nn.ConstantPad1d: este módulo nos permite preencher uma sequência com um valor constante (por exemplo, 0) para obter o comprimento de sequência desejado após a camada convolucional subsequente.torch.nn.MaxPool1douAvgPool1d: esses módulos realizam uma operação de pooling sobre a dimensão da sequência.
Vamos definir um módulo FraudConvNet que utiliza os módulos torch acima para receber como entrada uma sequência de transações seq_len com len(input_features) características e prever se a última transação é fraudulenta. Consideraremos 2 camadas convolucionais com padding, uma camada de max-pooling, uma camada oculta totalmente conectada e uma camada totalmente conectada de saída com 1 neurônio de saída.
class FraudConvNet(torch.nn.Module):
def __init__(self,
num_features,
seq_len,hidden_size = 100,
conv1_params = (100,2),
conv2_params = None,
max_pooling = True):
super(FraudConvNet, self).__init__()
# parameters
self.num_features = num_features
self.hidden_size = hidden_size
# representation learning part
self.conv1_num_filters = conv1_params[0]
self.conv1_filter_size = conv1_params[1]
self.padding1 = torch.nn.ConstantPad1d((self.conv1_filter_size - 1,0),0)
self.conv1 = torch.nn.Conv1d(num_features, self.conv1_num_filters, self.conv1_filter_size)
self.representation_size = self.conv1_num_filters
self.conv2_params = conv2_params
if conv2_params:
self.conv2_num_filters = conv2_params[0]
self.conv2_filter_size = conv2_params[1]
self.padding2 = torch.nn.ConstantPad1d((self.conv2_filter_size - 1,0),0)
self.conv2 = torch.nn.Conv1d(self.conv1_num_filters, self.conv2_num_filters, self.conv2_filter_size)
self.representation_size = self.conv2_num_filters
self.max_pooling = max_pooling
if max_pooling:
self.pooling = torch.nn.MaxPool1d(seq_len)
else:
self.representation_size = self.representation_size*seq_len
# feed forward part at the end
self.flatten = torch.nn.Flatten()
#representation to hidden
self.fc1 = torch.nn.Linear(self.representation_size, self.hidden_size)
self.relu = torch.nn.ReLU()
#hidden to output
self.fc2 = torch.nn.Linear(self.hidden_size, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
representation = self.conv1(self.padding1(x))
if self.conv2_params:
representation = self.conv2(self.padding2(representation))
if self.max_pooling:
representation = self.pooling(representation)
representation = self.flatten(representation)
hidden = self.fc1(representation)
relu = self.relu(hidden)
output = self.fc2(relu)
output = self.sigmoid(output)
return outputTreinando a rede neural convolucional 1D¶
Para treinar a CNN, vamos reutilizar as mesmas funções das seções anteriores com o FraudSequenceDataset como Dataset e o FraudConvNet como module. O objetivo é o mesmo da rede feed-forward, portanto o critério também é a entropia cruzada binária.
seed_everything(SEED)
training_set = FraudSequenceDataset(x_train,
y_train,train_df['CUSTOMER_ID'].values,
train_df['TX_DATETIME'].values,
seq_len,
padding_mode = "zeros")
valid_set = FraudSequenceDataset(x_valid,
y_valid,
valid_df['CUSTOMER_ID'].values,
valid_df['TX_DATETIME'].values,
seq_len,
padding_mode = "zeros")
training_generator,valid_generator = prepare_generators(training_set, valid_set, batch_size=64)
cnn = FraudConvNet(x_train.shape[1], seq_len).to(DEVICE)
cnn
FraudConvNet(
(padding1): ConstantPad1d(padding=(1, 0), value=0)
(conv1): Conv1d(15, 100, kernel_size=(2,), stride=(1,))
(pooling): MaxPool1d(kernel_size=5, stride=5, padding=0, dilation=1, ceil_mode=False)
(flatten): Flatten(start_dim=1, end_dim=-1)
(fc1): Linear(in_features=100, out_features=100, bias=True)
(relu): ReLU()
(fc2): Linear(in_features=100, out_features=1, bias=True)
(sigmoid): Sigmoid()
)optimizer = torch.optim.Adam(cnn.parameters(), lr = 0.0001)
criterion = torch.nn.BCELoss().to(DEVICE)
cnn,training_execution_time,train_losses_dropout,valid_losses_dropout = \
training_loop(cnn,
training_generator,
valid_generator,
optimizer,
criterion,
verbose=True)
Epoch 0: train loss: 0.11331961992113045
valid loss: 0.04290128982539385
New best score: 0.04290128982539385
Epoch 1: train loss: 0.046289062976879895
valid loss: 0.02960259317868272
New best score: 0.02960259317868272
Epoch 2: train loss: 0.036232019433828276
valid loss: 0.026388588221743704
New best score: 0.026388588221743704
Epoch 3: train loss: 0.032827449974294105
valid loss: 0.02484128231874825
New best score: 0.02484128231874825
Epoch 4: train loss: 0.030821404086174817
valid loss: 0.02410742957730233
New best score: 0.02410742957730233
Epoch 5: train loss: 0.029202812739931062
valid loss: 0.022835184337413498
New best score: 0.022835184337413498
Epoch 6: train loss: 0.028094736857421653
valid loss: 0.02244713509854825
New best score: 0.02244713509854825
Epoch 7: train loss: 0.027001507802537853
valid loss: 0.022176400977415873
New best score: 0.022176400977415873
Epoch 8: train loss: 0.026254476560235208
valid loss: 0.02218911660570509
1 iterations since best score.
Epoch 9: train loss: 0.02560854040577751
valid loss: 0.021949108853768252
New best score: 0.021949108853768252
Epoch 10: train loss: 0.024981534799554672
valid loss: 0.021592291154964863
New best score: 0.021592291154964863
Epoch 11: train loss: 0.024556038766430716
valid loss: 0.021545066185997892
New best score: 0.021545066185997892
Epoch 12: train loss: 0.024165517638524706
valid loss: 0.02139132608751171
New best score: 0.02139132608751171
Epoch 13: train loss: 0.02384240027745459
valid loss: 0.021200239446136308
New best score: 0.021200239446136308
Epoch 14: train loss: 0.023490439055142052
valid loss: 0.021294136833313018
1 iterations since best score.
Epoch 15: train loss: 0.02323751859669618
valid loss: 0.021165060306787286
New best score: 0.021165060306787286
Epoch 16: train loss: 0.02279423619230967
valid loss: 0.021365655278354434
1 iterations since best score.
Epoch 17: train loss: 0.022614443875238456
valid loss: 0.021119751067465692
New best score: 0.021119751067465692
Epoch 18: train loss: 0.022311994288852135
valid loss: 0.021248318076062478
1 iterations since best score.
Epoch 19: train loss: 0.02212963180260797
valid loss: 0.021625581627095863
2 iterations since best score.
Epoch 20: train loss: 0.02185415759852715
valid loss: 0.021411337640742094
3 iterations since best score.
Early stopping
Avaliação¶
Para avaliar o modelo no conjunto de dados de validação, o comando predictions_test = model(x_test) que usamos anteriormente na rede feed-forward não funcionará aqui, pois a ConvNet espera que os dados estejam na forma de sequências. As previsões precisam ser feitas adequadamente usando o gerador de validação. Vamos implementar a função associada e adicioná-la às funções compartilhadas também.
def get_all_predictions(model, generator):
model.eval()
all_preds = []
for x_batch, y_batch in generator:
# Forward pass
y_pred = model(x_batch)
# append to all preds
all_preds.append(y_pred.detach().cpu().numpy())
return np.vstack(all_preds)valid_predictions = get_all_predictions(cnn, valid_generator)predictions_df = valid_df
predictions_df['predictions'] = valid_predictions[:,0]
performance_assessment(predictions_df, top_k_list=[100])Sem nenhum ajuste específico de hiperparâmetros, o desempenho parece ser competitivo com a rede neural feed-forward. Ao final desta seção, realizaremos uma busca em grade neste modelo para fins de comparação global.
Rede de Memória de Longa e Curta Duração (LSTM)¶
Como declarado na introdução, as sequências de transações também podem ser gerenciadas com uma rede de Memória de Longa e Curta Duração (LSTM).
Um LSTM é um tipo especial de Rede Neural Recorrente (RNN). O desenvolvimento das RNNs começou no início dos anos 80 Rumelhart et al. (1986) para modelar dados na forma de sequências (por exemplo, séries temporais). Os cálculos em uma RNN são muito similares a uma rede feed-forward regular, exceto que há múltiplos vetores de entrada na forma de sequência em vez de um único vetor de entrada, e a RNN modela a ordem dos vetores: ela realiza uma sucessão de cálculos que seguem a ordem das entradas na sequência. Em particular, ela repete uma unidade recorrente (uma rede com camadas regulares), do primeiro ao último item, que cada vez recebe como entrada a saída dos neurônios ocultos (estado oculto) do passo anterior e o item atual da sequência de entrada para produzir uma nova saída e um novo estado oculto.
A especificidade do LSTM é sua combinação avançada do estado oculto e do item atual da sequência para produzir o novo estado oculto. Em particular, ele usa vários gates (neurônios com ativações sigmoid) para selecionar inteligentemente as informações certas a manter do estado anterior e as informações certas a integrar da entrada atual. Para mais detalhes sobre os mecanismos específicos na camada LSTM, referimos o leitor ao seguinte material: https://
LSTM para detecção de fraude¶
O LSTM foi usado com sucesso para detecção de fraude na literatura Jurgovsky et al. (2018). A informação-chave a lembrar é que quando o LSTM recebe como entrada uma sequência de seq_len transações, ele produz uma sequência de seq_len estados ocultos de dimensão hidden_dim. O primeiro estado oculto será baseado apenas em um estado inicial do modelo e na primeira transação da sequência. O segundo estado oculto será baseado no primeiro estado oculto e na segunda transação da sequência. Portanto, pode-se considerar que o estado oculto final é uma representação agregada de toda a sequência, desde que a sequência não seja muito longa, e pode ser usada como entrada em uma camada feed-forward para classificar a última transação como fraudulenta ou genuína.
Implementação¶
O PyTorch fornece um módulo torch.nn.LSTM que implementa uma unidade LSTM. Ele recebe como entrada o número de características de cada vetor na sequência, a dimensão dos estados ocultos, o número de camadas e outros parâmetros como a porcentagem de dropout.
Vamos usá-lo para implementar um módulo FraudLSTM que recebe como entrada uma sequência de transações para prever o rótulo da última transação. A primeira camada será o módulo LSTM. Seu último estado oculto será usado em uma rede totalmente conectada com uma única camada oculta para finalmente prever o neurônio de saída.
Nota: Nosso DataLoader produz lotes de dimensão (batch_size, num_features, seq_len). Ao usar a opção batch_first = True, torch.nn.LSTM espera que a primeira dimensão seja o batch_size, o que é o caso. No entanto, ele espera que seq_len venha antes de num_features, portanto o segundo e o terceiro elementos da entrada devem ser transpostos.
class FraudLSTM(torch.nn.Module):
def __init__(self,
num_features,
hidden_size = 100,
hidden_size_lstm = 100,
num_layers_lstm = 1,
dropout_lstm = 0):
super(FraudLSTM, self).__init__()
# parameters
self.num_features = num_features
self.hidden_size = hidden_size
# representation learning part
self.lstm = torch.nn.LSTM(self.num_features,
hidden_size_lstm,
num_layers_lstm,
batch_first = True,
dropout = dropout_lstm)
#representation to hidden
self.fc1 = torch.nn.Linear(hidden_size_lstm, self.hidden_size)
self.relu = torch.nn.ReLU()
#hidden to output
self.fc2 = torch.nn.Linear(self.hidden_size, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
#transposing sequence length and number of features before applying the LSTM
representation = self.lstm(x.transpose(1,2))
#the second element of representation is a tuple with (final_hidden_states,final_cell_states)
#since the LSTM has 1 layer and is unidirectional, final_hidden_states has a single element
hidden = self.fc1(representation[1][0][0])
relu = self.relu(hidden)
output = self.fc2(relu)
output = self.sigmoid(output)
return outputTreinando o LSTM¶
Para treinar o LSTM, vamos aplicar a mesma metodologia que a CNN.
seed_everything(SEED)
training_generator,valid_generator = prepare_generators(training_set, valid_set,batch_size=64)
lstm = FraudLSTM(x_train.shape[1]).to(DEVICE)
optimizer = torch.optim.Adam(lstm.parameters(), lr = 0.0001)
criterion = torch.nn.BCELoss()
lstm,training_execution_time,train_losses_dropout,valid_losses_dropout = \
training_loop(lstm,
training_generator,
valid_generator,
optimizer,
criterion,
verbose=True)
Epoch 0: train loss: 0.13990207505212068
valid loss: 0.02620907245264923
New best score: 0.02620907245264923
Epoch 1: train loss: 0.031434995676729166
valid loss: 0.023325502496630034
New best score: 0.023325502496630034
Epoch 2: train loss: 0.0276708636452029
valid loss: 0.021220496156802552
New best score: 0.021220496156802552
Epoch 3: train loss: 0.025479454260691644
valid loss: 0.020511755727541943
New best score: 0.020511755727541943
Epoch 4: train loss: 0.02423322853112743
valid loss: 0.019815496125009133
New best score: 0.019815496125009133
Epoch 5: train loss: 0.02332264187745305
valid loss: 0.019972599826020294
1 iterations since best score.
Epoch 6: train loss: 0.022942402170918506
valid loss: 0.01945732499630562
New best score: 0.01945732499630562
Epoch 7: train loss: 0.02235023797337005
valid loss: 0.0196135713384217
1 iterations since best score.
Epoch 8: train loss: 0.022119645514110563
valid loss: 0.019718042683986123
2 iterations since best score.
Epoch 9: train loss: 0.021690097280103984
valid loss: 0.01908009442885004
New best score: 0.01908009442885004
Epoch 10: train loss: 0.02134914275318434
valid loss: 0.01881876519583471
New best score: 0.01881876519583471
Epoch 11: train loss: 0.02092900848780522
valid loss: 0.019134794213030427
1 iterations since best score.
Epoch 12: train loss: 0.02074213598841039
valid loss: 0.019468843063232717
2 iterations since best score.
Epoch 13: train loss: 0.020374752355523114
valid loss: 0.01866684172651094
New best score: 0.01866684172651094
Epoch 14: train loss: 0.02008993904532359
valid loss: 0.01853460792039872
New best score: 0.01853460792039872
Epoch 15: train loss: 0.019746437735577785
valid loss: 0.01839204282675427
New best score: 0.01839204282675427
Epoch 16: train loss: 0.019563284586295023
valid loss: 0.01872969562482964
1 iterations since best score.
Epoch 17: train loss: 0.019375868797962006
valid loss: 0.01919776629834675
2 iterations since best score.
Epoch 18: train loss: 0.019136815694366434
valid loss: 0.017995675191311216
New best score: 0.017995675191311216
Epoch 19: train loss: 0.018896986096734573
valid loss: 0.01803255443196601
1 iterations since best score.
Epoch 20: train loss: 0.01882533677201451
valid loss: 0.018077422815306325
2 iterations since best score.
Epoch 21: train loss: 0.01855331002204834
valid loss: 0.018072079796384755
3 iterations since best score.
Early stopping
Avaliação¶
A avaliação também é a mesma que com a CNN.
valid_predictions = get_all_predictions(lstm, valid_generator)predictions_df = valid_df
predictions_df['predictions'] = valid_predictions[:,0]
performance_assessment(predictions_df, top_k_list=[100])Este primeiro resultado com o LSTM é muito encorajador e altamente competitivo com as outras arquiteturas testadas no capítulo.
Vale ressaltar que, neste exemplo, apenas o último estado oculto é usado na rede de classificação final. Quando se lida com sequências longas e padrões complexos, esse estado por si só pode se tornar limitado para integrar todas as informações úteis para detecção de fraude. Além disso, dificulta identificar a contribuição das diferentes partes da sequência para uma previsão específica. Para lidar com esses problemas, pode-se usar todos os estados ocultos do LSTM e recorrer à Atenção (Attention) para selecioná-los e combiná-los.
Em direção a modelagens mais avançadas com Atenção¶
O mecanismo de Atenção é um dos principais avanços recentes em arquiteturas de redes neurais Bahdanau et al. (2014). Ele levou a avanços significativos no Processamento de Linguagem Natural (PLN), por exemplo, na arquitetura Transformer Vaswani et al. (2017) e suas múltiplas variantes, por exemplo, no BERT Devlin et al. (2018) ou GPT Radford et al. (2019).
O mecanismo de Atenção é uma implementação do conceito de Atenção, ou seja, focar seletivamente em um subconjunto de itens relevantes (por exemplo, estados) em redes neurais profundas. Foi inicialmente proposto como uma camada adicional para melhorar a arquitetura LSTM clássica de encoder-decoder para tradução automática de máquina. Ele permite alinhar o uso dos estados ocultos do encoder com o elemento atualmente sendo gerado pelo decoder, e resolver o problema de dependência de longo alcance dos LSTMs.
A diferença com o uso regular de um LSTM é que em vez de usar apenas o último estado oculto, o mecanismo de Atenção recebe como entrada todos os estados ocultos e os combina de maneira relevante em relação a um determinado contexto. Mais precisamente, em sua forma mais popular, a Atenção realiza as seguintes operações:
Dado um vetor de contexto e a sequência de estados ocultos , calcula uma pontuação de atenção para cada estado oculto, geralmente usando uma medida de similaridade como um produto interno entre e .
Normaliza todas as pontuações de atenção com um softmax.
Calcula um estado de saída global com uma combinação linear .
Para aplicações como tradução automática com uma arquitetura encoder-decoder, o vetor de contexto geralmente será o estado oculto atual do decoder, e a Atenção será aplicada a todos os estados ocultos do encoder. Em tal aplicação, o LSTM encoder recebe como entrada uma frase (sequência de palavras) em um idioma (por exemplo, francês), e o LSTM decoder recebe como entrada o início da frase traduzida em outro idioma (por exemplo, inglês). Portanto, faz sentido considerar o estado atual da tradução como contexto para selecionar/focar os elementos certos da sequência de entrada que serão levados em conta para prever a próxima palavra da tradução.
Atenção para detecção de fraude¶
Para detecção de fraude, apenas um LSTM encoder é usado em nossa implementação acima. A escolha de um vetor de contexto relevante será, portanto, baseada em nossa intuição sobre que tipo de contexto faz sentido para selecionar os estados ocultos corretos da sequência. Uma escolha razoável é considerar uma representação da transação que pretendemos classificar (a última transação) como contexto para selecionar os elementos corretos das transações anteriores. Duas escolhas são possíveis: usar diretamente o último estado oculto como vetor de contexto, ou uma projeção da última transação (por exemplo, após aplicar uma camada torch.nn.Linear). A seguir, recorremos à segunda opção, que está representada na arquitetura global abaixo:
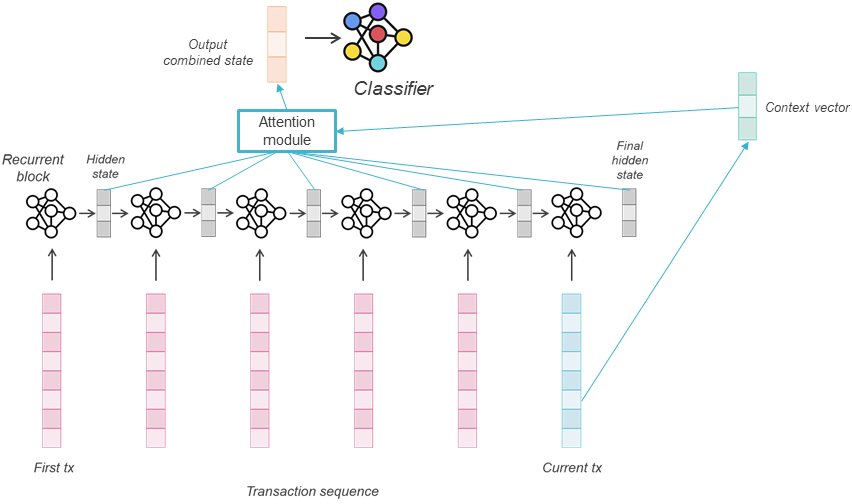
Além de permitir a seleção dinâmica dos estados ocultos relevantes para a amostra em questão, as pontuações de atenção podem fornecer interpretabilidade mostrando as partes da sequência usadas para a previsão atual.
Implementação¶
Não há implementação nativa de uma camada de Atenção simples na versão atual do Pytorch (1.9). No entanto, um torch.nn.MultiheadAttention mais geral, como o usado na arquitetura Transformer, está disponível. Embora permitisse implementar atenção regular, em vez disso usaremos um módulo não oficial que implementa um mecanismo de atenção mais simples para fins educacionais. Este módulo de Atenção está disponível no seguinte repositório git amplamente validado: seq2seq
Vamos copiar seu conteúdo na seguinte célula:
# source : https://github.com/IBM/pytorch-seq2seq/blob/master/seq2seq/models/attention.py
import torch.nn.functional as F
class Attention(torch.nn.Module):
r"""
Applies an attention mechanism on the output features from the decoder.
.. math::
\begin{array}{ll}
x = context*output \\
attn = exp(x_i) / sum_j exp(x_j) \\
output = \tanh(w * (attn * context) + b * output)
\end{array}
Args:
dim(int): The number of expected features in the output
Inputs: output, context
- **output** (batch, output_len, dimensions): tensor containing the output features from the decoder.
- **context** (batch, input_len, dimensions): tensor containing features of the encoded input sequence.
Outputs: output, attn
- **output** (batch, output_len, dimensions): tensor containing the attended output features from the decoder.
- **attn** (batch, output_len, input_len): tensor containing attention weights.
Attributes:
linear_out (torch.nn.Linear): applies a linear transformation to the incoming data: :math:`y = Ax + b`.
mask (torch.Tensor, optional): applies a :math:`-inf` to the indices specified in the `Tensor`.
Examples::
>>> attention = seq2seq.models.Attention(256)
>>> context = Variable(torch.randn(5, 3, 256))
>>> output = Variable(torch.randn(5, 5, 256))
>>> output, attn = attention(output, context)
"""
def __init__(self, dim):
super(Attention, self).__init__()
self.linear_out = torch.nn.Linear(dim*2, dim)
self.mask = None
def set_mask(self, mask):
"""
Sets indices to be masked
Args:
mask (torch.Tensor): tensor containing indices to be masked
"""
self.mask = mask
def forward(self, output, context):
batch_size = output.size(0)
hidden_size = output.size(2)
input_size = context.size(1)
# (batch, out_len, dim) * (batch, in_len, dim) -> (batch, out_len, in_len)
attn = torch.bmm(output, context.transpose(1, 2))
if self.mask is not None:
attn.data.masked_fill_(self.mask, -float('inf'))
attn = F.softmax(attn.view(-1, input_size), dim=1).view(batch_size, -1, input_size)
# (batch, out_len, in_len) * (batch, in_len, dim) -> (batch, out_len, dim)
mix = torch.bmm(attn, context)
# concat -> (batch, out_len, 2*dim)
combined = torch.cat((mix, output), dim=2)
# output -> (batch, out_len, dim)
output = F.tanh(self.linear_out(combined.view(-1, 2 * hidden_size))).view(batch_size, -1, hidden_size)
return output, attnComo funciona?¶
O módulo Attention personalizado acima tem um único parâmetro de inicialização que é a dimensão dos estados ocultos de entrada e do vetor de contexto. Durante o forward pass, recebe como entrada a sequência de estados ocultos e o vetor de contexto e produz o estado combinado e as pontuações de atenção.
Para familiarizar-se com o módulo, vamos calcular manualmente os estados ocultos de nosso LSTM anterior em um lote de treinamento aleatório e testar o mecanismo de Atenção.
x_batch, y_batch = next(iter(training_generator))out_seq, (last_hidden,last_cell) = lstm.lstm(x_batch.transpose(1,2))As saídas do LSTM são a sequência de todos os estados ocultos e os últimos estados oculto e de célula.
last_hidden.shapetorch.Size([1, 64, 100])out_seq.shapetorch.Size([64, 5, 100])Vamos armazenar as sequências de estados ocultos em uma variável test_hidden_states_seq:
test_hidden_states_seq = out_seqPara criar nosso vetor de contexto, vamos aplicar uma camada totalmente conectada ao último elemento da sequência de entrada (que é a transação que pretendemos classificar) e armazenar o resultado em uma variável test_context_vector:
test_context_projector = torch.nn.Linear(x_batch.shape[1], out_seq.shape[2]).to(DEVICE)test_context_vector = test_context_projector(x_batch[:,:,-1:].transpose(1,2))Os estados ocultos e vetores de contexto de todo o lote têm as seguintes dimensões:
test_hidden_states_seq.shapetorch.Size([64, 5, 100])test_context_vector.shapetorch.Size([64, 1, 100])Agora que as entradas para o mecanismo de Atenção estão prontas, vamos experimentar o módulo:
seed_everything(SEED)
test_attention = Attention(100).to(DEVICE)output_state, attn = test_attention(test_context_vector,test_hidden_states_seq)output_state.shapetorch.Size([64, 1, 100])attn[0,0]tensor([0.2517, 0.2583, 0.2432, 0.1509, 0.0959], device='cuda:0',
grad_fn=<SelectBackward>)Obtemos duas saídas. attn contém as pontuações de atenção dos estados ocultos e output_state é o estado combinado de saída, ou seja, a combinação linear dos estados ocultos com base nas pontuações de atenção.
Aqui os componentes de attn são relativamente equilibrados porque, como o módulo test_context_projector foi apenas inicializado aleatoriamente, os vetores de contexto test_context_vector são “aleatórios” e não são especificamente mais similares a um estado do que a outro.
Vamos ver o que acontece se o último estado oculto test_hidden_states_seq[:,4:,:] for usado como vetor de contexto em vez disso.
output, attn = test_attention(test_hidden_states_seq[:,4:,:],test_hidden_states_seq)attn[0,0]tensor([7.5513e-09, 4.9199e-08, 1.3565e-06, 1.2371e-03, 9.9876e-01],
device='cuda:0', grad_fn=<SelectBackward>)Desta vez, fica claro que a pontuação de atenção é muito maior para a última transação, pois é igual ao vetor de contexto. Interessantemente, pode-se observar que as pontuações diminuem da transação anterior mais recente para a mais antiga.
No entanto, usar o último estado oculto como vetor de contexto não garantirá necessariamente um comportamento melhor na classificação de fraudes. Em vez disso, vamos manter nossa estratégia com uma camada feed-forward que calculará um vetor de contexto a partir da última transação e treinar esta camada, o LSTM e o classificador final (que recebe como entrada o estado combinado para classificar a transação) todos juntos. Para fazer isso, implementamos um módulo personalizado FraudLSTMWithAttention.
class FraudLSTMWithAttention(torch.nn.Module):
def __init__(self,
num_features,
hidden_size = 100,
hidden_size_lstm = 100,
num_layers_lstm = 1,
dropout_lstm = 0,
attention_out_dim = 100):
super(FraudLSTMWithAttention, self).__init__()
# parameters
self.num_features = num_features
self.hidden_size = hidden_size
# sequence representation
self.lstm = torch.nn.LSTM(self.num_features,
hidden_size_lstm,
num_layers_lstm,
batch_first = True,
dropout = dropout_lstm)
# layer that will project the last transaction of the sequence into a context vector
self.ff = torch.nn.Linear(self.num_features, hidden_size_lstm)
# attention layer
self.attention = Attention(attention_out_dim)
#representation to hidden
self.fc1 = torch.nn.Linear(hidden_size_lstm, self.hidden_size)
self.relu = torch.nn.ReLU()
#hidden to output
self.fc2 = torch.nn.Linear(self.hidden_size, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
#computing the sequence of hidden states from the sequence of transactions
hidden_states, _ = self.lstm(x.transpose(1,2))
#computing the context vector from the last transaction
context_vector = self.ff(x[:,:,-1:].transpose(1,2))
combined_state, attn = self.attention(context_vector, hidden_states)
hidden = self.fc1(combined_state[:,0,:])
relu = self.relu(hidden)
output = self.fc2(relu)
output = self.sigmoid(output)
return outputTreinando o LSTM com Atenção¶
O LSTM com Atenção recebe a mesma entrada que o LSTM regular, portanto pode ser treinado e avaliado exatamente da mesma maneira.
seed_everything(SEED)
lstm_attn = FraudLSTMWithAttention(x_train.shape[1]).to(DEVICE)
lstm_attnFraudLSTMWithAttention(
(lstm): LSTM(15, 100, batch_first=True)
(ff): Linear(in_features=15, out_features=100, bias=True)
(attention): Attention(
(linear_out): Linear(in_features=200, out_features=100, bias=True)
)
(fc1): Linear(in_features=100, out_features=100, bias=True)
(relu): ReLU()
(fc2): Linear(in_features=100, out_features=1, bias=True)
(sigmoid): Sigmoid()
)training_generator,valid_generator = prepare_generators(training_set,valid_set,batch_size=64)
optimizer = torch.optim.Adam(lstm_attn.parameters(), lr = 0.00008)
criterion = torch.nn.BCELoss().to(DEVICE)
lstm_attn,training_execution_time,train_losses_dropout,valid_losses_dropout = \
training_loop(lstm_attn,
training_generator,
valid_generator,
optimizer,
criterion,
verbose=True)
Epoch 0: train loss: 0.10238753851141645
valid loss: 0.021834761867951094
New best score: 0.021834761867951094
Epoch 1: train loss: 0.026330269543929505
valid loss: 0.0203155988219189
New best score: 0.0203155988219189
Epoch 2: train loss: 0.024288250049589517
valid loss: 0.019749290624867535
New best score: 0.019749290624867535
Epoch 3: train loss: 0.02330792175176737
valid loss: 0.019204635951856324
New best score: 0.019204635951856324
Epoch 4: train loss: 0.02269919227573212
valid loss: 0.019130825754789423
New best score: 0.019130825754789423
Epoch 5: train loss: 0.022160232767046928
valid loss: 0.018929402052572434
New best score: 0.018929402052572434
Epoch 6: train loss: 0.02177732186309591
valid loss: 0.01847629409672723
New best score: 0.01847629409672723
Epoch 7: train loss: 0.02135627254457293
valid loss: 0.018755287848173798
1 iterations since best score.
Epoch 8: train loss: 0.02098137940145249
valid loss: 0.01887945729890543
2 iterations since best score.
Epoch 9: train loss: 0.020458271793019914
valid loss: 0.01891031490531979
3 iterations since best score.
Early stopping
Validação¶
valid_predictions = get_all_predictions(lstm_attn, valid_generator)
predictions_df = valid_df
predictions_df['predictions'] = valid_predictions[:,0]
performance_assessment(predictions_df, top_k_list=[100])Os resultados são competitivos com o LSTM. Adicionalmente, a vantagem desta arquitetura é a interpretabilidade das pontuações de atenção para uma determinada previsão.
Em outros cenários, por exemplo, com sequências mais longas, este modelo também pode ser capaz de alcançar um desempenho melhor do que o LSTM regular.
Autoencoders Seq-2-Seq¶
A seção anterior deste capítulo abordou o uso de autoencoders regulares em transações individuais para detecção de fraude. Vale ressaltar que os mesmos princípios poderiam ser aplicados aqui para criar um método semi-supervisionado para entradas sequenciais. Em vez de uma arquitetura feed-forward, um autoencoder sequência-a-sequência com uma arquitetura encoder-decoder poderia ser usado. Isso não é coberto nesta versão da seção, mas será proposto no futuro.
Busca em grade prequencial¶
Agora que exploramos diferentes arquiteturas de modelos sequenciais, vamos finalmente avaliá-los adequadamente com uma busca em grade prequencial. Em comparação com a busca em grade realizada na rede neural feed-forward, os modelos sequenciais adicionam uma pequena complexidade ao processo. De fato, eles foram projetados para receber como entrada uma sequência de transações. Para esse fim, o FraudSequenceDataset específico foi implementado, e requer duas características adicionais para construir as sequências: a característica de referência (CUSTOMER_ID) e a característica cronológica (TX_DATETIME). Nossa função de seleção de modelos anterior (model_selection_wrapper) não permite diretamente passar esses parâmetros extras ao Dataset torch. O truque aqui será simplesmente passá-los como características regulares, mas usá-los apenas para construir as sequências. Para isso, o FraudSequenceDataset precisa ser atualizado para uma nova versão (que será referida como FraudSequenceDatasetForPipe) que recebe apenas x e y como entrada e assume que a última coluna de x é TX_DATETIME, a coluna anterior é CUSTOMER_ID e o restante são as características regulares das transações.
class FraudSequenceDatasetForPipe(torch.utils.data.Dataset):
def __init__(self, x,y):
'Initialization'
seq_len=5
# lets us assume that x[:,-1] are the dates, and x[:,-2] are customer ids, padding_mode is "mean"
customer_ids = x[:,-2]
dates = x[:,-1]
# storing the features x in self.feature and adding the "padding" transaction at the end
self.features = torch.FloatTensor(x[:,:-2])
self.features = torch.vstack([self.features, self.features.mean(axis=0)])
self.y = None
if y is not None:
self.y = torch.LongTensor(y.values)
self.customer_ids = customer_ids
self.dates = dates
self.seq_len = seq_len
#===== computing sequences ids =====
df_ids_dates_cpy = pd.DataFrame({'CUSTOMER_ID':customer_ids,
'TX_DATETIME':dates})
df_ids_dates_cpy["tmp_index"] = np.arange(len(df_ids_dates_cpy))
df_groupby_customer_id = df_ids_dates_cpy.groupby("CUSTOMER_ID")
sequence_indices = pd.DataFrame(
{
"tx_{}".format(n): df_groupby_customer_id["tmp_index"].shift(seq_len - n - 1)
for n in range(seq_len)
}
)
self.sequences_ids = sequence_indices.fillna(len(self.features) - 1).values.astype(int)
df_ids_dates_cpy = df_ids_dates_cpy.drop("tmp_index", axis=1)
def __len__(self):
'Denotes the total number of samples'
# not len(self.features) because of the added padding transaction
return len(self.customer_ids)
def __getitem__(self, index):
'Generates one sample of data'
# Select sample index
tx_ids = self.sequences_ids[index]
if self.y is not None:
#transposing because the CNN considers the channel dimension before the sequence dimension
return self.features[tx_ids,:].transpose(0,1), self.y[index]
else:
return self.features[tx_ids,:].transpose(0,1), -1Busca em grade na Rede Neural Convolucional 1D¶
Vamos realizar uma busca em grade na CNN 1D com os seguintes hiperparâmetros:
Tamanho do lote: [64, 128, 256]
Taxa de aprendizado inicial: [0.0001, 0.0002, 0.001]
Número de épocas: [10, 20, 40]
Taxa de dropout: [0, 0.2]
Número de camadas convolucionais: [1, 2]
Número de filtros convolucionais: [100, 200]
Para isso, o módulo FraudCNN precisa ser adaptado para produzir duas probabilidades como os classificadores sklearn, e então encapsulado com skorch.
class FraudCNN(torch.nn.Module):
def __init__(self, num_features, seq_len=5,hidden_size = 100, num_filters = 100, filter_size = 2, num_conv=1, max_pooling = True,p=0):
super(FraudCNN, self).__init__()
# parameters
self.num_features = num_features
self.hidden_size = hidden_size
self.p = p
# representation learning part
self.num_filters = num_filters
self.filter_size = filter_size
self.padding1 = torch.nn.ConstantPad1d((filter_size - 1,0),0)
self.conv1 = torch.nn.Conv1d(num_features,self.num_filters,self.filter_size)
self.representation_size = self.num_filters
self.num_conv=num_conv
if self.num_conv==2:
self.padding2 = torch.nn.ConstantPad1d((filter_size - 1,0),0)
self.conv2 = torch.nn.Conv1d(self.num_filters,self.num_filters,self.filter_size)
self.representation_size = self.num_filters
self.max_pooling = max_pooling
if max_pooling:
self.pooling = torch.nn.MaxPool1d(seq_len)
else:
self.representation_size = self.representation_size*seq_len
# feed forward part at the end
self.flatten = torch.nn.Flatten()
#representation to hidden
self.fc1 = torch.nn.Linear(self.representation_size, self.hidden_size)
self.relu = torch.nn.ReLU()
#hidden to output
self.fc2 = torch.nn.Linear(self.hidden_size, 2)
self.softmax = torch.nn.Softmax()
self.dropout = torch.nn.Dropout(self.p)
def forward(self, x):
representation = self.conv1(self.padding1(x))
representation = self.dropout(representation)
if self.num_conv==2:
representation = self.conv2(self.padding2(representation))
representation = self.dropout(representation)
if self.max_pooling:
representation = self.pooling(representation)
representation = self.flatten(representation)
hidden = self.fc1(representation)
relu = self.relu(hidden)
relu = self.dropout(relu)
output = self.fc2(relu)
output = self.softmax(output)
return outputAs duas características extras (CUSTOMER_ID e TX_DATETIME) também precisam ser adicionadas à lista input_features.
Nota: a função model_selection_wrapper implementa um pipeline sklearn que combina o classificador com um escalonador. Portanto, as duas variáveis extras serão padronizadas como o restante das características. Para evitar comportamento inesperado, vamos converter os datetimes em timestamps. Uma vez feito isso, a normalização de CUSTOMER_ID e TX_DATETIME_TIMESTAMP não deve alterar o conjunto de IDs únicos de clientes nem a ordem cronológica das transações, e portanto levar às mesmas sequências e resultados.
transactions_df['TX_DATETIME_TIMESTAMP'] = transactions_df['TX_DATETIME'].apply(lambda x:datetime.datetime.timestamp(x))
input_features_new = input_features + ['CUSTOMER_ID','TX_DATETIME_TIMESTAMP']Agora que todas as classes estão prontas, vamos executar a busca em grade com a CNN usando o wrapper skorch e as mesmas configurações de pontuação e validação das seções anteriores.
!pip install skorchOutput
Requirement already satisfied: skorch in /opt/conda/lib/python3.8/site-packages (0.10.0)
Requirement already satisfied: scipy>=1.1.0 in /opt/conda/lib/python3.8/site-packages (from skorch) (1.6.3)
Requirement already satisfied: tabulate>=0.7.7 in /opt/conda/lib/python3.8/site-packages (from skorch) (0.8.9)
Requirement already satisfied: tqdm>=4.14.0 in /opt/conda/lib/python3.8/site-packages (from skorch) (4.51.0)
Requirement already satisfied: numpy>=1.13.3 in /opt/conda/lib/python3.8/site-packages (from skorch) (1.19.2)
Requirement already satisfied: scikit-learn>=0.19.1 in /opt/conda/lib/python3.8/site-packages (from skorch) (0.24.2)
Requirement already satisfied: joblib>=0.11 in /opt/conda/lib/python3.8/site-packages (from scikit-learn>=0.19.1->skorch) (1.0.1)
Requirement already satisfied: threadpoolctl>=2.0.0 in /opt/conda/lib/python3.8/site-packages (from scikit-learn>=0.19.1->skorch) (2.1.0)
from skorch import NeuralNetClassifier
# Only keep columns that are needed as argument to custome scoring function
# to reduce serialisation time of transaction dataset
transactions_df_scorer = transactions_df[['CUSTOMER_ID', 'TX_FRAUD','TX_TIME_DAYS']]
card_precision_top_100 = sklearn.metrics.make_scorer(card_precision_top_k_custom,
needs_proba=True,
top_k=100,
transactions_df=transactions_df_scorer)
performance_metrics_list_grid = ['roc_auc', 'average_precision', 'card_precision@100']
performance_metrics_list = ['AUC ROC', 'Average precision', 'Card Precision@100']
scoring = {'roc_auc':'roc_auc',
'average_precision': 'average_precision',
'card_precision@100': card_precision_top_100,
}
n_folds=4
start_date_training_for_valid = start_date_training+datetime.timedelta(days=-(delta_delay+delta_valid))
start_date_training_for_test = start_date_training+datetime.timedelta(days=(n_folds-1)*delta_test)
delta_assessment = delta_validseed_everything(42)
classifier = NeuralNetClassifier(
FraudCNN,
max_epochs=2,
lr=0.001,
optimizer=torch.optim.Adam,
batch_size=64,
dataset=FraudSequenceDatasetForPipe,
iterator_train__shuffle=True
)
classifier.set_params(train_split=False, verbose=0)
parameters = {
'clf__lr': [0.0001,0.0002,0.001],
'clf__batch_size': [64,128,256],
'clf__max_epochs': [10,20,40],
'clf__module__hidden_size': [500],
'clf__module__num_conv': [1,2],
'clf__module__p': [0,0.2],
'clf__module__num_features': [int(len(input_features))],
'clf__module__num_filters': [100,200],
}
start_time=time.time()
performances_df=model_selection_wrapper(transactions_df, classifier,
input_features_new, output_feature,
parameters, scoring,
start_date_training_for_valid,
start_date_training_for_test,
n_folds=n_folds,
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list,
n_jobs=10)
execution_time_cnn = time.time()-start_time
parameters_dict=dict(performances_df['Parameters'])
performances_df['Parameters summary']=[str(parameters_dict[i]['clf__max_epochs'])+
'/'+
str(parameters_dict[i]['clf__module__num_conv'])+
'/'+
str(parameters_dict[i]['clf__batch_size'])+
'/'+
str(parameters_dict[i]['clf__module__num_filters'])+
'/'+
str(parameters_dict[i]['clf__module__p'])
for i in range(len(parameters_dict))]
performances_df_cnn=performances_dfprint(execution_time_cnn)26904.69369339943
summary_performances_cnn=get_summary_performances(performances_df_cnn, parameter_column_name="Parameters summary")
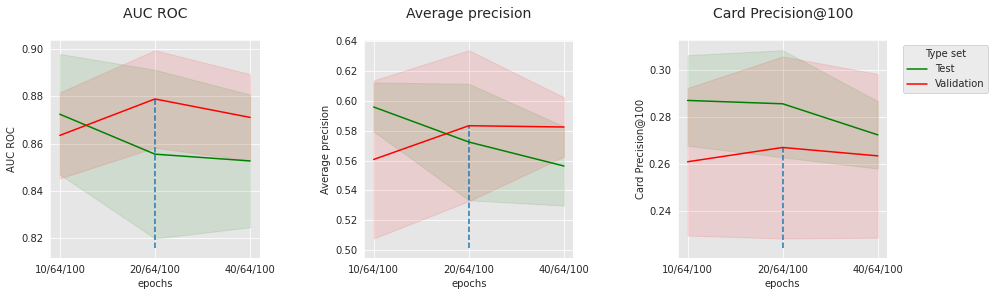
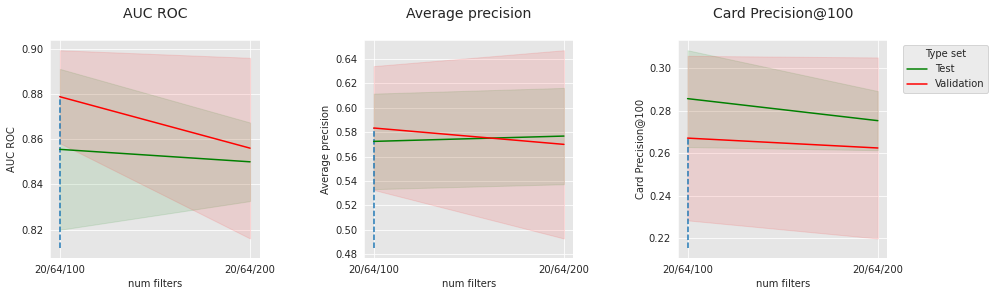
summary_performances_cnnOs resultados da CNN nos dados simulados são ligeiramente menos convincentes do que a rede feed-forward. Pode haver várias razões para isso. Em particular, com relação aos padrões anotados como fraudes nos dados simulados, os agregados em input_features já podem fornecer contexto suficiente para modelos regulares, o que limita o interesse da contextualização com a sequência. Vamos ver o impacto de alguns hiperparâmetros para entender melhor nosso modelo. Vamos fixar o número de camadas convolucionais em 2, o nível de dropout em 0.2, e visualizar o impacto do tamanho do lote, número de épocas e número de filtros.
parameters_dict=dict(performances_df_cnn['Parameters'])
performances_df_cnn['Parameters summary']=[str(parameters_dict[i]['clf__max_epochs'])+
'/'+
str(parameters_dict[i]['clf__batch_size'])+
'/'+
str(parameters_dict[i]['clf__module__num_filters'])
for i in range(len(parameters_dict))]
performances_df_cnn_subset = performances_df_cnn[performances_df_cnn['Parameters'].apply(lambda x:x['clf__lr']== 0.001 and x['clf__module__num_filters']==100 and x['clf__max_epochs']==20 and x['clf__module__num_conv']==2 and x['clf__module__p']==0.2).values]
summary_performances_cnn_subset=get_summary_performances(performances_df_cnn_subset, parameter_column_name="Parameters summary")
indexes_summary = summary_performances_cnn_subset.index.values
indexes_summary[0] = 'Best estimated parameters'
summary_performances_cnn_subset.rename(index = dict(zip(np.arange(len(indexes_summary)),indexes_summary)))
get_performances_plots(performances_df_cnn_subset,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="batch size",
summary_performances=summary_performances_cnn_subset)
performances_df_cnn_subset = performances_df_cnn[performances_df_cnn['Parameters'].apply(lambda x:x['clf__lr']== 0.001 and x['clf__module__num_filters']==100 and x['clf__batch_size']==64 and x['clf__module__num_conv']==2 and x['clf__module__p']==0.2).values]
summary_performances_cnn_subset=get_summary_performances(performances_df_cnn_subset, parameter_column_name="Parameters summary")
indexes_summary = summary_performances_cnn_subset.index.values
indexes_summary[0] = 'Best estimated parameters'
summary_performances_cnn_subset.rename(index = dict(zip(np.arange(len(indexes_summary)),indexes_summary)))
get_performances_plots(performances_df_cnn_subset,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="epochs",
summary_performances=summary_performances_cnn_subset)
performances_df_cnn_subset = performances_df_cnn[performances_df_cnn['Parameters'].apply(lambda x:x['clf__lr']== 0.001 and x['clf__max_epochs']==20 and x['clf__batch_size']==64 and x['clf__module__num_conv']==2 and x['clf__module__p']==0.2).values]
summary_performances_cnn_subset=get_summary_performances(performances_df_cnn_subset, parameter_column_name="Parameters summary")
indexes_summary = summary_performances_cnn_subset.index.values
indexes_summary[0] = 'Best estimated parameters'
summary_performances_cnn_subset.rename(index = dict(zip(np.arange(len(indexes_summary)),indexes_summary)))
get_performances_plots(performances_df_cnn_subset,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="num filters",
summary_performances=summary_performances_cnn_subset)
parameters_dict=dict(performances_df_cnn['Parameters'])
performances_df_cnn['Parameters summary']=[str(parameters_dict[i]['clf__max_epochs'])+
'/'+
str(parameters_dict[i]['clf__module__num_conv'])+
'/'+
str(parameters_dict[i]['clf__batch_size'])+
'/'+
str(parameters_dict[i]['clf__module__num_filters'])+
'/'+
str(parameters_dict[i]['clf__module__p'])
for i in range(len(parameters_dict))]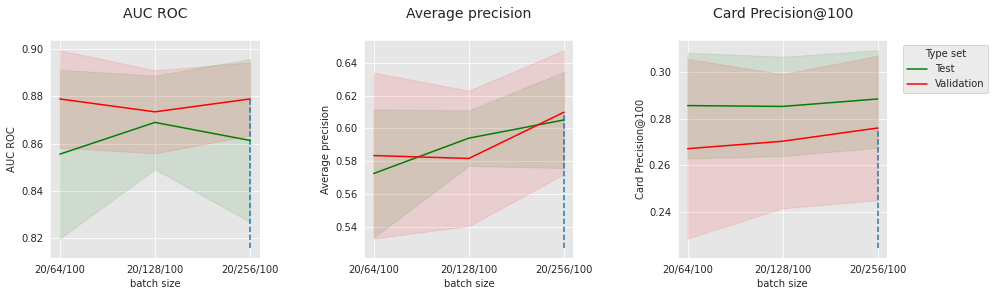
Semelhante à rede feed-forward, o número de épocas e o tamanho do lote, que são parâmetros de otimização, têm um ponto ótimo, que provavelmente está conectado a outros parâmetros (tamanho do modelo, dropout, etc.). Para os parâmetros de otimização escolhidos, 100 filtros parecem levar a melhores resultados do que 200.
Busca em grade no LSTM (Memória de Longa e Curta Duração)¶
Para o LSTM, buscaremos os seguintes hiperparâmetros:
Tamanho do lote: [64, 128, 256]
Taxa de aprendizado inicial: [0.0001, 0.0002, 0.001]
Número de épocas: [5, 10, 20]
Taxa de dropout: [0, 0.2, 0.4]
Dimensão dos estados ocultos do LSTM: [100, 200]
O LSTM recebe sequências de transações como entrada, portanto o processo é o mesmo que para a CNN, e o módulo também precisa ser adaptado para produzir dois neurônios.
class FraudLSTM(torch.nn.Module):
def __init__(self, num_features,hidden_size = 100, hidden_size_lstm = 100, num_layers_lstm = 1,p = 0):
super(FraudLSTM, self).__init__()
# parameters
self.num_features = num_features
self.hidden_size = hidden_size
# representation learning part
self.lstm = torch.nn.LSTM(self.num_features, hidden_size_lstm, num_layers_lstm, batch_first = True, dropout = p)
#representation to hidden
self.fc1 = torch.nn.Linear(hidden_size_lstm, self.hidden_size)
self.relu = torch.nn.ReLU()
#hidden to output
self.fc2 = torch.nn.Linear(self.hidden_size, 2)
self.softmax = torch.nn.Softmax()
self.dropout = torch.nn.Dropout(p)
def forward(self, x):
representation = self.lstm(x.transpose(1,2))
hidden = self.fc1(representation[1][0][0])
relu = self.relu(hidden)
relu = self.dropout(relu)
output = self.fc2(relu)
output = self.softmax(output)
return outputseed_everything(42)
classifier = NeuralNetClassifier(
FraudLSTM,
max_epochs=2,
lr=0.001,
optimizer=torch.optim.Adam,
batch_size=64,
dataset=FraudSequenceDatasetForPipe,
iterator_train__shuffle=True,
)
classifier.set_params(train_split=False, verbose=0)
parameters = {
'clf__lr': [0.0001,0.0002,0.001],
'clf__batch_size': [64,128,256],
'clf__max_epochs': [5,10,20],
'clf__module__hidden_size': [500],
'clf__module__p': [0,0.2,0.4],
'clf__module__num_features': [int(len(input_features))],
'clf__module__hidden_size_lstm': [100,200],
}
start_time=time.time()
#these will get normalized but it should still work
input_features_new = input_features + ['CUSTOMER_ID','TX_DATETIME_TIMESTAMP']
performances_df=model_selection_wrapper(transactions_df, classifier,
input_features_new, output_feature,
parameters, scoring,
start_date_training_for_valid,
start_date_training_for_test,
n_folds=n_folds,
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list,
n_jobs=10)
execution_time_lstm = time.time()-start_time
parameters_dict=dict(performances_df['Parameters'])
performances_df['Parameters summary']=[str(parameters_dict[i]['clf__max_epochs'])+
'/'+
str(parameters_dict[i]['clf__batch_size'])+
'/'+
str(parameters_dict[i]['clf__module__hidden_size_lstm'])+
'/'+
str(parameters_dict[i]['clf__module__p'])
for i in range(len(parameters_dict))]
# Rename to performances_df_lstm for model performance comparison at the end of this notebook
performances_df_lstm=performances_dfprint(execution_time_lstm)14750.79782986641
summary_performances_lstm=get_summary_performances(performances_df_lstm, parameter_column_name="Parameters summary")
summary_performances_lstmOs resultados com o LSTM são mais competitivos do que a CNN, e são similares à rede feed-forward. Isso ainda está alinhado com a hipótese de que a sequência não fornece, para este conjunto de dados, um valor agregado notável em comparação com apenas a última transação com informações agregadas. No entanto, a comparação com a CNN mostra que, mesmo com a mesma entrada, a escolha da arquitetura pode ter um impacto importante no desempenho. Além disso, a busca em grade realizada é para fins de ilustração e está longe de ser exaustiva, portanto o ajuste de hiperparâmetros traz um artefato adicional aos resultados.
As conclusões sobre o conjunto de hiperparâmetros ótimos são muito mistas aqui. Vamos fixar a taxa de aprendizado em 0.0001, o tamanho do lote em 128, o nível de dropout em 0.2, e visualizar o impacto do número de épocas e do tamanho dos estados ocultos.
parameters_dict=dict(performances_df_lstm['Parameters'])
performances_df_lstm['Parameters summary']=[str(parameters_dict[i]['clf__max_epochs'])+
'/'+
str(parameters_dict[i]['clf__module__hidden_size_lstm'])
for i in range(len(parameters_dict))]
performances_df_lstm_subset = performances_df_lstm[performances_df_lstm['Parameters'].apply(lambda x:x['clf__lr']== 0.0001 and x['clf__batch_size']==128 and x['clf__max_epochs']==10 and x['clf__module__p']==0.2).values]
summary_performances_lstm_subset=get_summary_performances(performances_df_lstm_subset, parameter_column_name="Parameters summary")
indexes_summary = summary_performances_lstm_subset.index.values
indexes_summary[0] = 'Best estimated parameters'
summary_performances_lstm_subset.rename(index = dict(zip(np.arange(len(indexes_summary)),indexes_summary)))
get_performances_plots(performances_df_lstm_subset,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="hidden states size",
summary_performances=summary_performances_lstm_subset)
performances_df_lstm_subset = performances_df_lstm[performances_df_lstm['Parameters'].apply(lambda x:x['clf__lr']== 0.0001 and x['clf__batch_size']==128 and x['clf__module__hidden_size_lstm']==100 and x['clf__module__p']==0.2).values]
summary_performances_lstm_subset=get_summary_performances(performances_df_lstm_subset, parameter_column_name="Parameters summary")
indexes_summary = summary_performances_lstm_subset.index.values
indexes_summary[0] = 'Best estimated parameters'
summary_performances_lstm_subset.rename(index = dict(zip(np.arange(len(indexes_summary)),indexes_summary)))
get_performances_plots(performances_df_lstm_subset,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="epochs",
summary_performances=summary_performances_lstm_subset)
parameters_dict=dict(performances_df_lstm['Parameters'])
performances_df_lstm['Parameters summary']=[str(parameters_dict[i]['clf__max_epochs'])+
'/'+
str(parameters_dict[i]['clf__batch_size'])+
'/'+
str(parameters_dict[i]['clf__module__hidden_size_lstm'])+
'/'+
str(parameters_dict[i]['clf__module__p'])
for i in range(len(parameters_dict))]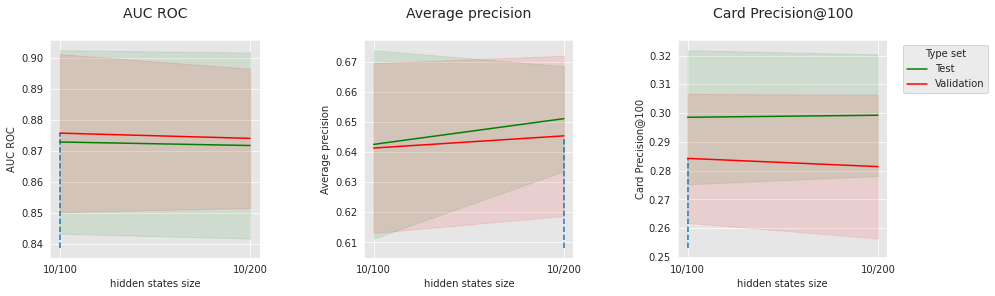
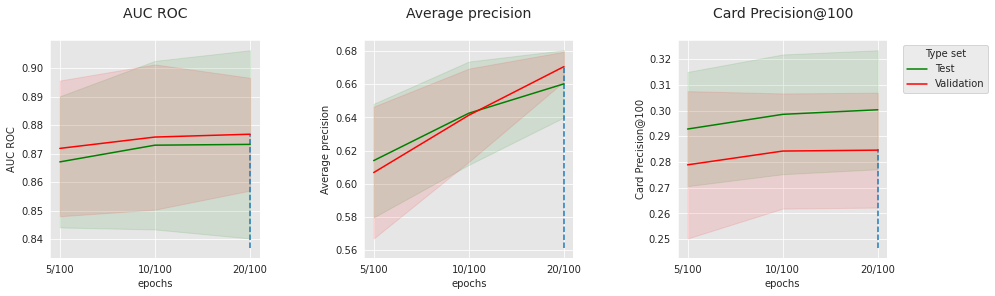
Lembre-se que a busca em grade não é exaustiva, e pelos gráficos, parece que a precisão média poderia ter sido melhorada ainda mais.
Busca em grade no LSTM com Atenção¶
Para o LSTM com Atenção, aplicamos o mesmo processo que para o LSTM.
class FraudLSTMWithAttention(torch.nn.Module):
def __init__(self, num_features,hidden_size = 100, hidden_size_lstm = 100, num_layers_lstm = 1,p = 0):
super(FraudLSTMWithAttention, self).__init__()
# parameters
self.num_features = num_features
self.hidden_size = hidden_size
# representation learning part
self.lstm = torch.nn.LSTM(self.num_features, hidden_size_lstm, num_layers_lstm, batch_first = True, dropout = p)
# last sequence represenation
self.ff = torch.nn.Linear(self.num_features,hidden_size_lstm)
attention_out_dim = hidden_size_lstm
# attention layer
self.attention = Attention(attention_out_dim)
#representation to hidden
self.fc1 = torch.nn.Linear(hidden_size_lstm, self.hidden_size)
self.relu = torch.nn.ReLU()
#hidden to output
self.fc2 = torch.nn.Linear(self.hidden_size, 2)
self.softmax = torch.nn.Softmax()
self.dropout = torch.nn.Dropout(p)
def forward(self, x):
representation_seq, _ = self.lstm(x.transpose(1,2))
representation_last = self.ff(x[:,:,-1:].transpose(1,2))
representation, attn = self.attention(representation_last,representation_seq)
hidden = self.fc1(representation[:,0,:])
relu = self.relu(hidden)
relu = self.dropout(relu)
output = self.fc2(relu)
output = self.softmax(output)
return outputseed_everything(42)
classifier = NeuralNetClassifier(
FraudLSTMWithAttention,
max_epochs=2,
lr=0.001,
optimizer=torch.optim.Adam,
batch_size=64,
dataset=FraudSequenceDatasetForPipe,
iterator_train__shuffle=True,
)
classifier.set_params(train_split=False, verbose=0)
parameters = {
'clf__lr': [0.0001,0.0002,0.001],
'clf__batch_size': [64,128,256],
'clf__max_epochs': [5,10,20],
'clf__module__hidden_size': [500],
'clf__module__p': [0,0.2,0.4],
'clf__module__num_features': [int(len(input_features))],
'clf__module__hidden_size_lstm': [100,200],
}
start_time=time.time()
#these will get normalized but it should still work
input_features_new = input_features + ['CUSTOMER_ID','TX_DATETIME_TIMESTAMP']
performances_df=model_selection_wrapper(transactions_df, classifier,
input_features_new, output_feature,
parameters, scoring,
start_date_training_for_valid,
start_date_training_for_test,
n_folds=n_folds,
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list,
n_jobs=10)
execution_time_lstm_attn = time.time()-start_time
parameters_dict=dict(performances_df['Parameters'])
performances_df['Parameters summary']=[str(parameters_dict[i]['clf__max_epochs'])+
'/'+
str(parameters_dict[i]['clf__batch_size'])+
'/'+
str(parameters_dict[i]['clf__module__hidden_size_lstm'])+
'/'+
str(parameters_dict[i]['clf__module__p'])
for i in range(len(parameters_dict))]
# Rename to performances_df_lstm for model performance comparison at the end of this notebook
performances_df_lstm_attn=performances_dfprint(execution_time_lstm_attn)16735.779472112656
summary_performances_lstm_attn=get_summary_performances(performances_df_lstm_attn, parameter_column_name="Parameters summary")
summary_performances_lstm_attnO LSTM com Atenção tem um desempenho apenas ligeiramente melhor do que o LSTM regular. Embora a Atenção seja um mecanismo que impacta significativamente muitas aplicações como PLN, seu interesse pode ser limitado em sequências tão curtas quanto essas e em um modelo que tem apenas uma única camada recorrente.
parameters_dict=dict(performances_df_lstm_attn['Parameters'])
performances_df_lstm_attn['Parameters summary']=[str(parameters_dict[i]['clf__max_epochs'])+
'/'+
str(parameters_dict[i]['clf__module__hidden_size_lstm'])
for i in range(len(parameters_dict))]
performances_df_lstm_attn_subset = performances_df_lstm_attn[performances_df_lstm_attn['Parameters'].apply(lambda x:x['clf__lr']== 0.0001 and x['clf__batch_size']==128 and x['clf__max_epochs']==10 and x['clf__module__p']==0.2).values]
summary_performances_lstm_attn_subset=get_summary_performances(performances_df_lstm_attn_subset, parameter_column_name="Parameters summary")
indexes_summary = summary_performances_lstm_attn_subset.index.values
indexes_summary[0] = 'Best estimated parameters'
summary_performances_lstm_attn_subset.rename(index = dict(zip(np.arange(len(indexes_summary)),indexes_summary)))
get_performances_plots(performances_df_lstm_attn_subset,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="hidden states size",
summary_performances=summary_performances_lstm_attn_subset)
performances_df_lstm_attn_subset = performances_df_lstm_attn[performances_df_lstm_attn['Parameters'].apply(lambda x:x['clf__lr']== 0.0001 and x['clf__batch_size']==128 and x['clf__module__hidden_size_lstm']==100 and x['clf__module__p']==0.2).values]
summary_performances_lstm_attn_subset=get_summary_performances(performances_df_lstm_attn_subset, parameter_column_name="Parameters summary")
indexes_summary = summary_performances_lstm_attn_subset.index.values
indexes_summary[0] = 'Best estimated parameters'
summary_performances_lstm_attn_subset.rename(index = dict(zip(np.arange(len(indexes_summary)),indexes_summary)))
get_performances_plots(performances_df_lstm_attn_subset,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="epochs",
summary_performances=summary_performances_lstm_attn_subset)
parameters_dict=dict(performances_df_lstm_attn['Parameters'])
performances_df_lstm_attn['Parameters summary']=[str(parameters_dict[i]['clf__max_epochs'])+
'/'+
str(parameters_dict[i]['clf__batch_size'])+
'/'+
str(parameters_dict[i]['clf__module__hidden_size_lstm'])+
'/'+
str(parameters_dict[i]['clf__module__p'])
for i in range(len(parameters_dict))]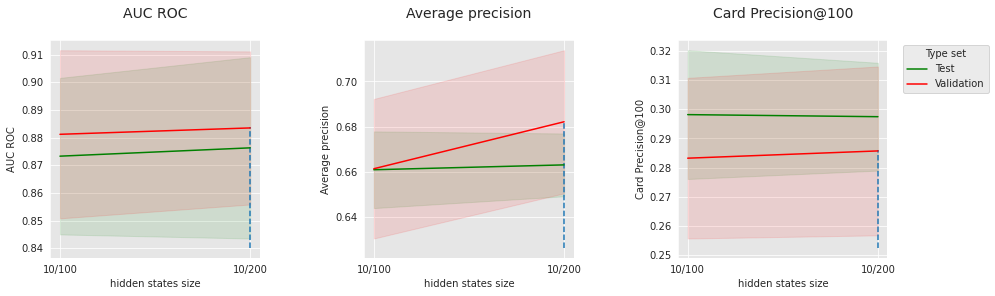
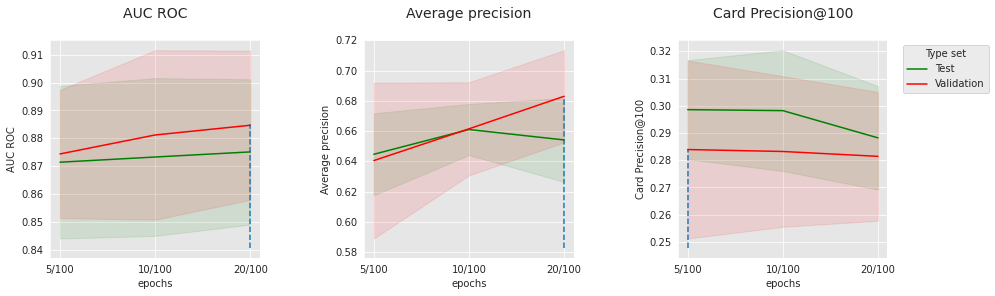
Para o mesmo conjunto de hiperparâmetros, a convergência em relação à precisão média é diferente do LSTM sem Atenção.
Salvamento dos resultados¶
Vamos salvar os resultados de desempenho e os tempos de execução destes três modelos no formato pickle do Python.
performances_df_dictionary={
"CNN": performances_df_cnn,
"LSTM": performances_df_lstm,
"LSTM_Attention": performances_df_lstm_attn,
}
execution_times=[execution_time_cnn,execution_time_lstm,execution_time_lstm_attn]
filehandler = open('performances_model_selection_seq_model.pkl', 'wb')
pickle.dump((performances_df_dictionary, execution_times), filehandler)
filehandler.close()Resumo do benchmark¶
Vamos finalmente recuperar os resultados de desempenho obtidos em
Capítulo 5 com árvore de decisão, regressão logística, floresta aleatória e XGBoost, e
Capítulo 7, Seção 2 com redes neurais feed-forward
e compará-los com os obtidos com CNN, LSTM e LSTM com Atenção.
Os resultados podem ser recuperados carregando os arquivos pickle performances_model_selection.pkl, performances_model_selection_nn.pkl e performances_model_selection_seq_model.pkl, e resumidos com a função get_summary_performances.
Notebook Cell
# Load performance results for decision tree, logistic regression, random forest and XGBoost
filehandler = open('../Chapter_5_ModelValidationAndSelection/performances_model_selection.pkl', 'rb')
(performances_df_dictionary, execution_times) = pickle.load(filehandler)
# Load performance results for feed-forward neural network
filehandler = open('performances_model_selection_nn.pkl', 'rb')
(performances_df_dictionary_nn, execution_times_nn) = pickle.load(filehandler)
# Load performance results for CNN, LSTM and LSTM with Attention
filehandler = open('performances_model_selection_seq_model.pkl', 'rb')
(performances_df_dictionary_seq_model, execution_times_seq_model) = pickle.load(filehandler)
Notebook Cell
performances_df_dt=performances_df_dictionary['Decision Tree']
summary_performances_dt=get_summary_performances(performances_df_dt, parameter_column_name="Parameters summary")
performances_df_lr=performances_df_dictionary['Logistic Regression']
summary_performances_lr=get_summary_performances(performances_df_lr, parameter_column_name="Parameters summary")
performances_df_rf=performances_df_dictionary['Random Forest']
summary_performances_rf=get_summary_performances(performances_df_rf, parameter_column_name="Parameters summary")
performances_df_xgboost=performances_df_dictionary['XGBoost']
summary_performances_xgboost=get_summary_performances(performances_df_xgboost, parameter_column_name="Parameters summary")
performances_df_nn=performances_df_dictionary_nn['Neural Network']
summary_performances_nn=get_summary_performances(performances_df_nn, parameter_column_name="Parameters summary")
performances_df_cnn=performances_df_dictionary_seq_model['CNN']
summary_performances_cnn=get_summary_performances(performances_df_cnn, parameter_column_name="Parameters summary")
performances_df_lstm=performances_df_dictionary_seq_model['LSTM']
summary_performances_lstm=get_summary_performances(performances_df_lstm, parameter_column_name="Parameters summary")
performances_df_lstm_attention=performances_df_dictionary_seq_model['LSTM_Attention']
summary_performances_lstm_attention=get_summary_performances(performances_df_lstm_attention, parameter_column_name="Parameters summary")
summary_test_performances = pd.concat([summary_performances_dt.iloc[2,:],
summary_performances_lr.iloc[2,:],
summary_performances_rf.iloc[2,:],
summary_performances_xgboost.iloc[2,:],
summary_performances_nn.iloc[2,:],
summary_performances_cnn.iloc[2,:],
summary_performances_lstm.iloc[2,:],
summary_performances_lstm_attention.iloc[2,:],
],axis=1)
summary_test_performances.columns=['Decision Tree', 'Logistic Regression', 'Random Forest', 'XGBoost',
'Neural Network', 'CNN', 'LSTM', 'LSTM with Attention']
Os resultados são resumidos em uma tabela summary_test_performances. As linhas fornecem os resultados médios de desempenho nos conjuntos de teste em termos de AUC ROC, Precisão Média e CP@100.
summary_test_performancesNo final, parece que as abordagens baseadas em redes neurais fornecem resultados competitivos com florestas aleatórias e XGBoost, com desempenhos ligeiramente melhores em termos de AUC ROC e ligeiramente piores em termos de Precisão Média. No entanto, deve-se ter em mente que, com mais recursos computacionais, um ajuste de hiperparâmetros mais extenso poderia ser realizado para abordagens baseadas em redes neurais, o que provavelmente levaria a uma melhoria adicional em seu desempenho.
Conclusão¶
Nesta seção, foram explorados métodos automáticos para construir características a partir de dados contextuais. Para classificar uma transação como fraudulenta ou genuína, geralmente é útil recorrer ao comportamento regular do titular do cartão para detectar uma discrepância. Um método manual para integrar essas informações contextuais é prosseguir com a engenharia de características e a criação de agregações de características de especialistas.
Métodos de aprendizado automático de representação da literatura de Aprendizado Profundo foram explorados para criar características que representam a sequência de transações anteriores do titular do cartão de uma forma que otimiza a classificação da transação atual.
Os componentes metodológicos chave são a construção do pipeline de dados para criar automaticamente os dados sequenciais a partir de variáveis de referência e a combinação correta de redes neurais adaptadas, como a 1D-CNN, o LSTM, o mecanismo de Atenção, etc. Esses modelos foram testados aqui e podem fornecer um desempenho competitivo. No futuro, outras arquiteturas candidatas como Multi-Head Self-Attention, Autoencoder Sequência-a-Sequência, ou qualquer combinação dos módulos acima, poderiam ser exploradas para tentar melhorar ainda mais o desempenho da detecção de fraude.
- Bahnsen, A. C., Aouada, D., Stojanovic, A., & Ottersten, B. (2016). Feature engineering strategies for credit card fraud detection. Expert Systems with Applications, 51, 134–142.
- Dal Pozzolo, A., Caelen, O., Le Borgne, Y.-A., Waterschoot, S., & Bontempi, G. (2014). Learned lessons in credit card fraud detection from a practitioner perspective. Expert Systems with Applications, 41(10), 4915–4928.
- Jurgovsky, J., Granitzer, M., Ziegler, K., Calabretto, S., Portier, P.-E., He-Guelton, L., & Caelen, O. (2018). Sequence classification for credit-card fraud detection. Expert Systems with Applications, 100, 234–245.
- Dastidar, K. G., Jurgovsky, J., Siblini, W., He-Guelton, L., & Granitzer, M. (2020). NAG: Neural feature aggregation framework for credit card fraud detection. 2020 IEEE International Conference on Data Mining (ICDM), 92–101.
- Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv Preprint arXiv:1409.0473.
- Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to sequence learning with neural networks. Advances in Neural Information Processing Systems, 3104–3112.
- Alazizi, A., Habrard, A., Jacquenet, F., He-Guelton, L., & Oblé, F. (2020). Dual Sequential Variational Autoencoders for Fraud Detection. IDA, 14–26.
- Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1986). Learning representations by back-propagating errors. Nature, 323(6088), 533–536.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 5998–6008.
- Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv Preprint arXiv:1810.04805.
- Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., Sutskever, I., & others. (2019). Language models are unsupervised multitask learners. OpenAI Blog, 1(8), 9.