Como as redes neurais são um pilar tanto nos avanços iniciais quanto nos recentes da inteligência artificial, seu uso para detecção de fraude em cartão de crédito não é surpreendente. Os primeiros exemplos de redes neurais feed-forward simples aplicadas à detecção de fraude remontam ao início dos anos 90 Ghosh & Reilly (1994)Aleskerov et al. (1997). Naturalmente, em estudos recentes sobre FDS, as redes neurais são frequentemente encontradas em benchmarks experimentais, junto com florestas aleatórias, XGBoost ou regressão logística.
No núcleo de uma rede neural feed-forward está o neurônio artificial, um modelo de aprendizado de máquina simples que consiste em uma combinação linear de variáveis de entrada seguida pela aplicação de uma função de ativação (sigmoid, ReLU, tanh, ...). Mais precisamente, dado uma lista de variáveis de entrada , a saída do neurônio artificial é calculada da seguinte forma:
onde são os pesos do modelo.
Uma rede completa é composta por uma sucessão de camadas contendo neurônios que tomam, como entradas, os valores de saída da camada anterior.
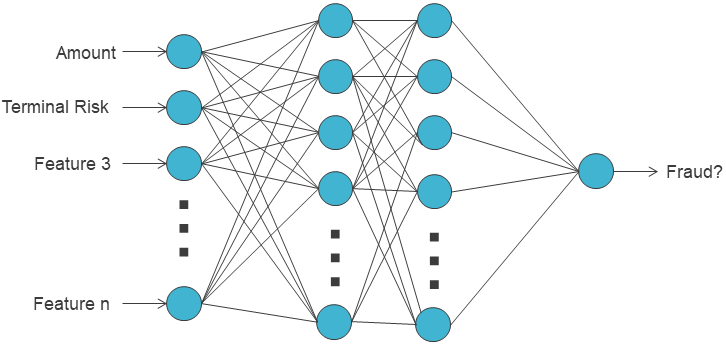
Quando aplicada ao problema de detecção de fraude, a arquitetura é projetada da seguinte forma:
No início da rede, os neurônios tomam como entrada as características de uma transação de cartão de crédito, ou seja, as características que foram definidas nos capítulos anteriores.
No final, a rede produz um único neurônio que visa representar a probabilidade de a transação de entrada ser uma fraude.
O restante da arquitetura (outras camadas), a especificidade dos neurônios (funções de ativação) e outros hiperparâmetros (otimização, processamento de dados, ...) ficam a critério do profissional.
O algoritmo de treinamento mais popular para arquiteturas feedforward é a retropropagação (backpropagation) Hecht-Nielsen (1992). A ideia é iterar sobre todas as amostras do conjunto de dados e realizar duas operações principais:
a passagem direta (forward pass): definir os valores das características da amostra nos neurônios de entrada e calcular todas as camadas para, finalmente, obter uma saída predita.
a passagem inversa (backward pass): calcular uma função de custo, ou seja, uma discrepância entre a previsão e a saída esperada (ground truth), e tentar minimizá-la com um otimizador (ex.: gradiente descendente), atualizando os pesos camada por camada, da saída para a entrada.
Esta seção cobre o projeto de uma rede neural feed-forward para detecção de fraude. Ela descreve como:
Implementar uma primeira rede neural simples e estudar o impacto de várias arquiteturas e escolhas de design.
Envolvê-la para torná-la compatível com a metodologia de seleção de modelos do Capítulo 5 e executar uma busca em grade para selecionar seus parâmetros ótimos.
Armazenar as funções importantes para uma comparação final entre técnicas de aprendizado profundo e outras linhas de base ao final do capítulo.
Vamos começar importando todas as bibliotecas e funções necessárias e recuperando os dados simulados.
Notebook Cell
# Initialization: Load shared functions and simulated data
# Load shared functions
!curl -O https://raw.githubusercontent.com/Fraud-Detection-Handbook/fraud-detection-handbook/main/Chapter_References/shared_functions.py
%run shared_functions.py
# Get simulated data from Github repository
if not os.path.exists("simulated-data-transformed"):
!git clone https://github.com/Fraud-Detection-Handbook/simulated-data-transformed % Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 63257 100 63257 0 0 225k 0 --:--:-- --:--:-- --:--:-- 227k
Carregamento de dados¶
A configuração experimental é a mesma do Capítulo 5. Mais precisamente, ao final do capítulo, a seleção de modelos será baseada em uma busca em grade com múltiplas validações. A cada vez, uma semana de dados será usada para treinar uma rede neural e uma semana de dados para testar as previsões.
Para implementar a primeira rede base e explorar várias escolhas de arquitetura, vamos começar selecionando um período de treinamento e validação arbitrariamente. Os experimentos serão baseados nos dados simulados transformados (simulated-data-transformed/data/) e no mesmo conjunto de características que outros modelos.
DIR_INPUT='simulated-data-transformed/data/'
BEGIN_DATE = "2018-06-11"
END_DATE = "2018-09-14"
print("Load files")
%time transactions_df=read_from_files(DIR_INPUT, BEGIN_DATE, END_DATE)
print("{0} transactions loaded, containing {1} fraudulent transactions".format(len(transactions_df),transactions_df.TX_FRAUD.sum()))
output_feature="TX_FRAUD"
input_features=['TX_AMOUNT','TX_DURING_WEEKEND', 'TX_DURING_NIGHT', 'CUSTOMER_ID_NB_TX_1DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_1DAY_WINDOW', 'CUSTOMER_ID_NB_TX_7DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_7DAY_WINDOW', 'CUSTOMER_ID_NB_TX_30DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_30DAY_WINDOW', 'TERMINAL_ID_NB_TX_1DAY_WINDOW',
'TERMINAL_ID_RISK_1DAY_WINDOW', 'TERMINAL_ID_NB_TX_7DAY_WINDOW',
'TERMINAL_ID_RISK_7DAY_WINDOW', 'TERMINAL_ID_NB_TX_30DAY_WINDOW',
'TERMINAL_ID_RISK_30DAY_WINDOW']Load files
CPU times: user 321 ms, sys: 245 ms, total: 566 ms
Wall time: 588 ms
919767 transactions loaded, containing 8195 fraudulent transactions
# Setting the starting day for the training period, and the deltas
start_date_training = datetime.datetime.strptime("2018-07-25", "%Y-%m-%d")
delta_train=7
delta_delay=7
delta_test=7
(train_df, test_df)=get_train_test_set(transactions_df,start_date_training,
delta_train=delta_train,delta_delay=delta_delay,delta_test=delta_test)
# By default, scaling the input data
(train_df, test_df)=scaleData(train_df,test_df,input_features)Visão geral do pipeline de rede neural¶
O primeiro passo aqui é implementar uma rede neural base. Existem várias bibliotecas Python que podemos usar (TensorFlow, PyTorch, Keras, MXNet, ...). Neste livro, a biblioteca PyTorch Paszke et al. (2017) é utilizada, mas os modelos e benchmarks que serão desenvolvidos também poderiam ser implementados com outras bibliotecas.
import torchSe as bibliotecas torch e cuda estiverem instaladas corretamente, os modelos desenvolvidos neste capítulo podem ser treinados na GPU. Para isso, vamos criar uma variável “DEVICE” e defini-la como “cuda” se um dispositivo cuda estiver disponível e “cpu” caso contrário. No restante do capítulo, todos os modelos e tensores serão enviados a este dispositivo para os cálculos.
if torch.cuda.is_available():
DEVICE = "cuda"
else:
DEVICE = "cpu"
print("Selected device is",DEVICE)Selected device is cuda
Para garantir a reprodutibilidade, uma semente aleatória será fixada como nos capítulos anteriores. Além de definir a semente para NumPy e random, é necessário defini-la para torch:
SEED = 42
def seed_everything(seed):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = True
seed_everything(SEED)A função seed_everything definida acima será executada antes de cada inicialização e treinamento de modelo.
Antes de mergulhar na implementação da rede neural, vamos resumir os principais elementos de um pipeline de treinamento/teste de aprendizado profundo no Torch:
Datasets/Dataloaders: É recomendado manipular dados com classes específicas do PyTorch. Dataset é a interface para acessar os dados. Dado o índice de uma amostra, ele fornece uma entrada-saída bem formada para o modelo. Dataloader recebe o Dataset como entrada e fornece um iterador para o laço de treinamento. Ele também permite criar lotes, embaralhar os dados e paralelizar a preparação dos dados.
Model/Module: Todo modelo no PyTorch é um torch.module. Ele tem uma função init na qual instancia todos os submódulos (camadas) necessários e inicializa seus pesos. Também tem uma função forward que define todas as operações do forward pass.
O otimizador: O otimizador é o objeto que implementa o algoritmo de otimização. Ele é chamado após o cálculo da perda para calcular as atualizações necessárias do modelo. O mais básico é o SGD, mas há muitos outros como RMSProp, Adagrad, Adam, ...
Laço de treinamento e avaliação: o laço de treinamento é o núcleo do treinamento de um modelo. Consiste em realizar várias iterações (épocas), obter todos os lotes de treinamento do carregador, realizar o forward pass, calcular a perda e chamar o otimizador. Após cada época, pode-se realizar uma avaliação para acompanhar a evolução do modelo e possivelmente interromper o processo.
As próximas subseções descrevem e implementam em detalhes cada um desses elementos.
Gerenciamento de dados: Datasets e Dataloaders¶
O primeiro passo é converter nossos dados em objetos que o PyTorch possa usar, como FloatTensors.
x_train = torch.FloatTensor(train_df[input_features].values)
x_test = torch.FloatTensor(test_df[input_features].values)
y_train = torch.FloatTensor(train_df[output_feature].values)
y_test = torch.FloatTensor(test_df[output_feature].values)Em seguida, vem a definição de um Dataset personalizado. Este dataset é inicializado com x_train/x_test e y_train/y_test e retorna as amostras individuais no formato exigido pelo nosso modelo, após enviá-las ao dispositivo correto.
class FraudDataset(torch.utils.data.Dataset):
def __init__(self, x, y):
'Initialization'
self.x = x
self.y = y
def __len__(self):
'Returns the total number of samples'
return len(self.x)
def __getitem__(self, index):
'Generates one sample of data'
# Select sample index
if self.y is not None:
return self.x[index].to(DEVICE), self.y[index].to(DEVICE)
else:
return self.x[index].to(DEVICE)Nota: Este primeiro Dataset personalizado FraudDataset parece inútil porque seu papel é muito limitado (simplesmente retornar uma linha de x e y) e porque as matrizes x e y já estão carregadas na RAM. Este exemplo é fornecido para fins educacionais. Mas o conceito de Dataset tem um grande interesse quando a preparação das amostras requer mais pré-processamento. Por exemplo, torna-se muito útil para a preparação de sequências ao usar modelos recorrentes (como um LSTM). Isso será abordado com mais profundidade mais adiante neste capítulo, mas, por exemplo, um Dataset para modelos sequenciais realiza várias operações antes de retornar uma amostra: busca o histórico de transações do mesmo titular do cartão e o anexa à transação atual antes de retornar a sequência inteira. Isso evita preparar todas as sequências com antecedência, o que implicaria repetir as características de várias transações na memória e consumir mais RAM do que o necessário. Os objetos Datasets também são úteis ao lidar com grandes conjuntos de dados de imagens para carregar as imagens dinamicamente.
Agora que o FraudDataset está definido, pode-se escolher os parâmetros de treinamento/avaliação e instanciar os DataLoaders. Por ora, vamos considerar um tamanho de lote de 64: isso significa que a cada passo de otimização, 64 amostras serão solicitadas ao Dataset, transformadas em um lote e passarão pelo forward pass em paralelo. Em seguida, a agregação (soma ou média) do gradiente de suas perdas será usada para a retropropagação.
Para o DataLoader de treinamento, a opção shuffle será definida como True para que a ordem dos dados vistos pelo modelo não seja a mesma de uma época para outra. Isso é recomendado e sabidamente benéfico no treinamento de Redes Neurais Ruder (2016).
train_loader_params = {'batch_size': 64,
'shuffle': True,
'num_workers': 0}
test_loader_params = {'batch_size': 64,
'num_workers': 0}
# Generators
training_set = FraudDataset(x_train, y_train)
testing_set = FraudDataset(x_test, y_test)
training_generator = torch.utils.data.DataLoader(training_set, **train_loader_params)
testing_generator = torch.utils.data.DataLoader(testing_set, **test_loader_params)O parâmetro num_workers permite paralelizar a preparação dos lotes. Pode ser útil quando o Dataset requer muito processamento antes de retornar uma amostra. Aqui não usamos multiprocessamento, portanto definimos num_workers como 0.
O modelo, também chamado de módulo¶
Após definir o pipeline de dados, o próximo passo é projetar o módulo. Vamos começar com uma primeira rede neural feed-forward relativamente simples.
Como sugerido na introdução, a ideia é definir várias camadas totalmente conectadas (torch.nn.Linear). Uma primeira camada fc1 que toma como entrada tantos neurônios quanto há características na entrada x. Ela pode ser seguida por uma camada oculta com um número escolhido de neurônios (hidden_size). Por fim, vem a camada de saída que possui um único neurônio de saída para ajustar o rótulo (fraude ou genuíno, representado por 1 e 0).
No passado, a função de ativação sigmoid costumava ser a escolha primária para todas as funções de ativação em todas as camadas de uma rede neural. Hoje, a escolha preferida é ReLU (ou variantes como eLU, leaky ReLU), pelo menos para os neurônios intermediários. Empiricamente, comprovou-se ser uma escolha melhor para otimização e velocidade Nair & Hinton (2010). Para neurônios de saída, a escolha depende do intervalo ou da distribuição esperada para o valor de saída a ser previsto.
Abaixo estão plotadas as saídas de várias funções de ativação em relação ao seu valor de entrada para mostrar como elas se comportam e como estão distribuídas:
Notebook Cell
%%capture
fig_activation, axs = plt.subplots(3, 2,figsize=(11, 13))
input_values = torch.arange(-5, 5, 0.05)
#linear activation
output_values = input_values
axs[0, 0].plot(input_values, output_values)
axs[0, 0].set_title('Linear')
axs[0, 0].set_ylim([-5.1,5.1])
#heavyside activation
output_values = input_values>0
axs[0, 1].plot(input_values, output_values)
axs[0, 1].set_title('Heavyside (perceptron)')
axs[0, 1].set_ylim([-0.1,1.1])
#sigmoid activation
activation = torch.nn.Sigmoid()
output_values = activation(input_values)
axs[1, 0].plot(input_values, output_values)
axs[1, 0].set_title('Sigmoid')
axs[1, 0].set_ylim([-1.1,1.1])
#tanh activation
activation = torch.nn.Tanh()
output_values = activation(input_values)
axs[1, 1].plot(input_values, output_values)
axs[1, 1].set_title('Tanh')
axs[1, 1].set_ylim([-1.1,1.1])
#relu activation
activation = torch.nn.ReLU()
output_values = activation(input_values)
axs[2, 0].plot(input_values, output_values)
axs[2, 0].set_title('ReLU')
axs[2, 0].set_ylim([-0.5,5.1])
#leaky relu activation
activation = torch.nn.LeakyReLU(negative_slope=0.05)
output_values = activation(input_values)
axs[2, 1].plot(input_values, output_values)
axs[2, 1].set_title('Leaky ReLU')
axs[2, 1].set_ylim([-0.5,5.1])fig_activation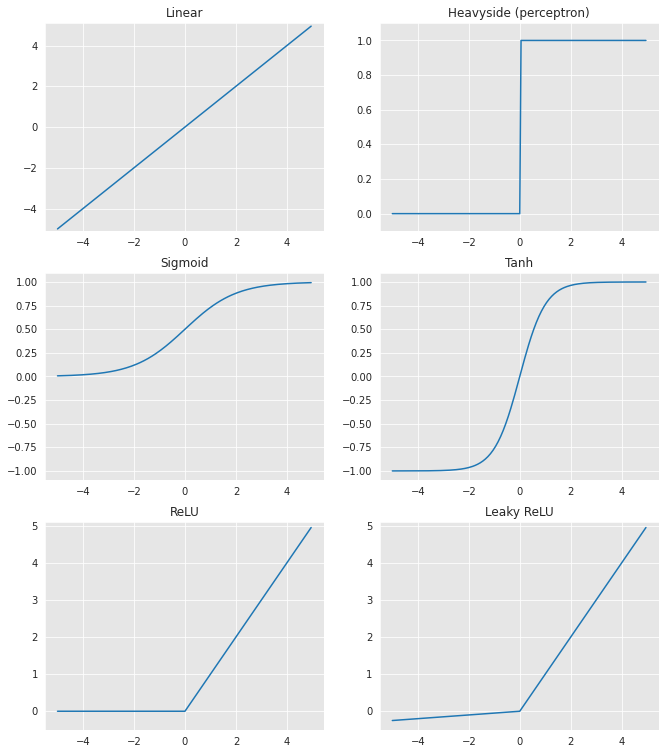
Para nossa rede neural de detecção de fraude, a ativação ReLU será usada para a camada oculta e uma ativação Sigmoid para a camada de saída. A primeira é a escolha primária para camadas intermediárias em aprendizado profundo. A segunda é a escolha primária para neurônios de saída em problemas de classificação binária porque produz valores entre 0 e 1 que podem ser interpretados como probabilidades.
Para implementar isso, vamos criar uma nova classe SimpleFraudMLP que herdará de um módulo torch. Suas camadas (fc1, relu, fc2, sigmoid) são inicializadas na função __init__ e serão usadas sucessivamente no forward pass.
class SimpleFraudMLP(torch.nn.Module):
def __init__(self, input_size, hidden_size):
super(SimpleFraudMLP, self).__init__()
# parameters
self.input_size = input_size
self.hidden_size = hidden_size
#input to hidden
self.fc1 = torch.nn.Linear(self.input_size, self.hidden_size)
self.relu = torch.nn.ReLU()
#hidden to output
self.fc2 = torch.nn.Linear(self.hidden_size, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
hidden = self.fc1(x)
relu = self.relu(hidden)
output = self.fc2(relu)
output = self.sigmoid(output)
return outputUma vez definido, instanciar o modelo com 1000 neurônios em sua camada oculta e enviá-lo ao dispositivo pode ser feito da seguinte forma:
model = SimpleFraudMLP(len(input_features), 1000).to(DEVICE)O otimizador e o laço de treinamento¶
A otimização está no núcleo do treinamento de redes neurais. A rede neural acima é projetada para produzir um único valor entre 0 e 1. O objetivo é que esse valor se aproxime o máximo de 1 (resp. 0) para uma entrada que descreve uma transação fraudulenta (resp. genuína).
Na prática, esse objetivo é formulado com um problema de otimização que visa minimizar ou maximizar alguma função de custo/perda. O papel da função de perda é precisamente medir a discrepância entre o valor previsto e o valor esperado (0 ou 1), também referido como o ground truth. Há muitas funções de perda (erro quadrático médio, entropia cruzada, divergência KL, hinge loss, erro absoluto médio) disponíveis no PyTorch, e cada uma serve a um propósito específico. Aqui focamos apenas na entropia cruzada binária porque é a função de perda mais relevante para problemas de classificação binária como a detecção de fraude. Ela é definida da seguinte forma:
Onde é o ground truth (em ) e a saída predita (em ).
criterion = torch.nn.BCELoss().to(DEVICE)Nota: Enviar o critério ao dispositivo só é necessário se ele armazena/atualiza variáveis de estado interno ou tem parâmetros. É desnecessário, mas não prejudicial no caso acima. Fazemos isso para mostrar a implementação mais geral.
Antes mesmo de treinar o modelo, pode-se já medir sua perda inicial no conjunto de teste. Para isso, o modelo deve ser colocado no modo eval:
model.eval()SimpleFraudMLP(
(fc1): Linear(in_features=15, out_features=1000, bias=True)
(relu): ReLU()
(fc2): Linear(in_features=1000, out_features=1, bias=True)
(sigmoid): Sigmoid()
)Em seguida, o processo consiste em iterar sobre o gerador de teste, fazer previsões e avaliar o criterion escolhido (aqui torch.nn.BCELoss)
def evaluate_model(model,generator,criterion):
model.eval()
batch_losses = []
for x_batch, y_batch in generator:
# Forward pass
y_pred = model(x_batch)
# Compute Loss
loss = criterion(y_pred.squeeze(), y_batch)
batch_losses.append(loss.item())
mean_loss = np.mean(batch_losses)
return mean_loss
evaluate_model(model,testing_generator,criterion)0.6754083250670742Lembre-se que o problema de otimização é definido da seguinte forma: minimizar a entropia cruzada binária total/média do modelo sobre todas as amostras do conjunto de dados de treinamento. Portanto, treinar o modelo consiste em aplicar um algoritmo de otimização (retropropagação) para resolver numericamente o problema de otimização.
O algoritmo de otimização ou optimizer pode ser o gradiente descendente estocástico padrão com uma taxa de aprendizado constante (torch.optim.SGD) ou com uma taxa de aprendizado adaptativa (torch.optim.Adagrad, torch.optim.Adam, etc...). Vários hiperparâmetros de otimização (taxa de aprendizado, momentum, tamanho do lote, ...) podem ser ajustados. Note que escolher o otimizador e os hiperparâmetros corretos impactará a velocidade de convergência e a qualidade do ótimo alcançado. Abaixo está uma ilustração mostrando quão rapidamente diferentes otimizadores podem alcançar o ótimo (representado com uma estrela) de um problema de otimização bidimensional ao longo do processo de treinamento.
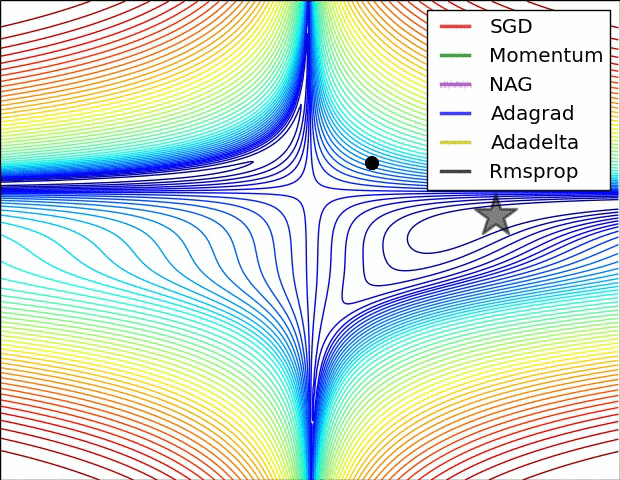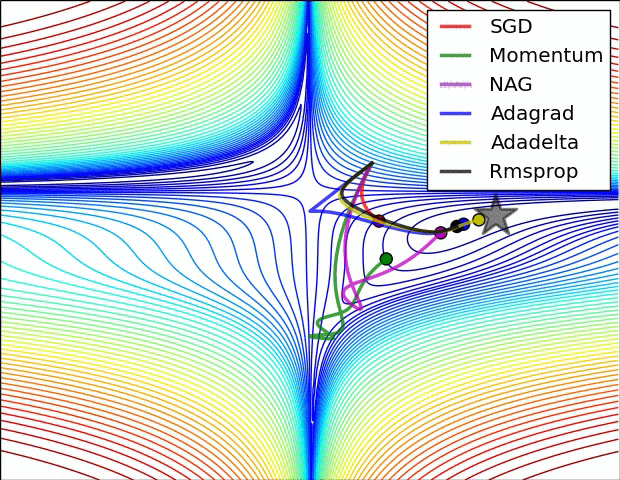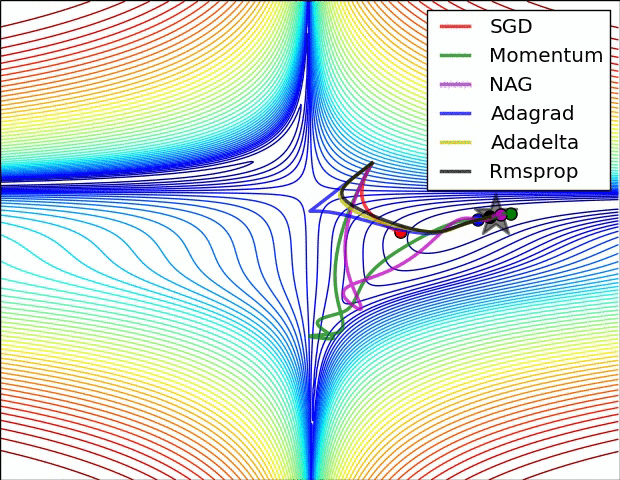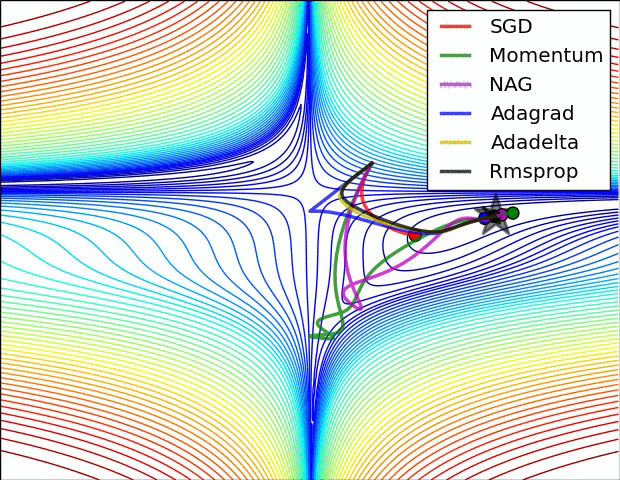
Fonte: https://
Aqui, vamos começar com a escolha arbitrária SGD, com uma taxa de aprendizado de 0.07.
optimizer = torch.optim.SGD(model.parameters(), lr = 0.07)E vamos implementar o laço de treinamento para nossa rede neural. Primeiro, o modelo deve ser colocado no modo de treinamento. Em seguida, várias iterações podem ser realizadas sobre o gerador de treinamento (cada iteração é chamada de época). Durante cada iteração, uma sucessão de lotes de treinamento é fornecida pelo gerador e um forward pass é realizado para obter as previsões do modelo. Em seguida, o critério é calculado entre as previsões e o ground truth e, finalmente, o backward pass é realizado para atualizar o modelo com o otimizador. Vamos começar definindo o número de épocas como 150 arbitrariamente.
n_epochs = 150
#Setting the model in training mode
model.train()
#Training loop
start_time=time.time()
epochs_train_losses = []
epochs_test_losses = []
for epoch in range(n_epochs):
model.train()
train_loss=[]
for x_batch, y_batch in training_generator:
# Removing previously computed gradients
optimizer.zero_grad()
# Performing the forward pass on the current batch
y_pred = model(x_batch)
# Computing the loss given the current predictions
loss = criterion(y_pred.squeeze(), y_batch)
# Computing the gradients over the backward pass
loss.backward()
# Performing an optimization step from the current gradients
optimizer.step()
# Storing the current step's loss for display purposes
train_loss.append(loss.item())
#showing last training loss after each epoch
epochs_train_losses.append(np.mean(train_loss))
print('Epoch {}: train loss: {}'.format(epoch, np.mean(train_loss)))
#evaluating the model on the test set after each epoch
val_loss = evaluate_model(model,testing_generator,criterion)
epochs_test_losses.append(val_loss)
print('test loss: {}'.format(val_loss))
print("")
training_execution_time=time.time()-start_timeEpoch 0: train loss: 0.035290839925911685
test loss: 0.02218067791398807
Epoch 1: train loss: 0.026134893728365197
test loss: 0.021469182402057047
Epoch 2: train loss: 0.0246561407407331
test loss: 0.020574169931166553
Epoch 3: train loss: 0.02423229484444929
test loss: 0.02107386154216703
Epoch 4: train loss: 0.023609313174003787
test loss: 0.0210356019355784
Epoch 5: train loss: 0.022873578722177552
test loss: 0.019786655369601145
Epoch 6: train loss: 0.022470950096939557
test loss: 0.019926515792759236
Epoch 7: train loss: 0.02219278062594085
test loss: 0.028550955727806318
Epoch 8: train loss: 0.022042355658335844
test loss: 0.02049338448594368
Epoch 9: train loss: 0.021793536896477114
test loss: 0.019674824729140616
Epoch 10: train loss: 0.021385407493539246
test loss: 0.01945593247867908
Epoch 11: train loss: 0.021190979423734237
test loss: 0.019786519943567813
Epoch 12: train loss: 0.020975370036498363
test loss: 0.019642970249983027
Epoch 13: train loss: 0.02076734111756866
test loss: 0.02052513674605928
Epoch 14: train loss: 0.020718587878236387
test loss: 0.01951982097012225
Epoch 15: train loss: 0.02052261461601278
test loss: 0.02042003110112238
Epoch 16: train loss: 0.020464933605720204
test loss: 0.01951952900969588
Epoch 17: train loss: 0.02031139105385157
test loss: 0.019883068325074693
Epoch 18: train loss: 0.02005033891893512
test loss: 0.021136936702628534
Epoch 19: train loss: 0.02018909637513194
test loss: 0.019560931436896415
Epoch 20: train loss: 0.019688749160297697
test loss: 0.019475146327190752
Epoch 21: train loss: 0.019545665294593013
test loss: 0.01990481851439469
Epoch 22: train loss: 0.01966426501701454
test loss: 0.019774360520063372
Epoch 23: train loss: 0.019467116548984597
test loss: 0.01942398223827126
Epoch 24: train loss: 0.019450417307287908
test loss: 0.02036607543897992
Epoch 25: train loss: 0.019348452326161104
test loss: 0.01966385325294501
Epoch 26: train loss: 0.019337252642960243
test loss: 0.01941954461092479
Epoch 27: train loss: 0.018811270653081438
test loss: 0.02393198154940046
Epoch 28: train loss: 0.01910782355698203
test loss: 0.01893333827312034
Epoch 29: train loss: 0.01889679451607306
test loss: 0.0191712700046878
Epoch 30: train loss: 0.018880406176723666
test loss: 0.019288057992725535
Epoch 31: train loss: 0.018777794314975487
test loss: 0.019147953246904152
Epoch 32: train loss: 0.018520837131095473
test loss: 0.02091556165090575
Epoch 33: train loss: 0.018716360642273444
test loss: 0.0200009971591782
Epoch 34: train loss: 0.018424111695009345
test loss: 0.019739989193721698
Epoch 35: train loss: 0.01847832238549308
test loss: 0.018952790981592586
Epoch 36: train loss: 0.01833176362245378
test loss: 0.020047389050911392
Epoch 37: train loss: 0.01840733835025275
test loss: 0.019157873926489766
Epoch 38: train loss: 0.018216611167059752
test loss: 0.01925634399612826
Epoch 39: train loss: 0.018247971196790058
test loss: 0.019123039215892087
Epoch 40: train loss: 0.01818877947228747
test loss: 0.018829473494242827
Epoch 41: train loss: 0.01801579236064007
test loss: 0.02009236856039642
Epoch 42: train loss: 0.01776886585207973
test loss: 0.021591765647557278
Epoch 43: train loss: 0.017698623019236925
test loss: 0.019427421221762085
Epoch 44: train loss: 0.017801190636184537
test loss: 0.020934971890116567
Epoch 45: train loss: 0.01757617438695864
test loss: 0.020313221684501902
Epoch 46: train loss: 0.017528431712814582
test loss: 0.019237118583715917
Epoch 47: train loss: 0.01771650113830862
test loss: 0.019054257457372534
Epoch 48: train loss: 0.017471631084365873
test loss: 0.018768446161779733
Epoch 49: train loss: 0.01762986665642107
test loss: 0.01871213165666953
Epoch 50: train loss: 0.017376677225189697
test loss: 0.018944991090944246
Epoch 51: train loss: 0.01731134802643582
test loss: 0.019197071075790106
Epoch 52: train loss: 0.017309057082782377
test loss: 0.018737028158102676
Epoch 53: train loss: 0.017282733941613764
test loss: 0.019252458449021702
Epoch 54: train loss: 0.017132009704110808
test loss: 0.018666087535711397
Epoch 55: train loss: 0.017102760767770647
test loss: 0.019643470577414647
Epoch 56: train loss: 0.017175561865192656
test loss: 0.02059196266723934
Epoch 57: train loss: 0.01697120425308196
test loss: 0.019769266178551858
Epoch 58: train loss: 0.017009864932326663
test loss: 0.020981014218425704
Epoch 59: train loss: 0.01673883281791712
test loss: 0.019321667669907328
Epoch 60: train loss: 0.01682613142252103
test loss: 0.019117679840779805
Epoch 61: train loss: 0.01683426277134231
test loss: 0.019079260448347592
Epoch 62: train loss: 0.01672560934473155
test loss: 0.019345737459433483
Epoch 63: train loss: 0.016557869988561853
test loss: 0.01874406040829129
Epoch 64: train loss: 0.01658480815486637
test loss: 0.018706792446582257
Epoch 65: train loss: 0.016553207060462174
test loss: 0.01922788784218672
Epoch 66: train loss: 0.01656300151070667
test loss: 0.019106791167186204
Epoch 67: train loss: 0.01634960973555121
test loss: 0.01892106298902394
Epoch 68: train loss: 0.01637238433257146
test loss: 0.01970208241961054
Epoch 69: train loss: 0.016304624745100346
test loss: 0.020026253195723334
Epoch 70: train loss: 0.016170715611227758
test loss: 0.01916889895606555
Epoch 71: train loss: 0.01625427650099445
test loss: 0.02002084003181251
Epoch 72: train loss: 0.016230222106588692
test loss: 0.01973510921013191
Epoch 73: train loss: 0.016057555596756222
test loss: 0.019140344628865876
Epoch 74: train loss: 0.016185298318253365
test loss: 0.019592884734356532
Epoch 75: train loss: 0.016135186496054263
test loss: 0.01912933145930866
Epoch 76: train loss: 0.015831470446746182
test loss: 0.01980635219605146
Epoch 77: train loss: 0.016163742120889904
test loss: 0.018802218763737884
Epoch 78: train loss: 0.015780061666036713
test loss: 0.01946689938368842
Epoch 79: train loss: 0.015624963660032394
test loss: 0.019016587150318426
Epoch 80: train loss: 0.015677704382997953
test loss: 0.019123383783840122
Epoch 81: train loss: 0.0156669273015934
test loss: 0.019544906248615823
Epoch 82: train loss: 0.015945699108347162
test loss: 0.01896711020402914
Epoch 83: train loss: 0.015803545366061742
test loss: 0.01882257679583143
Epoch 84: train loss: 0.01554203405311698
test loss: 0.019160992536484494
Epoch 85: train loss: 0.015593627287424059
test loss: 0.02269861174688054
Epoch 86: train loss: 0.015608393082631792
test loss: 0.01906792499428118
Epoch 87: train loss: 0.015573860835403621
test loss: 0.018713722084268098
Epoch 88: train loss: 0.015303678795089192
test loss: 0.018859464580432892
Epoch 89: train loss: 0.015624303529220682
test loss: 0.019072787957337533
Epoch 90: train loss: 0.015395271594389798
test loss: 0.01925187274229275
Epoch 91: train loss: 0.015199235446182222
test loss: 0.019277529898914892
Epoch 92: train loss: 0.015254125732097324
test loss: 0.019276228871915446
Epoch 93: train loss: 0.015056131997448768
test loss: 0.01940738342764494
Epoch 94: train loss: 0.015149828447423323
test loss: 0.019223913595550125
Epoch 95: train loss: 0.015336624930633124
test loss: 0.018798039220534184
Epoch 96: train loss: 0.015293191029795655
test loss: 0.019010778412255576
Epoch 97: train loss: 0.015008694369883785
test loss: 0.019653212369427814
Epoch 98: train loss: 0.015102840106516498
test loss: 0.019357315392239054
Epoch 99: train loss: 0.015250559438101515
test loss: 0.018675536756820592
Epoch 100: train loss: 0.014856535338572485
test loss: 0.019066266391966104
Epoch 101: train loss: 0.014888768182264608
test loss: 0.019562842087552074
Epoch 102: train loss: 0.015026554204328614
test loss: 0.019209888092900036
Epoch 103: train loss: 0.01470694792277262
test loss: 0.019527851007887724
Epoch 104: train loss: 0.014760883615509944
test loss: 0.019603360463092235
Epoch 105: train loss: 0.014778099678375702
test loss: 0.01938396310747466
Epoch 106: train loss: 0.014656903555221966
test loss: 0.021055019364553493
Epoch 107: train loss: 0.014742576584012136
test loss: 0.019785542262680512
Epoch 108: train loss: 0.014616272993597133
test loss: 0.01918475812159322
Epoch 109: train loss: 0.014744729096057526
test loss: 0.019482410666562207
Epoch 110: train loss: 0.01478639586868968
test loss: 0.020755630938069685
Epoch 111: train loss: 0.014646960172508015
test loss: 0.019398048360927622
Epoch 112: train loss: 0.01472245290016775
test loss: 0.019159860661682446
Epoch 113: train loss: 0.014562352736468128
test loss: 0.019282711160597446
Epoch 114: train loss: 0.014577984230900334
test loss: 0.0193002821399542
Epoch 115: train loss: 0.014344233295217433
test loss: 0.020133854305154658
Epoch 116: train loss: 0.014341190461110107
test loss: 0.018970135359324077
Epoch 117: train loss: 0.014129704338756278
test loss: 0.01917728733261904
Epoch 118: train loss: 0.01430605129179519
test loss: 0.021149112656150264
Epoch 119: train loss: 0.014255904436282473
test loss: 0.018764410451399347
Epoch 120: train loss: 0.014217122137308613
test loss: 0.019560121930464764
Epoch 121: train loss: 0.014424033683536841
test loss: 0.019554240529785296
Epoch 122: train loss: 0.013943179655692972
test loss: 0.019388370742924505
Epoch 123: train loss: 0.014217297587438277
test loss: 0.019506819887417978
Epoch 124: train loss: 0.014320325663093509
test loss: 0.019013977995048798
Epoch 125: train loss: 0.014072354838150605
test loss: 0.019356480262935637
Epoch 126: train loss: 0.014174860061636348
test loss: 0.019924982428475582
Epoch 127: train loss: 0.014051309499243181
test loss: 0.01943692742414598
Epoch 128: train loss: 0.013706501579084047
test loss: 0.019356113880468657
Epoch 129: train loss: 0.013928943851151433
test loss: 0.023672922889693842
Epoch 130: train loss: 0.013996419837717392
test loss: 0.019937841926443746
Epoch 131: train loss: 0.01354328335033992
test loss: 0.018866847201061878
Epoch 132: train loss: 0.013858712335960314
test loss: 0.019526662786376717
Epoch 133: train loss: 0.013627326418468455
test loss: 0.019507627395780616
Epoch 134: train loss: 0.01363016927038159
test loss: 0.020167008346695766
Epoch 135: train loss: 0.014017050037538007
test loss: 0.019339477675381647
Epoch 136: train loss: 0.013699612338492446
test loss: 0.020203967244190785
Epoch 137: train loss: 0.01374569109071234
test loss: 0.020616953133759535
Epoch 138: train loss: 0.013681518706248508
test loss: 0.019543899178865818
Epoch 139: train loss: 0.013486423249944396
test loss: 0.020067024185707123
Epoch 140: train loss: 0.013582284482316487
test loss: 0.019309879371676077
Epoch 141: train loss: 0.013726865840729302
test loss: 0.019650126973995898
Epoch 142: train loss: 0.013600045634118164
test loss: 0.019795151278770167
Epoch 143: train loss: 0.013150996427657836
test loss: 0.02032829227653597
Epoch 144: train loss: 0.01349108792122783
test loss: 0.01965160865000445
Epoch 145: train loss: 0.013093949061199017
test loss: 0.020522381957106928
Epoch 146: train loss: 0.01322205882253866
test loss: 0.019739131280336053
Epoch 147: train loss: 0.013211467955250392
test loss: 0.019430110360044398
Epoch 148: train loss: 0.013549773727725752
test loss: 0.019252411015017387
Epoch 149: train loss: 0.01308232067314798
test loss: 0.019413354424067133
Após treinar o modelo, uma boa prática é analisar os logs de treinamento.
ma_window = 10
plt.plot(np.arange(len(epochs_train_losses)-ma_window + 1)+1, np.convolve(epochs_train_losses, np.ones(ma_window)/ma_window, mode='valid'))
plt.plot(np.arange(len(epochs_test_losses)-ma_window + 1)+1, np.convolve(epochs_test_losses, np.ones(ma_window)/ma_window, mode='valid'))
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train','valid'])
#plt.ylim([0.01,0.06])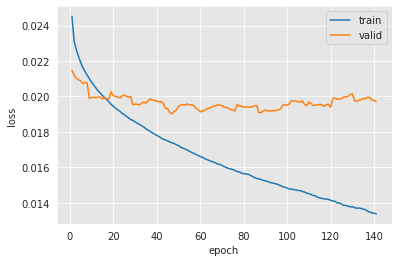
print(training_execution_time)851.1251120567322
Pode-se notar aqui como a perda de treinamento diminui época após época. Isso significa que a otimização está indo bem: a taxa de aprendizado escolhida permite atualizar o modelo em direção a uma solução melhor (menor perda) para o conjunto de treinamento. No entanto, as redes neurais são conhecidas por serem modelos muito expressivos. De fato, o teorema da aproximação universal mostra que, com neurônios/camadas suficientes, pode-se modelar qualquer função com uma rede neural Cybenko (1989). Portanto, é esperado que uma rede neural complexa seja capaz de ajustar quase perfeitamente os dados de treinamento. Mas o objetivo final é obter um modelo que generalize bem em dados não vistos (como o conjunto de validação). Observando a perda de validação, pode-se ver que ela começa a diminuir (com oscilações) e atinge um ótimo em torno de 0,019, e para de diminuir (ou até começa a aumentar). Esse fenômeno é referido como sobreajuste.
Muitos aspectos podem ser melhorados no treinamento. Embora não se possa medir o desempenho no conjunto de teste final durante o treinamento, pode-se depender de um conjunto de validação e tentar parar o treinamento antes do sobreajuste (veja Seleção de modelos). Também se pode mudar o algoritmo de otimização e os parâmetros para acelerar o treinamento e alcançar um ótimo melhor. Isso é investigado mais tarde, no parágrafo de otimização.
Por ora, vamos considerar este modelo final ajustado e avaliá-lo da mesma forma que os outros modelos nos capítulos anteriores. Para isso, vamos criar um DataFrame de previsões e chamar a função performance_assessment das funções compartilhadas.
start_time=time.time()
predictions_test = model(x_test.to(DEVICE))
prediction_execution_time = time.time()-start_time
predictions_train = model(x_train.to(DEVICE))
print("Predictions took", prediction_execution_time,"seconds.")Predictions took 0.0022110939025878906 seconds.
predictions_df=test_df
predictions_df['predictions']=predictions_test.detach().cpu().numpy()
performance_assessment(predictions_df, top_k_list=[100])Esta primeira rede feed-forward já obtém um desempenho razoável no conjunto de teste (consulte o Capítulo 3.4 para comparação). Mas vários elementos podem ser modificados para melhorar a AUC ROC, reduzir o tempo de treinamento, etc.
Como mencionado acima, para o primeiro modelo, a otimização não foi realizada corretamente porque o desempenho de validação não é explorado durante o processo de treinamento. Para evitar sobreajuste na prática, é necessário levá-lo em consideração (Veja o Capítulo 5, Validação holdout).
delta_valid = delta_test
start_date_training_with_valid = start_date_training+datetime.timedelta(days=-(delta_delay+delta_valid))
(train_df, valid_df)=get_train_test_set(transactions_df,start_date_training_with_valid,
delta_train=delta_train,delta_delay=delta_delay,delta_test=delta_test)
# By default, scales input data
(train_df, valid_df)=scaleData(train_df, valid_df, input_features)Vamos implementar uma estratégia de parada antecipada (early stopping). A ideia é detectar o sobreajuste, ou seja, quando o erro de validação começa a aumentar, e parar o processo de treinamento. Às vezes, o erro de validação pode aumentar em uma determinada época, mas depois diminuir novamente. Por essa razão, é importante também considerar um parâmetro de paciência, ou seja, um número de iterações pelo qual o processo de treinamento aguarda para ter certeza de que o erro está definitivamente aumentando.
class EarlyStopping:
def __init__(self, patience=2, verbose=False):
self.patience = patience
self.verbose = verbose
self.counter = 0
self.best_score = np.Inf
def continue_training(self,current_score):
if self.best_score > current_score:
self.best_score = current_score
self.counter = 0
if self.verbose:
print("New best score:", current_score)
else:
self.counter+=1
if self.verbose:
print(self.counter, " iterations since best score.")
return self.counter <= self.patience seed_everything(SEED)
model = SimpleFraudMLP(len(input_features), 1000).to(DEVICE)
def prepare_generators(train_df,valid_df,batch_size=64):
x_train = torch.FloatTensor(train_df[input_features].values)
x_valid = torch.FloatTensor(valid_df[input_features].values)
y_train = torch.FloatTensor(train_df[output_feature].values)
y_valid = torch.FloatTensor(valid_df[output_feature].values)
train_loader_params = {'batch_size': batch_size,
'shuffle': True,
'num_workers': 0}
valid_loader_params = {'batch_size': batch_size,
'num_workers': 0}
# Generators
training_set = FraudDataset(x_train, y_train)
valid_set = FraudDataset(x_valid, y_valid)
training_generator = torch.utils.data.DataLoader(training_set, **train_loader_params)
valid_generator = torch.utils.data.DataLoader(valid_set, **valid_loader_params)
return training_generator,valid_generator
training_generator,valid_generator = prepare_generators(train_df,valid_df,batch_size=64)
criterion = torch.nn.BCELoss().to(DEVICE)
optimizer = torch.optim.SGD(model.parameters(), lr = 0.0005)O laço de treinamento agora pode ser adaptado para integrar a parada antecipada:
def training_loop(model,training_generator,valid_generator,optimizer,criterion,max_epochs=100,apply_early_stopping=True,patience=2,verbose=False):
#Setting the model in training mode
model.train()
if apply_early_stopping:
early_stopping = EarlyStopping(verbose=verbose,patience=patience)
all_train_losses = []
all_valid_losses = []
#Training loop
start_time=time.time()
for epoch in range(max_epochs):
model.train()
train_loss=[]
for x_batch, y_batch in training_generator:
optimizer.zero_grad()
y_pred = model(x_batch)
loss = criterion(y_pred.squeeze(), y_batch)
loss.backward()
optimizer.step()
train_loss.append(loss.item())
#showing last training loss after each epoch
all_train_losses.append(np.mean(train_loss))
if verbose:
print('')
print('Epoch {}: train loss: {}'.format(epoch, np.mean(train_loss)))
#evaluating the model on the test set after each epoch
valid_loss = evaluate_model(model,valid_generator,criterion)
all_valid_losses.append(valid_loss)
if verbose:
print('valid loss: {}'.format(valid_loss))
if apply_early_stopping:
if not early_stopping.continue_training(valid_loss):
if verbose:
print("Early stopping")
break
training_execution_time=time.time()-start_time
return model,training_execution_time,all_train_losses,all_valid_losses
model,training_execution_time,train_losses,valid_losses = training_loop(model,training_generator,valid_generator,optimizer,criterion,max_epochs=500,verbose=True)
Epoch 0: train loss: 0.1913328490845047
valid loss: 0.09375773465535679
New best score: 0.09375773465535679
Epoch 1: train loss: 0.09739777461463589
valid loss: 0.06964004442421465
New best score: 0.06964004442421465
Epoch 2: train loss: 0.07702973348410874
valid loss: 0.05692868165753252
New best score: 0.05692868165753252
Epoch 3: train loss: 0.06568225591940303
valid loss: 0.05035814772171727
New best score: 0.05035814772171727
Epoch 4: train loss: 0.06026483534071345
valid loss: 0.04624887502299306
New best score: 0.04624887502299306
Epoch 5: train loss: 0.056940919349244286
valid loss: 0.04359364376449194
New best score: 0.04359364376449194
Epoch 6: train loss: 0.054429791377141476
valid loss: 0.04157831529816969
New best score: 0.04157831529816969
Epoch 7: train loss: 0.052457363431094424
valid loss: 0.04001519718599287
New best score: 0.04001519718599287
Epoch 8: train loss: 0.050785390330731414
valid loss: 0.03874376885531867
New best score: 0.03874376885531867
Epoch 9: train loss: 0.04932902906317955
valid loss: 0.03767143583403585
New best score: 0.03767143583403585
Epoch 10: train loss: 0.04800296786292874
valid loss: 0.036723700269568164
New best score: 0.036723700269568164
Epoch 11: train loss: 0.0467992290715557
valid loss: 0.03594793021129292
New best score: 0.03594793021129292
Epoch 12: train loss: 0.045708294409410904
valid loss: 0.03513609678204594
New best score: 0.03513609678204594
Epoch 13: train loss: 0.044724561932031955
valid loss: 0.034476374743170425
New best score: 0.034476374743170425
Epoch 14: train loss: 0.04376962262225367
valid loss: 0.03383087654867785
New best score: 0.03383087654867785
Epoch 15: train loss: 0.04289912999684194
valid loss: 0.03328745677008655
New best score: 0.03328745677008655
Epoch 16: train loss: 0.04211900097871801
valid loss: 0.03279653103523404
New best score: 0.03279653103523404
Epoch 17: train loss: 0.04133166673274472
valid loss: 0.03225325013668648
New best score: 0.03225325013668648
Epoch 18: train loss: 0.0406280806302369
valid loss: 0.03180343335687789
New best score: 0.03180343335687789
Epoch 19: train loss: 0.039973342111405435
valid loss: 0.03134397429113831
New best score: 0.03134397429113831
Epoch 20: train loss: 0.0393654040050253
valid loss: 0.03092465683960361
New best score: 0.03092465683960361
Epoch 21: train loss: 0.03881909422234527
valid loss: 0.03055180991577402
New best score: 0.03055180991577402
Epoch 22: train loss: 0.03827888194478721
valid loss: 0.030233140898960047
New best score: 0.030233140898960047
Epoch 23: train loss: 0.03780341152338593
valid loss: 0.029879456755954548
New best score: 0.029879456755954548
Epoch 24: train loss: 0.0373732605668579
valid loss: 0.029598503501810987
New best score: 0.029598503501810987
Epoch 25: train loss: 0.03695048963789958
valid loss: 0.02927447263802824
New best score: 0.02927447263802824
Epoch 26: train loss: 0.036615738789435213
valid loss: 0.02896905600607314
New best score: 0.02896905600607314
Epoch 27: train loss: 0.036207901082405854
valid loss: 0.02868095043018623
New best score: 0.02868095043018623
Epoch 28: train loss: 0.035899569037820905
valid loss: 0.02845362258688267
New best score: 0.02845362258688267
Epoch 29: train loss: 0.035585474596406916
valid loss: 0.0282213641676665
New best score: 0.0282213641676665
Epoch 30: train loss: 0.03530147399692787
valid loss: 0.028004939610881557
New best score: 0.028004939610881557
Epoch 31: train loss: 0.03506627075336731
valid loss: 0.027803662563343354
New best score: 0.027803662563343354
Epoch 32: train loss: 0.034790630911318426
valid loss: 0.02759764206499024
New best score: 0.02759764206499024
Epoch 33: train loss: 0.03455478501155346
valid loss: 0.027440349387178004
New best score: 0.027440349387178004
Epoch 34: train loss: 0.03433797730980566
valid loss: 0.027257424232656837
New best score: 0.027257424232656837
Epoch 35: train loss: 0.03413862231931868
valid loss: 0.027060411588029295
New best score: 0.027060411588029295
Epoch 36: train loss: 0.03393446611165715
valid loss: 0.026920503835433006
New best score: 0.026920503835433006
Epoch 37: train loss: 0.03374493613983389
valid loss: 0.026792875826969497
New best score: 0.026792875826969497
Epoch 38: train loss: 0.033567726451380044
valid loss: 0.026641243333353208
New best score: 0.026641243333353208
Epoch 39: train loss: 0.03341253091052288
valid loss: 0.026517281875706435
New best score: 0.026517281875706435
Epoch 40: train loss: 0.03323691976292283
valid loss: 0.026393191043613224
New best score: 0.026393191043613224
Epoch 41: train loss: 0.03309235302152657
valid loss: 0.026288463208885466
New best score: 0.026288463208885466
Epoch 42: train loss: 0.03293785912716622
valid loss: 0.026179640229709977
New best score: 0.026179640229709977
Epoch 43: train loss: 0.03279621294436061
valid loss: 0.02603624322212459
New best score: 0.02603624322212459
Epoch 44: train loss: 0.03266078568407357
valid loss: 0.025929251656730157
New best score: 0.025929251656730157
Epoch 45: train loss: 0.0325486152223623
valid loss: 0.025851620896592167
New best score: 0.025851620896592167
Epoch 46: train loss: 0.03240748641017048
valid loss: 0.025761372189907754
New best score: 0.025761372189907754
Epoch 47: train loss: 0.03228628662429095
valid loss: 0.02565560621245067
New best score: 0.02565560621245067
Epoch 48: train loss: 0.032172352504733076
valid loss: 0.02557775412731972
New best score: 0.02557775412731972
Epoch 49: train loss: 0.03205738163439212
valid loss: 0.02546982061209493
New best score: 0.02546982061209493
Epoch 50: train loss: 0.03195213218420801
valid loss: 0.025422557447451713
New best score: 0.025422557447451713
Epoch 51: train loss: 0.03188026639638223
valid loss: 0.025320453349948743
New best score: 0.025320453349948743
Epoch 52: train loss: 0.03174724143548703
valid loss: 0.025241477420563742
New best score: 0.025241477420563742
Epoch 53: train loss: 0.03165151671476192
valid loss: 0.025179216701313446
New best score: 0.025179216701313446
Epoch 54: train loss: 0.03155849563593604
valid loss: 0.025118731856956834
New best score: 0.025118731856956834
Epoch 55: train loss: 0.03148277452568137
valid loss: 0.025032085685130677
New best score: 0.025032085685130677
Epoch 56: train loss: 0.03140361373264691
valid loss: 0.02498556302880736
New best score: 0.02498556302880736
Epoch 57: train loss: 0.03129253131212813
valid loss: 0.024921924847844844
New best score: 0.024921924847844844
Epoch 58: train loss: 0.03121994449432056
valid loss: 0.024863514974407974
New best score: 0.024863514974407974
Epoch 59: train loss: 0.031125062090090083
valid loss: 0.024810835887560917
New best score: 0.024810835887560917
Epoch 60: train loss: 0.031047032346475305
valid loss: 0.02475847759859158
New best score: 0.02475847759859158
Epoch 61: train loss: 0.030969077953846187
valid loss: 0.024699673177216386
New best score: 0.024699673177216386
Epoch 62: train loss: 0.03090025394390129
valid loss: 0.024641404968121502
New best score: 0.024641404968121502
Epoch 63: train loss: 0.030862686669909847
valid loss: 0.024588247217604373
New best score: 0.024588247217604373
Epoch 64: train loss: 0.030749225534007208
valid loss: 0.02454875350568464
New best score: 0.02454875350568464
Epoch 65: train loss: 0.030681132341612193
valid loss: 0.02449575268454809
New best score: 0.02449575268454809
Epoch 66: train loss: 0.030624778894084305
valid loss: 0.02444306879655504
New best score: 0.02444306879655504
Epoch 67: train loss: 0.030545241735879167
valid loss: 0.02441780281487262
New best score: 0.02441780281487262
Epoch 68: train loss: 0.030487007927149534
valid loss: 0.024349838984835018
New best score: 0.024349838984835018
Epoch 69: train loss: 0.030432759078324597
valid loss: 0.0243099326176233
New best score: 0.0243099326176233
Epoch 70: train loss: 0.03041622593458457
valid loss: 0.024272297082540115
New best score: 0.024272297082540115
Epoch 71: train loss: 0.030300165977093958
valid loss: 0.024237286337127125
New best score: 0.024237286337127125
Epoch 72: train loss: 0.030241341069233863
valid loss: 0.02417136665301326
New best score: 0.02417136665301326
Epoch 73: train loss: 0.03018520880436229
valid loss: 0.024120652137700815
New best score: 0.024120652137700815
Epoch 74: train loss: 0.03013364729372674
valid loss: 0.024093669633345444
New best score: 0.024093669633345444
Epoch 75: train loss: 0.030071343618924114
valid loss: 0.024088013470121992
New best score: 0.024088013470121992
Epoch 76: train loss: 0.03001892710608532
valid loss: 0.024011776422002848
New best score: 0.024011776422002848
Epoch 77: train loss: 0.029969145755335175
valid loss: 0.023975220763333183
New best score: 0.023975220763333183
Epoch 78: train loss: 0.02991881920848341
valid loss: 0.02395541004638081
New best score: 0.02395541004638081
Epoch 79: train loss: 0.02986845553449282
valid loss: 0.02393013280867268
New best score: 0.02393013280867268
Epoch 80: train loss: 0.029822142165907468
valid loss: 0.023900585737629015
New best score: 0.023900585737629015
Epoch 81: train loss: 0.029775497005419024
valid loss: 0.023856908664402494
New best score: 0.023856908664402494
Epoch 82: train loss: 0.029724118022878526
valid loss: 0.023814442141307263
New best score: 0.023814442141307263
Epoch 83: train loss: 0.029677337395021937
valid loss: 0.023799496913542512
New best score: 0.023799496913542512
Epoch 84: train loss: 0.029632960171946263
valid loss: 0.023763575294701373
New best score: 0.023763575294701373
Epoch 85: train loss: 0.029605798028190453
valid loss: 0.023751684766049025
New best score: 0.023751684766049025
Epoch 86: train loss: 0.02954536723106544
valid loss: 0.023722586527853553
New best score: 0.023722586527853553
Epoch 87: train loss: 0.02950361069228614
valid loss: 0.02369303354774627
New best score: 0.02369303354774627
Epoch 88: train loss: 0.029461566101934185
valid loss: 0.023656040358565788
New best score: 0.023656040358565788
Epoch 89: train loss: 0.02946843091691408
valid loss: 0.023631087498983645
New best score: 0.023631087498983645
Epoch 90: train loss: 0.029390632712244846
valid loss: 0.023596429532454884
New best score: 0.023596429532454884
Epoch 91: train loss: 0.02936394038088406
valid loss: 0.02358429558254534
New best score: 0.02358429558254534
Epoch 92: train loss: 0.0292979597964771
valid loss: 0.023570768526740005
New best score: 0.023570768526740005
Epoch 93: train loss: 0.02927289446072393
valid loss: 0.02350624052634656
New best score: 0.02350624052634656
Epoch 94: train loss: 0.029223493826807074
valid loss: 0.023486437192542956
New best score: 0.023486437192542956
Epoch 95: train loss: 0.02918589157346159
valid loss: 0.023464245512277458
New best score: 0.023464245512277458
Epoch 96: train loss: 0.029144589333789668
valid loss: 0.023416468044081346
New best score: 0.023416468044081346
Epoch 97: train loss: 0.02912758567671418
valid loss: 0.023399247189912476
New best score: 0.023399247189912476
Epoch 98: train loss: 0.02907554728173104
valid loss: 0.023369539759880126
New best score: 0.023369539759880126
Epoch 99: train loss: 0.0290912055496365
valid loss: 0.0233648722342475
New best score: 0.0233648722342475
Epoch 100: train loss: 0.029008036460878815
valid loss: 0.023355054730915877
New best score: 0.023355054730915877
Epoch 101: train loss: 0.028976725650564847
valid loss: 0.02335138803861954
New best score: 0.02335138803861954
Epoch 102: train loss: 0.028942817495779684
valid loss: 0.023320194269667884
New best score: 0.023320194269667884
Epoch 103: train loss: 0.028908641032169415
valid loss: 0.02326713968322821
New best score: 0.02326713968322821
Epoch 104: train loss: 0.02887047877260101
valid loss: 0.023294708241143675
1 iterations since best score.
Epoch 105: train loss: 0.028846722699872738
valid loss: 0.023242005218797532
New best score: 0.023242005218797532
Epoch 106: train loss: 0.028813878833547763
valid loss: 0.023228671088244744
New best score: 0.023228671088244744
Epoch 107: train loss: 0.0287828464368198
valid loss: 0.023191343482247873
New best score: 0.023191343482247873
Epoch 108: train loss: 0.028756805844284437
valid loss: 0.02318918440959167
New best score: 0.02318918440959167
Epoch 109: train loss: 0.028723424002724072
valid loss: 0.023160055014075802
New best score: 0.023160055014075802
Epoch 110: train loss: 0.02869303663547042
valid loss: 0.023144750117675448
New best score: 0.023144750117675448
Epoch 111: train loss: 0.028664296415472405
valid loss: 0.023132199461475177
New best score: 0.023132199461475177
Epoch 112: train loss: 0.02863481912421807
valid loss: 0.02309743918585362
New best score: 0.02309743918585362
Epoch 113: train loss: 0.02860824634382469
valid loss: 0.023083067486123716
New best score: 0.023083067486123716
Epoch 114: train loss: 0.028580453087679016
valid loss: 0.023065064372393033
New best score: 0.023065064372393033
Epoch 115: train loss: 0.028583913627721683
valid loss: 0.023059428991403817
New best score: 0.023059428991403817
Epoch 116: train loss: 0.028539594658160757
valid loss: 0.023021483237605767
New best score: 0.023021483237605767
Epoch 117: train loss: 0.028498090858825875
valid loss: 0.0230103495645291
New best score: 0.0230103495645291
Epoch 118: train loss: 0.02847093119651941
valid loss: 0.022989906041623383
New best score: 0.022989906041623383
Epoch 119: train loss: 0.028445423570689504
valid loss: 0.02298577562040685
New best score: 0.02298577562040685
Epoch 120: train loss: 0.02843944391526859
valid loss: 0.02297029253553416
New best score: 0.02297029253553416
Epoch 121: train loss: 0.02839335314034668
valid loss: 0.022956622955821904
New best score: 0.022956622955821904
Epoch 122: train loss: 0.02836992497084908
valid loss: 0.02292723284062263
New best score: 0.02292723284062263
Epoch 123: train loss: 0.028345879081175456
valid loss: 0.02292975828311116
1 iterations since best score.
Epoch 124: train loss: 0.028317808104148332
valid loss: 0.022887073724932684
New best score: 0.022887073724932684
Epoch 125: train loss: 0.028294943689313463
valid loss: 0.02287090510369121
New best score: 0.02287090510369121
Epoch 126: train loss: 0.028270350065105462
valid loss: 0.02287252673808017
1 iterations since best score.
Epoch 127: train loss: 0.028275767688721375
valid loss: 0.022849381183492924
New best score: 0.022849381183492924
Epoch 128: train loss: 0.028224381290101953
valid loss: 0.022848820957085472
New best score: 0.022848820957085472
Epoch 129: train loss: 0.028200230417402737
valid loss: 0.022820619613064523
New best score: 0.022820619613064523
Epoch 130: train loss: 0.028176542286481532
valid loss: 0.02281207342764434
New best score: 0.02281207342764434
Epoch 131: train loss: 0.02815248865641326
valid loss: 0.02280835929693135
New best score: 0.02280835929693135
Epoch 132: train loss: 0.028131953311948742
valid loss: 0.022787688048607337
New best score: 0.022787688048607337
Epoch 133: train loss: 0.02810920693534987
valid loss: 0.022765636864713713
New best score: 0.022765636864713713
Epoch 134: train loss: 0.028111470830279543
valid loss: 0.022741809560627234
New best score: 0.022741809560627234
Epoch 135: train loss: 0.028099982538946102
valid loss: 0.022723406667266386
New best score: 0.022723406667266386
Epoch 136: train loss: 0.028045140870136296
valid loss: 0.022711630711901954
New best score: 0.022711630711901954
Epoch 137: train loss: 0.028020675978124725
valid loss: 0.02270077230469858
New best score: 0.02270077230469858
Epoch 138: train loss: 0.028001034442232085
valid loss: 0.022680820606374105
New best score: 0.022680820606374105
Epoch 139: train loss: 0.02798138180169781
valid loss: 0.022678537435239295
New best score: 0.022678537435239295
Epoch 140: train loss: 0.027956969244939848
valid loss: 0.022645182927938108
New best score: 0.022645182927938108
Epoch 141: train loss: 0.02793828301206516
valid loss: 0.02263188965267456
New best score: 0.02263188965267456
Epoch 142: train loss: 0.027918862506798887
valid loss: 0.022637629473602268
1 iterations since best score.
Epoch 143: train loss: 0.02789739242409415
valid loss: 0.022616112196838352
New best score: 0.022616112196838352
Epoch 144: train loss: 0.02788659036435529
valid loss: 0.022604331468827413
New best score: 0.022604331468827413
Epoch 145: train loss: 0.027857656635381423
valid loss: 0.02258195599510533
New best score: 0.02258195599510533
Epoch 146: train loss: 0.027839381755712527
valid loss: 0.022589396648974122
1 iterations since best score.
Epoch 147: train loss: 0.02781995714808606
valid loss: 0.022585400501062555
2 iterations since best score.
Epoch 148: train loss: 0.0278003837200537
valid loss: 0.022568948230772316
New best score: 0.022568948230772316
Epoch 149: train loss: 0.027782129139833536
valid loss: 0.02255174289432054
New best score: 0.02255174289432054
Epoch 150: train loss: 0.02776255571714337
valid loss: 0.02253183182914197
New best score: 0.02253183182914197
Epoch 151: train loss: 0.027743494876679993
valid loss: 0.022533289264745075
1 iterations since best score.
Epoch 152: train loss: 0.02775508448228696
valid loss: 0.02251671864193116
New best score: 0.02251671864193116
Epoch 153: train loss: 0.027706991043075363
valid loss: 0.02250744028123798
New best score: 0.02250744028123798
Epoch 154: train loss: 0.02771934628865929
valid loss: 0.022485052686581602
New best score: 0.022485052686581602
Epoch 155: train loss: 0.027669533327476514
valid loss: 0.02247313265154352
New best score: 0.02247313265154352
Epoch 156: train loss: 0.027651057377623228
valid loss: 0.022459305293827517
New best score: 0.022459305293827517
Epoch 157: train loss: 0.02763525061585351
valid loss: 0.02245297230032013
New best score: 0.02245297230032013
Epoch 158: train loss: 0.027679454755388827
valid loss: 0.02244625367056273
New best score: 0.02244625367056273
Epoch 159: train loss: 0.027604569671639947
valid loss: 0.022432177785600794
New best score: 0.022432177785600794
Epoch 160: train loss: 0.027581669508397622
valid loss: 0.022430453333199596
New best score: 0.022430453333199596
Epoch 161: train loss: 0.027564720215941876
valid loss: 0.02241775643925279
New best score: 0.02241775643925279
Epoch 162: train loss: 0.027579767085268138
valid loss: 0.02239429562255903
New best score: 0.02239429562255903
Epoch 163: train loss: 0.02753278665911463
valid loss: 0.02241013890763368
1 iterations since best score.
Epoch 164: train loss: 0.027514616644275278
valid loss: 0.02239029550762043
New best score: 0.02239029550762043
Epoch 165: train loss: 0.0274962666923052
valid loss: 0.022379505229716906
New best score: 0.022379505229716906
Epoch 166: train loss: 0.027480541330666047
valid loss: 0.022358953526823735
New best score: 0.022358953526823735
Epoch 167: train loss: 0.027462416702220806
valid loss: 0.02235966007164145
1 iterations since best score.
Epoch 168: train loss: 0.027444096298596284
valid loss: 0.022322355202129468
New best score: 0.022322355202129468
Epoch 169: train loss: 0.027431257501383442
valid loss: 0.022331677362974225
1 iterations since best score.
Epoch 170: train loss: 0.027412834448827143
valid loss: 0.02231330466558495
New best score: 0.02231330466558495
Epoch 171: train loss: 0.027397032502823177
valid loss: 0.022294207703820915
New best score: 0.022294207703820915
Epoch 172: train loss: 0.0274509967615949
valid loss: 0.022283703407089486
New best score: 0.022283703407089486
Epoch 173: train loss: 0.027366497663845153
valid loss: 0.022291729623920033
1 iterations since best score.
Epoch 174: train loss: 0.027348620703988788
valid loss: 0.02226596312760248
New best score: 0.02226596312760248
Epoch 175: train loss: 0.027336257964196344
valid loss: 0.022264154464810518
New best score: 0.022264154464810518
Epoch 176: train loss: 0.027319475778478267
valid loss: 0.02225901745997695
New best score: 0.02225901745997695
Epoch 177: train loss: 0.02730279668732003
valid loss: 0.02226781084309103
1 iterations since best score.
Epoch 178: train loss: 0.027288165774167896
valid loss: 0.022257838008894783
New best score: 0.022257838008894783
Epoch 179: train loss: 0.027274338977035656
valid loss: 0.022235579778251996
New best score: 0.022235579778251996
Epoch 180: train loss: 0.027257639051096277
valid loss: 0.0222349306349668
New best score: 0.0222349306349668
Epoch 181: train loss: 0.0272431151781598
valid loss: 0.0222269894069193
New best score: 0.0222269894069193
Epoch 182: train loss: 0.027227670632536036
valid loss: 0.02222529236466466
New best score: 0.02222529236466466
Epoch 183: train loss: 0.02721316859092257
valid loss: 0.022205822349174835
New best score: 0.022205822349174835
Epoch 184: train loss: 0.027198939605786985
valid loss: 0.02218940971887421
New best score: 0.02218940971887421
Epoch 185: train loss: 0.027183696735351138
valid loss: 0.02218479550713317
New best score: 0.02218479550713317
Epoch 186: train loss: 0.027172062066107647
valid loss: 0.022171826308715295
New best score: 0.022171826308715295
Epoch 187: train loss: 0.02715572778266422
valid loss: 0.022156602788024424
New best score: 0.022156602788024424
Epoch 188: train loss: 0.027142122838188527
valid loss: 0.022152840110977165
New best score: 0.022152840110977165
Epoch 189: train loss: 0.027156833799673426
valid loss: 0.022135975122543387
New best score: 0.022135975122543387
Epoch 190: train loss: 0.027116888003952688
valid loss: 0.022136385554111883
1 iterations since best score.
Epoch 191: train loss: 0.027097924722645283
valid loss: 0.022135188155222297
New best score: 0.022135188155222297
Epoch 192: train loss: 0.027096894630017274
valid loss: 0.022115503400920437
New best score: 0.022115503400920437
Epoch 193: train loss: 0.02707694551438257
valid loss: 0.02211413178821934
New best score: 0.02211413178821934
Epoch 194: train loss: 0.02705197550830953
valid loss: 0.02207818727029355
New best score: 0.02207818727029355
Epoch 195: train loss: 0.027042816159578955
valid loss: 0.02208785341767584
1 iterations since best score.
Epoch 196: train loss: 0.0270271035829242
valid loss: 0.022097130685973444
2 iterations since best score.
Epoch 197: train loss: 0.027014468928325357
valid loss: 0.02206936632054018
New best score: 0.02206936632054018
Epoch 198: train loss: 0.02700017227338944
valid loss: 0.02208895876067258
1 iterations since best score.
Epoch 199: train loss: 0.026988290910284974
valid loss: 0.022064897909129414
New best score: 0.022064897909129414
Epoch 200: train loss: 0.02697321216452931
valid loss: 0.022047681451006666
New best score: 0.022047681451006666
Epoch 201: train loss: 0.02698522687659921
valid loss: 0.022056757257182577
1 iterations since best score.
Epoch 202: train loss: 0.026946473529475098
valid loss: 0.022030715746143476
New best score: 0.022030715746143476
Epoch 203: train loss: 0.026932300859973207
valid loss: 0.022023860876870856
New best score: 0.022023860876870856
Epoch 204: train loss: 0.02693771722661527
valid loss: 0.022042856685043685
1 iterations since best score.
Epoch 205: train loss: 0.026908298703061904
valid loss: 0.022018495143793237
New best score: 0.022018495143793237
Epoch 206: train loss: 0.026924745706809295
valid loss: 0.022006724925986567
New best score: 0.022006724925986567
Epoch 207: train loss: 0.026879847991720097
valid loss: 0.022002845101027946
New best score: 0.022002845101027946
Epoch 208: train loss: 0.026870596271772188
valid loss: 0.021977116728120083
New best score: 0.021977116728120083
Epoch 209: train loss: 0.026854710156822767
valid loss: 0.02197441138439084
New best score: 0.02197441138439084
Epoch 210: train loss: 0.02684843184023091
valid loss: 0.02198466005012434
1 iterations since best score.
Epoch 211: train loss: 0.02682978686445658
valid loss: 0.021955960517484552
New best score: 0.021955960517484552
Epoch 212: train loss: 0.02681700668246957
valid loss: 0.02195046661609957
New best score: 0.02195046661609957
Epoch 213: train loss: 0.02680318067153029
valid loss: 0.02195493712044153
1 iterations since best score.
Epoch 214: train loss: 0.026792003410551376
valid loss: 0.02193685938156327
New best score: 0.02193685938156327
Epoch 215: train loss: 0.026778891367880524
valid loss: 0.021936603644710097
New best score: 0.021936603644710097
Epoch 216: train loss: 0.026765594678266724
valid loss: 0.02192195610555469
New best score: 0.02192195610555469
Epoch 217: train loss: 0.026753041088353153
valid loss: 0.0219172972147582
New best score: 0.0219172972147582
Epoch 218: train loss: 0.026740441359909
valid loss: 0.021891815369551787
New best score: 0.021891815369551787
Epoch 219: train loss: 0.02675781211188957
valid loss: 0.021882710980678923
New best score: 0.021882710980678923
Epoch 220: train loss: 0.02671727145791417
valid loss: 0.02188420647175097
1 iterations since best score.
Epoch 221: train loss: 0.026706334428299026
valid loss: 0.021876843120200468
New best score: 0.021876843120200468
Epoch 222: train loss: 0.02669213155113574
valid loss: 0.02187243546410133
New best score: 0.02187243546410133
Epoch 223: train loss: 0.026701319294075265
valid loss: 0.021869710195158185
New best score: 0.021869710195158185
Epoch 224: train loss: 0.026678147293265772
valid loss: 0.0218592405571129
New best score: 0.0218592405571129
Epoch 225: train loss: 0.026663049977819434
valid loss: 0.02185935075471147
1 iterations since best score.
Epoch 226: train loss: 0.026644339121434744
valid loss: 0.021852905498664886
New best score: 0.021852905498664886
Epoch 227: train loss: 0.026632149542421886
valid loss: 0.02184709989964514
New best score: 0.02184709989964514
Epoch 228: train loss: 0.02662308178784194
valid loss: 0.021839073700117853
New best score: 0.021839073700117853
Epoch 229: train loss: 0.0266067186489801
valid loss: 0.021813320899840262
New best score: 0.021813320899840262
Epoch 230: train loss: 0.026596664046614038
valid loss: 0.021812049154182032
New best score: 0.021812049154182032
Epoch 231: train loss: 0.026586715475234057
valid loss: 0.021813731203924436
1 iterations since best score.
Epoch 232: train loss: 0.026573514466994862
valid loss: 0.021802416847906802
New best score: 0.021802416847906802
Epoch 233: train loss: 0.026591666917143885
valid loss: 0.021827242320881842
1 iterations since best score.
Epoch 234: train loss: 0.026551182184370154
valid loss: 0.021798279944328907
New best score: 0.021798279944328907
Epoch 235: train loss: 0.02653926370147238
valid loss: 0.021774038161492086
New best score: 0.021774038161492086
Epoch 236: train loss: 0.026527666771271573
valid loss: 0.02177286891042779
New best score: 0.02177286891042779
Epoch 237: train loss: 0.026515682890564274
valid loss: 0.021766722955756254
New best score: 0.021766722955756254
Epoch 238: train loss: 0.02650503105578328
valid loss: 0.021760672808986137
New best score: 0.021760672808986137
Epoch 239: train loss: 0.02649356088161212
valid loss: 0.021760542575229223
New best score: 0.021760542575229223
Epoch 240: train loss: 0.02648173972860114
valid loss: 0.021756782706653894
New best score: 0.021756782706653894
Epoch 241: train loss: 0.026470260627845563
valid loss: 0.021743538932457486
New best score: 0.021743538932457486
Epoch 242: train loss: 0.02646023950367689
valid loss: 0.02173636605291337
New best score: 0.02173636605291337
Epoch 243: train loss: 0.026447690709718426
valid loss: 0.021723229918740893
New best score: 0.021723229918740893
Epoch 244: train loss: 0.026436533651583567
valid loss: 0.02171516716556593
New best score: 0.02171516716556593
Epoch 245: train loss: 0.026427496995030764
valid loss: 0.0217038648508367
New best score: 0.0217038648508367
Epoch 246: train loss: 0.026415772832677223
valid loss: 0.021700024869944393
New best score: 0.021700024869944393
Epoch 247: train loss: 0.026404477558615146
valid loss: 0.021701464606347223
1 iterations since best score.
Epoch 248: train loss: 0.0263892589270513
valid loss: 0.021680465038061713
New best score: 0.021680465038061713
Epoch 249: train loss: 0.02640936977428564
valid loss: 0.021685087677254213
1 iterations since best score.
Epoch 250: train loss: 0.026396438337187595
valid loss: 0.021688318406257148
2 iterations since best score.
Epoch 251: train loss: 0.026359157091190053
valid loss: 0.0216866343788538
3 iterations since best score.
Early stopping
Após 251 épocas, o modelo para de aprender porque o desempenho de validação não melhorou por três iterações. Aqui o modelo ótimo (da época 248) não é salvo, mas isso poderia ser implementado simplesmente adicionando torch.save(model.state_dict(), checkpoint_path) na classe EarlyStopping sempre que um novo melhor desempenho for alcançado. Isso permite recarregar o melhor checkpoint salvo ao final do treinamento.
Agora que um processo de otimização limpo está definido, pode-se considerar várias soluções para acelerar e melhorar a convergência em direção a um extremo razoável. A maneira mais natural de fazer isso é ajustar os hiperparâmetros do otimizador, como a taxa de aprendizado e o tamanho do lote. Com uma taxa de aprendizado grande, o gradiente descendente é rápido no início, mas então o otimizador tem dificuldade em encontrar o mínimo. Técnicas de taxa de aprendizado adaptativa como Adam/RMSProp levam em conta a inclinação normalizando a taxa de aprendizado em relação à norma do gradiente. Abaixo estão as fórmulas para atualizar um parâmetro do modelo com Adam.
Onde:
A diferença com o SGD é que aqui a taxa de aprendizado é normalizada usando a “norma do gradiente” (). Para ser mais preciso, a abordagem não usa o gradiente “bruto” e a norma do gradiente , mas um momentum em vez disso (combinação convexa entre valores anteriores e o valor atual), respectivamente e . Também aplica um decaimento ao longo das iterações.
Vamos tentar Adam com uma taxa de aprendizado inicial de 0.0005 para ver a diferença com o SGD regular.
seed_everything(SEED)
model = SimpleFraudMLP(len(input_features), 1000).to(DEVICE)
optimizer = torch.optim.Adam(model.parameters(), lr = 0.0005)
model,training_execution_time,train_losses_adam,valid_losses_adam = training_loop(model,training_generator,valid_generator,optimizer,criterion,verbose=True)
Epoch 0: train loss: 0.04573855715283828
valid loss: 0.022921395302963915
New best score: 0.022921395302963915
Epoch 1: train loss: 0.026701830054725026
valid loss: 0.02114229145894957
New best score: 0.02114229145894957
Epoch 2: train loss: 0.024963660846240854
valid loss: 0.020324631678856543
New best score: 0.020324631678856543
Epoch 3: train loss: 0.023575769497520587
valid loss: 0.020667109151543857
1 iterations since best score.
Epoch 4: train loss: 0.022709976203506368
valid loss: 0.019151893639657136
New best score: 0.019151893639657136
Epoch 5: train loss: 0.02221683326257877
valid loss: 0.01883163772557755
New best score: 0.01883163772557755
Epoch 6: train loss: 0.021621740234552315
valid loss: 0.020071852290392166
1 iterations since best score.
Epoch 7: train loss: 0.021379320485157675
valid loss: 0.01888933465421668
2 iterations since best score.
Epoch 8: train loss: 0.020929416735303973
valid loss: 0.018099226153906068
New best score: 0.018099226153906068
Epoch 9: train loss: 0.0205484975132037
valid loss: 0.018046115800392268
New best score: 0.018046115800392268
Epoch 10: train loss: 0.020301625159160407
valid loss: 0.01875325692474048
1 iterations since best score.
Epoch 11: train loss: 0.020031702731716863
valid loss: 0.019088358170215466
2 iterations since best score.
Epoch 12: train loss: 0.019720997269925114
valid loss: 0.018150363140039736
3 iterations since best score.
Early stopping
plt.subplot(1, 2, 1)
plt.plot(np.arange(len(train_losses))+1, train_losses)
plt.plot(np.arange(len(valid_losses))+1, valid_losses)
plt.title("SGD")
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train','valid'])
plt.ylim([0.01,0.06])
plt.subplot(1, 2, 2)
plt.plot(np.arange(len(train_losses_adam))+1, train_losses_adam)
plt.plot(np.arange(len(valid_losses_adam))+1, valid_losses_adam)
plt.title("ADAM")
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train','valid'])
plt.ylim([0.01,0.06])
(0.01, 0.06)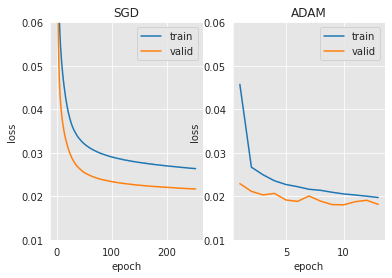
A otimização é muito mais rápida com Adam (10 vezes menos épocas) e alcança um ótimo melhor. Obviamente, aumentar a paciência ou alterar a taxa de aprendizado com SGD provavelmente ajudaria a melhorar tanto a velocidade quanto o ótimo. No entanto, Adam será mantido para o restante do capítulo, pois geralmente permite um desempenho muito bom sem ajuste significativo. Para construir a rede neural final mais tarde, o ajuste será feito principalmente usando o tamanho do lote e a taxa de aprendizado inicial.
Aqui são mencionadas apenas a escolha do otimizador e alguns ajustes de hiperparâmetros para o processo de otimização. Mas tenha em mente que a otimização de redes neurais é uma área de pesquisa/engenharia muito ampla e ativa. Por exemplo, com Redes Profundas, pode-se aplicar normalização em lote (batch normalization) após cada camada para padronizar a distribuição e acelerar a convergência. Também se pode reduzir a taxa de aprendizado quando a perda de validação atinge um plateau (torch.optim.ReduceLROnPlateau). Para um guia completo sobre otimização em aprendizado profundo, recomendamos Ruder (2016)Le et al. (2011).
Regularização¶
Uma forma clássica de melhorar a generalização e alcançar um melhor desempenho de validação é regularizar o modelo. Em linhas gerais, a regularização consiste em limitar a expressividade do modelo para reduzir o sobreajuste.
A técnica mais comum para regularizar um modelo de aprendizado de máquina é restringir seu espaço de parâmetros, por exemplo, sua norma, adicionando um termo ao problema de otimização. Adicionalmente, para minimizar a discrepância entre o ground truth e a previsão, integrar um termo de norma L1 (resp. norma L2) na perda implicará esparsidade de parâmetros (resp. limitará a amplitude dos parâmetros). O espaço de soluções inicial geralmente é cheio de soluções equivalentes (por exemplo, com ativações lineares, dividir todos os pesos de entrada de um neurônio por 2 e multiplicar todos os seus pesos de saída por 2 leva a um modelo equivalente), portanto as restrições impostas pela regularização não apenas limitam o sobreajuste, mas também reduzem a busca e podem ajudar na otimização. Finalmente, selecionar uma solução com norma mínima segue o princípio de “Em condições iguais, a solução mais simples tende a ser a melhor”, um princípio científico frequentemente referido como a navalha de Occam.
Em contraste com a adição de termos de perda, existe uma técnica de regularização especificamente projetada para Redes Neurais chamada dropout. O dropout consiste em descartar aleatoriamente alguns neurônios da rede a cada passo de treinamento. Mais precisamente, define-se um parâmetro de dropout p∈[0,1] e, para cada mini-lote, para cada neurônio, realiza-se um sorteio (Bernoulli) com probabilidade p. Se positivo, os pesos do neurônio são temporariamente zerados (de modo que o neurônio descartado não é considerado durante os forward e backward passes). É equivalente a treinar uma sub-rede aleatória a cada mini-lote (Figura 5), e pode-se provar que isso tem um efeito de regularização L2 em arquiteturas específicas Srivastava et al. (2014).
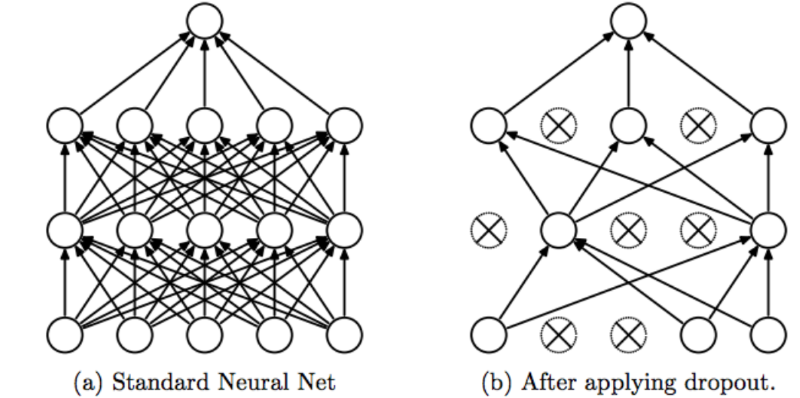 Fonte da imagem: Srivastava et al. (2014)
Fonte da imagem: Srivastava et al. (2014)
Para implementá-lo, vamos definir um novo modelo com uma camada adicional torch.nn.Dropout.
class SimpleFraudMLPWithDropout(torch.nn.Module):
def __init__(self, input_size, hidden_size,p):
super(SimpleFraudMLPWithDropout, self).__init__()
# parameters
self.input_size = input_size
self.hidden_size = hidden_size
self.p = p
#input to hidden
self.fc1 = torch.nn.Linear(self.input_size, self.hidden_size)
self.relu = torch.nn.ReLU()
#hidden to output
self.fc2 = torch.nn.Linear(self.hidden_size, 1)
self.sigmoid = torch.nn.Sigmoid()
self.dropout = torch.nn.Dropout(self.p)
def forward(self, x):
hidden = self.fc1(x)
hidden = self.relu(hidden)
hidden = self.dropout(hidden)
output = self.fc2(hidden)
output = self.sigmoid(output)
return outputNote que definir o modelo no modo de treinamento/avaliação com os métodos model.eval() e model.train() adquire todo seu significado aqui. Em particular, a camada de dropout no forward pass é aplicada apenas quando o modelo está no modo de treinamento.
seed_everything(SEED)
model = SimpleFraudMLPWithDropout(len(input_features), 1000,0.2).to(DEVICE)
optimizer = torch.optim.Adam(model.parameters(), lr = 0.0005)
model,training_execution_time,train_losses_dropout,valid_losses_dropout = training_loop(model,training_generator,valid_generator,optimizer,criterion,verbose=False)plt.plot(np.arange(len(train_losses_adam))+1, train_losses_adam)
plt.plot(np.arange(len(valid_losses_adam))+1, valid_losses_adam)
plt.plot(np.arange(len(train_losses_dropout))+1, train_losses_dropout)
plt.plot(np.arange(len(valid_losses_dropout))+1, valid_losses_dropout)
plt.title("Dropout effect")
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train w/o dropout','valid w/o dropout','train w/ dropout','valid w/ dropout'])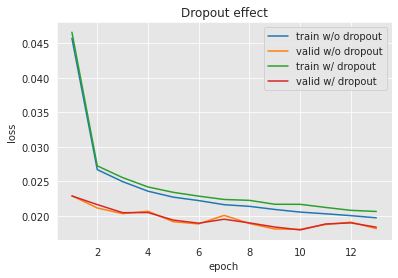
Geralmente é relatado que um pequeno valor de dropout pode levar a melhores resultados de generalização do que sem dropout, mas às vezes pode ser o oposto se os dados de treinamento forem muito ricos, se a distribuição de treinamento for próxima à distribuição de validação/teste e se o modelo já não for muito expressivo. Portanto, a melhor prática é considerar o dropout como um hiperparâmetro (que pode ser definido como 0) e ajustá-lo com uma busca de hiperparâmetros.
Além do efeito de regularização L2, o dropout pode ser visto como um mecanismo muito poderoso que imita estratégias de ensemble como bagging (o modelo pode ser visto como um ensemble de submodelos treinados em diferentes subconjuntos de dados) Goodfellow et al. (2016).
Escalonamento das entradas¶
XGBoost e florestas aleatórias aprendem divisões em características individuais e, portanto, são robustos à escala e distribuição dos valores. Ao contrário, em uma rede neural, cada neurônio da primeira camada aprende uma combinação linear de todas as características. Portanto, é mais fácil treinar os neurônios quando todas as características têm o mesmo intervalo e estão normalmente distribuídas. A primeira propriedade pode ser facilmente implementada aplicando escalonamento min-max ou padrão nas características. Quanto à segunda propriedade, depende da distribuição original das características. Algumas delas não são normalmente distribuídas e têm escalas não lineares (por exemplo, o valor da transação): aumentar o valor em 5 reais não deve ter o mesmo efeito se o ponto de partida é 5 reais ou se é 100 reais. Acontece que aplicar a função log a essas características pode tornar sua distribuição ligeiramente mais normal, o que facilita o aprendizado das redes neurais feed-forward.
Para instância, veja como os valores originais se parecem:
(train_df, valid_df)=get_train_test_set(transactions_df,start_date_training_with_valid,
delta_train=delta_train,delta_delay=delta_delay,delta_test=delta_test)Por exemplo, veja como os valores originais se parecem:
_ = plt.hist(train_df['TX_AMOUNT'].values,bins=20)
E agora vamos aplicar a função log. Para obter um log positivo para a característica que está em [0,+∞[, uma ideia é adicionar 1 e então aplicar a função log (que é equivalente a aplicar a função log1p no numpy). Isso leva a uma característica pré-processada que pertence a [0,+∞[ e então pode ser padronizada. Veja como os valores estão distribuídos após todas essas etapas:
_ = plt.hist(sklearn.preprocessing.StandardScaler().fit_transform(np.log1p(train_df['TX_AMOUNT'].values).reshape(-1, 1)),bins=20)
Note que aqui, nossos dados artificiais foram gerados com Gaussianas, portanto o np.log1p não é muito útil na prática. Mas tenha em mente que em dados do mundo real, a escala original de características como o valor da transação está longe de ser normalmente distribuída e essa operação acaba sendo bastante útil com frequência.
Vamos esquecer o log por agora e apenas analisar o impacto do escalonamento das características no treinamento de nossa Rede Neural. Mais precisamente, vamos ver a diferença entre nenhum escalonamento e o escalonamento padrão. Uma taxa de aprendizado menor de 0.0001 será escolhida aqui para o experimento sem escalonamento para evitar divergência.
#we did not call the function scaleData this time
seed_everything(SEED)
training_generator,valid_generator = prepare_generators(train_df,valid_df,batch_size=64)
model = SimpleFraudMLPWithDropout(len(input_features), 1000,0.2).to(DEVICE)
optimizer = torch.optim.Adam(model.parameters(), lr = 0.0001)
model,training_execution_time,train_losses_without_scaling,valid_losses_without_scaling = training_loop(model,training_generator,valid_generator,optimizer,criterion,verbose=False)plt.plot(np.arange(len(train_losses_without_scaling))+1, train_losses_without_scaling)
plt.plot(np.arange(len(valid_losses_without_scaling))+1, valid_losses_without_scaling)
plt.plot(np.arange(len(train_losses_dropout))+1, train_losses_dropout)
plt.plot(np.arange(len(valid_losses_dropout))+1, valid_losses_dropout)
plt.title('Scaling effect')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train w/o scaling','valid w/o scaling','train w/ scaling','valid w/ scaling'])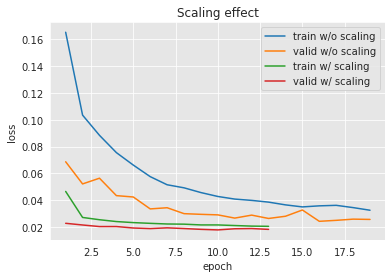
As perdas de treinamento/validação são mais suaves e atingem níveis muito melhores mais rapidamente quando os dados são normalizados com escalonamento padrão.
# Let us rescale data for the next parts
(train_df, valid_df)=scaleData(train_df, valid_df,input_features)Embeddings¶
Lidar adequadamente com variáveis categóricas é talvez uma das principais vantagens das redes neurais. Nos primeiros capítulos, técnicas de transformação de características foram aplicadas a características categóricas como dia, ID do cliente e ID do terminal, a fim de torná-las binárias ou extrair características numéricas delas.
Em dados do mundo real, características categóricas são frequentes (País, Tipo de Comerciante, hora, tipo de pagamento, ...). Mas a maioria dos algoritmos de aprendizado de máquina requer que as características sejam numéricas. Tome o exemplo da regressão linear: é basicamente uma soma ponderada dos valores das características. Para características numéricas, faz sentido considerar que seu impacto é proporcional ao seu valor (por exemplo, quanto menor o atraso entre duas transações, maior o risco de fraude), mas não faz sentido para uma característica nominal como País que pode assumir os valores “EUA”, “França”, “Bélgica”. Para este último, uma transformação é necessária. As escolhas mais comuns são:
Codificação one-hot: uma característica binária é definida para cada modalidade (ex.: “pais_EUA”, “pais_Franca” e “pais_Belgica”).
Codificação baseada em frequência: a frequência (ou outra estatística) de cada modalidade é calculada e o índice da modalidade é substituído pelo valor da estatística.
Codificação por correlação com o rótulo: é próxima à codificação por frequência, mas aqui uma estatística correlacionada com o rótulo é calculada. Por exemplo, cada modalidade pode ser substituída pela sua proporção de fraudes nos dados de treinamento.
Com redes neurais, pode-se usar camadas de embedding para codificar variáveis categóricas. Mais precisamente, a ideia é deixar a própria rede neural aprender uma representação de cada modalidade da variável categórica em um espaço vetorial contínuo de dimensão k, escolhida pelo profissional. Essas representações podem ser aprendidas de ponta a ponta para tornar a rede feed-forward ótima para a tarefa de detecção de fraude. Elas também podem ser aprendidas com um objetivo diferente, como prever as sequências de países visitados pelos titulares dos cartões (pré-treinamento não supervisionado) e depois usadas para detecção de fraude, seja com um classificador de rede neural ou qualquer outro classificador (XGBoost, floresta aleatória, etc.).
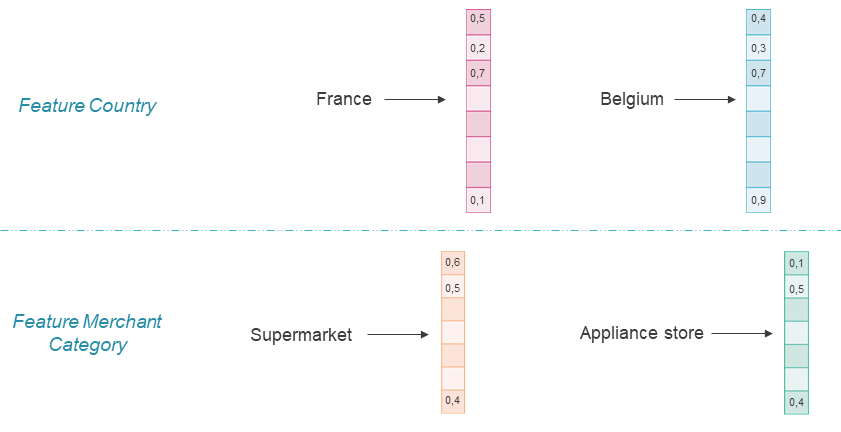
Note que aprender um embedding de dimensão para uma característica categórica é computacionalmente equivalente a aprender uma camada totalmente conectada clássica que toma como entrada a codificação one-hot da característica e produz neurônios.
Para testar camadas de embedding, vamos tentar adicionar entradas categóricas extras em e deixar o modelo aprender embeddings para elas. Nossa última rede neural foi treinada nas seguintes características:
input_features['TX_AMOUNT',
'TX_DURING_WEEKEND',
'TX_DURING_NIGHT',
'CUSTOMER_ID_NB_TX_1DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_1DAY_WINDOW',
'CUSTOMER_ID_NB_TX_7DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_7DAY_WINDOW',
'CUSTOMER_ID_NB_TX_30DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_30DAY_WINDOW',
'TERMINAL_ID_NB_TX_1DAY_WINDOW',
'TERMINAL_ID_RISK_1DAY_WINDOW',
'TERMINAL_ID_NB_TX_7DAY_WINDOW',
'TERMINAL_ID_RISK_7DAY_WINDOW',
'TERMINAL_ID_NB_TX_30DAY_WINDOW',
'TERMINAL_ID_RISK_30DAY_WINDOW']Vamos adicionar, por exemplo, o ID do terminal bruto e o dia da semana como características categóricas de entrada:
def weekday(tx_datetime):
# Transform date into weekday (0 is Monday, 6 is Sunday)
weekday = tx_datetime.weekday()
return int(weekday)train_df['TX_WEEKDAY'] = train_df.TX_DATETIME.apply(weekday)
valid_df['TX_WEEKDAY'] = valid_df.TX_DATETIME.apply(weekday)
input_categorical_features = ['TX_WEEKDAY','TERMINAL_ID']
Vamos agora definir um novo modelo de rede neural com duas camadas de embedding. TX_WEEKDAY e TERMINAL_ID passarão cada um por uma delas, e cada uma será transformada em um vetor. Em seguida, serão concatenados com as características numéricas e o conjunto todo passará por uma rede similar à nossa arquitetura anterior.
class FraudMLPWithEmbedding(torch.nn.Module):
def __init__(self, categorical_inputs_modalities,numerical_inputs_size,embedding_sizes, hidden_size,p):
super(FraudMLPWithEmbedding, self).__init__()
# parameters
self.categorical_inputs_modalities = categorical_inputs_modalities
self.numerical_inputs_size = numerical_inputs_size
self.embedding_sizes = embedding_sizes
self.hidden_size = hidden_size
self.p = p
assert len(categorical_inputs_modalities)==len(embedding_sizes), 'categorical_inputs_modalities and embedding_sizes must have the same length'
#embedding layers
self.emb = []
for i in range(len(categorical_inputs_modalities)):
self.emb.append(torch.nn.Embedding(int(categorical_inputs_modalities[i]), int(embedding_sizes[i])).to(DEVICE))
#contenated inputs to hidden
self.fc1 = torch.nn.Linear(self.numerical_inputs_size+int(np.sum(embedding_sizes)), self.hidden_size)
self.relu = torch.nn.ReLU()
#hidden to output
self.fc2 = torch.nn.Linear(self.hidden_size, 1)
self.sigmoid = torch.nn.Sigmoid()
self.dropout = torch.nn.Dropout(self.p)
def forward(self, x):
#we assume that x start with numerical features then categorical features
inputs = [x[:,:self.numerical_inputs_size]]
for i in range(len(self.categorical_inputs_modalities)):
inputs.append(self.emb[i](x[:,self.numerical_inputs_size+i].to(torch.int64)))
x = torch.cat(inputs,axis=1)
hidden = self.fc1(x)
hidden = self.relu(hidden)
hidden = self.dropout(hidden)
output = self.fc2(hidden)
output = self.sigmoid(output)
return outputdef prepare_generators_with_categorical_features(train_df,valid_df,input_categorical_features,batch_size=64):
x_train = torch.FloatTensor(train_df[input_features].values)
x_valid = torch.FloatTensor(valid_df[input_features].values)
y_train = torch.FloatTensor(train_df[output_feature].values)
y_valid = torch.FloatTensor(valid_df[output_feature].values)
#categorical variables : encoding valid according to train
encoder = sklearn.preprocessing.OrdinalEncoder(handle_unknown='use_encoded_value',unknown_value=-1)
x_train_cat = encoder.fit_transform(train_df[input_categorical_features].values) + 1
categorical_inputs_modalities = np.max(x_train_cat,axis=0)+1
x_train_cat = torch.IntTensor(x_train_cat)
x_valid_cat = torch.IntTensor(encoder.transform(valid_df[input_categorical_features].values) + 1)
x_train = torch.cat([x_train,x_train_cat],axis=1)
x_valid = torch.cat([x_valid,x_valid_cat],axis=1)
train_loader_params = {'batch_size': batch_size,
'shuffle': True,
'num_workers': 0}
valid_loader_params = {'batch_size': batch_size,
'num_workers': 0}
# Generators
training_set = FraudDataset(x_train, y_train)
valid_set = FraudDataset(x_valid, y_valid)
training_generator = torch.utils.data.DataLoader(training_set, **train_loader_params)
valid_generator = torch.utils.data.DataLoader(valid_set, **valid_loader_params)
return training_generator,valid_generator, categorical_inputs_modalitiesAgora vamos treinar este novo modelo com uma dimensão de embedding de 10 para cada característica categórica.
seed_everything(SEED)
training_generator,valid_generator,categorical_inputs_modalities = prepare_generators_with_categorical_features(train_df,valid_df,input_categorical_features,batch_size=64)
embedding_sizes = [10]*len(categorical_inputs_modalities)
model = FraudMLPWithEmbedding(categorical_inputs_modalities,len(input_features),embedding_sizes, 1000,0.2).to(DEVICE)
optimizer = torch.optim.Adam(model.parameters(), lr = 0.0001)
model,training_execution_time,train_losses_embedding,valid_losses_embedding = training_loop(model,training_generator,valid_generator,optimizer,criterion,verbose=False)plt.plot(np.arange(len(train_losses_embedding))+1, train_losses_embedding)
plt.plot(np.arange(len(valid_losses_embedding))+1, valid_losses_embedding)
plt.plot(np.arange(len(train_losses_dropout))+1, train_losses_dropout)
plt.plot(np.arange(len(valid_losses_dropout))+1, valid_losses_dropout)
plt.title('Use of categorical features')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend(['train w/ cat','valid w/ cat','train w/o cat','valid w/o cat'])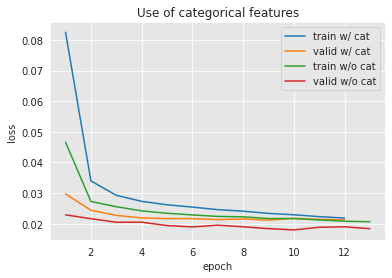
O desempenho aqui não é necessariamente melhor com as características categóricas (elas não agregam valor em comparação com as características engenhadas, pelo menos para os padrões de fraude em nossos dados categóricos). Esta implementação é mostrada para fins educacionais. Tenha em mente que camadas de embedding são frequentemente uma solução valiosa na prática ao treinar com muitos dados, pois é um passo em direção à automação (em vez de engenharia de características por especialistas, pode-se deixar a escolha de representação para o modelo).
O embedding também pode ser interessante para a interpretabilidade. De fato, ao final do treinamento, pode-se extrair model.emb[i].weight. Cada linha desta matriz representa o vetor de embedding de uma determinada modalidade para a i-ésima característica categórica. Isso pode ser usado para calcular similaridades entre modalidades. Também se pode reduzir a dimensionalidade desses vetores com TSNE ou PCA e visualizar todas as modalidades em um plano 2D.
Ensemble¶
Para ir além e melhorar os resultados, o ensemble é uma estratégia comum com redes neurais em geral e para detecção de fraude.
A ideia é simplesmente treinar a arquitetura várias vezes e calcular a média das previsões de todos os modelos obtidos na inferência Zhou (2021). A inicialização das camadas e a ordem aleatória dos lotes geralmente são suficientes para garantir diversidade entre cada submodelo e tornar o ensemble melhor do que cada um individualmente. Para ir além, também se pode treinar cada modelo individual em uma divisão treino/validação diferente Breiman (1996).
O ensemble também é muito útil para detecção de fraude, em particular por causa da deriva de conceito (concept drift). De fato, na detecção de fraude, as técnicas dos fraudadores são variadas e mudam com o tempo. Um único modelo pode ter dificuldade em aprender e lembrar todos os diferentes padrões para a classe alvo. Nesse contexto, espera-se que um ensemble de modelos, construído de forma eficiente, possa lidar com o problema. A intuição é que os diferentes componentes do ensemble podem ser especializados para tarefas diferentes. Por exemplo, um componente pode ser especializado para os padrões recentes e outro para os padrões antigos Lebichot et al. (2021). Da mesma forma, um componente pode ser especializado para as estratégias de fraude mais fáceis e genéricas e outro para conceitos avançados.
Busca em grade prequencial¶
As seções acima mostraram muitas escolhas de design para a rede neural. Vamos agora seguir a metodologia prequencial do Capítulo 5 e realizar uma busca em grade para ver o impacto de alguns hiperparâmetros no desempenho e ser capaz de comparar os resultados com outras linhas de base dos capítulos anteriores.
Vamos considerar os seguintes intervalos:
Tamanho do lote: [64, 128, 256]
Taxa de aprendizado inicial: [0.0001, 0.0002, 0.001]
Taxa de dropout: [0, 0.2, 0.4]
Dimensão da camada oculta: [500]
Número de camadas ocultas: [1, 2]
Para usar o mesmo procedimento que nos capítulos anteriores (com GridSearchCV), temos que tornar a rede neural compatível com as funções do sklearn. Recorreremos à biblioteca skorch, que fornece um wrapper sklearn para módulos PyTorch. Além disso, a parada antecipada não será usada, mas em vez disso o número de épocas ([10, 20, 40]) será outro parâmetro a buscar.
!pip install skorchOutput
Requirement already satisfied: skorch in /opt/conda/lib/python3.8/site-packages (0.10.0)
Requirement already satisfied: numpy>=1.13.3 in /opt/conda/lib/python3.8/site-packages (from skorch) (1.19.2)
Requirement already satisfied: scipy>=1.1.0 in /opt/conda/lib/python3.8/site-packages (from skorch) (1.6.3)
Requirement already satisfied: tqdm>=4.14.0 in /opt/conda/lib/python3.8/site-packages (from skorch) (4.51.0)
Requirement already satisfied: scikit-learn>=0.19.1 in /opt/conda/lib/python3.8/site-packages (from skorch) (0.24.2)
Requirement already satisfied: tabulate>=0.7.7 in /opt/conda/lib/python3.8/site-packages (from skorch) (0.8.9)
Requirement already satisfied: threadpoolctl>=2.0.0 in /opt/conda/lib/python3.8/site-packages (from scikit-learn>=0.19.1->skorch) (2.1.0)
Requirement already satisfied: joblib>=0.11 in /opt/conda/lib/python3.8/site-packages (from scikit-learn>=0.19.1->skorch) (1.0.1)
from skorch import NeuralNetClassifierPara que isso funcione, vários aspectos de nossas classes Python anteriores precisam ser adaptados. Primeiro, os classificadores do sklearn têm duas probabilidades de saída (uma para cada classe) que são complementares. Portanto, a saída de fc2 precisa ser alterada para 2, e a ativação para softmax (similar à ativação sigmoid, mas com uma normalização global). Segundo, o dataset deve esperar arrays em vez de tensores, portanto a conversão será feita dentro do dataset.
class FraudMLP(torch.nn.Module):
def __init__(self, hidden_size=100,num_layers=1,p=0, input_size=len(input_features)):
super(FraudMLP, self).__init__()
# parameters
self.input_size = input_size
self.hidden_size = hidden_size
self.p = p
#input to hidden
self.fc1 = torch.nn.Linear(self.input_size, self.hidden_size)
self.relu = torch.nn.ReLU()
self.fc_hidden=[]
for i in range(num_layers-1):
self.fc_hidden.append(torch.nn.Linear(self.hidden_size, self.hidden_size))
self.fc_hidden.append(torch.nn.ReLU())
#hidden to output
self.fc2 = torch.nn.Linear(self.hidden_size, 2)
self.softmax = torch.nn.Softmax()
self.dropout = torch.nn.Dropout(self.p)
def forward(self, x):
hidden = self.fc1(x)
hidden = self.relu(hidden)
hidden = self.dropout(hidden)
for layer in self.fc_hidden:
hidden=layer(hidden)
hidden = self.dropout(hidden)
output = self.fc2(hidden)
output = self.softmax(output)
return outputclass FraudDatasetForPipe(torch.utils.data.Dataset):
def __init__(self, x, y):
'Initialization'
self.x = torch.FloatTensor(x)
self.y = None
if y is not None:
self.y = torch.LongTensor(y.values)
def __len__(self):
'Returns the total number of samples'
return len(self.x)
def __getitem__(self, index):
'Generates one sample of data'
# Select sample index
if self.y is not None:
return self.x[index], self.y[index]
else:
return self.x[index], -1 Agora que o módulo e o Dataset estão adaptados, pode-se obter um modelo “similar ao sklearn” usando o wrapper NeuralNetClassifier do skorch. Note que podemos definir o dispositivo diretamente como parâmetro nessa classe.
net = NeuralNetClassifier(
FraudMLP,
max_epochs=2,
lr=0.001,
optimizer=torch.optim.Adam,
batch_size=64,
dataset=FraudDatasetForPipe,
iterator_train__shuffle=True
)
net.set_params(train_split=False, verbose=0)<class 'skorch.classifier.NeuralNetClassifier'>[uninitialized](
module=<class '__main__.FraudMLP'>,
)Para testá-lo, vamos realizar uma primeira busca em grade pequena variando o número de épocas e o número de camadas.
# Testing the wrapper
#X=train_df[input_features].values
#y=train_df[output_feature]
#
#net.fit(X, y)
#net.predict_proba(X)# Only keep columns that are needed as argument to custom scoring function
# to reduce serialization time of transaction dataset
transactions_df_scorer=transactions_df[['CUSTOMER_ID', 'TX_FRAUD','TX_TIME_DAYS']]
# Make scorer using card_precision_top_k_custom
card_precision_top_100 = sklearn.metrics.make_scorer(card_precision_top_k_custom,
needs_proba=True,
top_k=100,
transactions_df=transactions_df_scorer)
n_folds=4
start_date_training_for_valid = start_date_training+datetime.timedelta(days=-(delta_delay+delta_valid))
start_date_training_for_test = start_date_training+datetime.timedelta(days=(n_folds-1)*delta_test)
delta_assessment = delta_validseed_everything(SEED)
start_time=time.time()
parameters = {
'clf__lr': [0.001 ],
'clf__batch_size': [64],
'clf__max_epochs': [10, 20],
'clf__module__hidden_size': [100],
'clf__module__num_layers': [1,2],
'clf__module__p': [0],
}
scoring = {'roc_auc':'roc_auc',
'average_precision': 'average_precision',
'card_precision@100': card_precision_top_100,
}
performance_metrics_list_grid=['roc_auc', 'average_precision', 'card_precision@100']
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100']
performances_df_validation=prequential_grid_search(
transactions_df, net,
input_features, output_feature,
parameters, scoring,
start_date_training=start_date_training_with_valid,
n_folds=n_folds,
expe_type='Validation',
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_valid,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list)
print("Validation: Total execution time: "+str(round(time.time()-start_time,2))+"s")Validation: Total execution time: 37.16s
performances_df_validationA validação parece estar funcionando bem e os resultados já parecem promissores.
Vamos agora realizar uma seleção de modelos adequada usando o protocolo do Capítulo 5.3, Seleção de modelos.
seed_everything(SEED)
parameters = {
'clf__lr': [0.001 , 0.0001, 0.0002],
'clf__batch_size': [64,128,256],
'clf__max_epochs': [10,20,40],
'clf__module__hidden_size': [500],
'clf__module__num_layers': [1,2],
'clf__module__p': [0,0.2,0.4],
'clf__module__input_size': [int(len(input_features))],
}
start_time=time.time()
performances_df=model_selection_wrapper(transactions_df, net,
input_features, output_feature,
parameters, scoring,
start_date_training_for_valid,
start_date_training_for_test,
n_folds=n_folds,
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list,
n_jobs=10)
execution_time_nn = time.time()-start_time
parameters_dict=dict(performances_df['Parameters'])
performances_df['Parameters summary']=[str(parameters_dict[i]['clf__lr'])+
'/'+
str(parameters_dict[i]['clf__batch_size'])+
'/'+
str(parameters_dict[i]['clf__max_epochs'])+
'/'+
str(parameters_dict[i]['clf__module__p'])+
'/'+
str(parameters_dict[i]['clf__module__num_layers'])
for i in range(len(parameters_dict))]
performances_df_nn=performances_dfperformances_df_nnexecution_time_nn7350.9550194740295Como o número de parâmetros a ajustar é grande aqui, e o treinamento (com 20-40 épocas) é relativamente lento, a execução da busca em grade pode levar muito tempo (7350 segundos aqui). De fato, requer treinar 162 redes neurais para cada divisão treino/validação da validação prequencial. Para acelerar o processo, seria benéfico adotar a busca aleatória como sugerido no final da Seção 5.3 ou usar um método de ajuste de hiperparâmetros mais adaptado a redes neurais.
summary_performances_nn=get_summary_performances(performances_df_nn, parameter_column_name="Parameters summary")
summary_performances_nnOs conjuntos ótimos de hiperparâmetros dependem fortemente da métrica. A maioria favorece ligeiramente a maior taxa de aprendizado 0.001 e 2 camadas ocultas. Vamos considerar esses valores e visualizar o impacto dos outros (tamanho do lote, número de épocas e dropout).
parameters_dict=dict(performances_df_nn['Parameters'])
performances_df_nn['Parameters summary']=[
str(parameters_dict[i]['clf__batch_size'])+
'/'+
str(parameters_dict[i]['clf__max_epochs'])+
'/'+
str(parameters_dict[i]['clf__module__p'])
for i in range(len(parameters_dict))]performances_df_nn_subset = performances_df_nn[performances_df_nn['Parameters'].apply(lambda x:x['clf__lr']== 0.001 and x['clf__module__hidden_size']==500 and x['clf__module__num_layers']==2 and x['clf__module__p']==0.2 and x['clf__max_epochs']==20).values]
summary_performances_nn_subset=get_summary_performances(performances_df_nn_subset, parameter_column_name="Parameters summary")
indexes_summary = summary_performances_nn_subset.index.values
indexes_summary[0] = 'Best estimated parameters'
summary_performances_nn_subset.rename(index = dict(zip(np.arange(len(indexes_summary)),indexes_summary)))
get_performances_plots(performances_df_nn_subset,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="batch size",
summary_performances=summary_performances_nn_subset)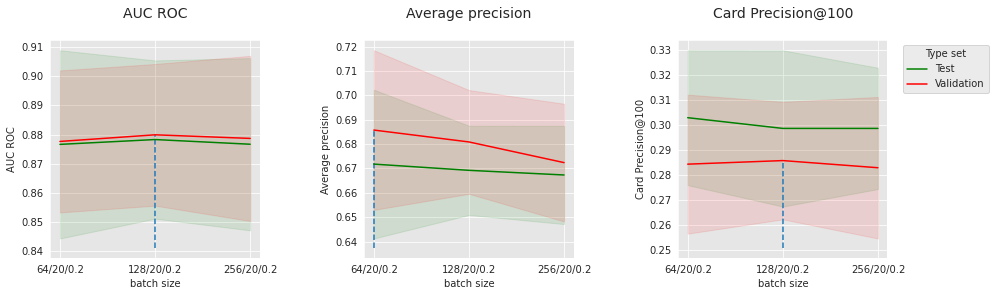
Primeiro, se fixarmos o número de épocas em 20, o nível de dropout em 0.2, o menor tamanho de lote leva a melhores resultados para precisão média e precisão de cartão no conjunto de teste, enquanto há um ponto ótimo de acordo com a AUC-ROC. Na verdade, o tamanho de lote ótimo está fortemente conectado a outros parâmetros do otimizador. Frequentemente, um tamanho de lote maior requer um número maior de épocas. Para verificar isso, vamos visualizar os mesmos gráficos com o número de épocas em 40.
performances_df_nn_subset = performances_df_nn[performances_df_nn['Parameters'].apply(lambda x:x['clf__lr']== 0.001 and x['clf__module__hidden_size']==500 and x['clf__module__num_layers']==2 and x['clf__module__p']==0.2 and x['clf__max_epochs']==40).values]
summary_performances_nn_subset=get_summary_performances(performances_df_nn_subset, parameter_column_name="Parameters summary")
indexes_summary = summary_performances_nn_subset.index.values
indexes_summary[0] = 'Best estimated parameters'
summary_performances_nn_subset.rename(index = dict(zip(np.arange(len(indexes_summary)),indexes_summary)))
get_performances_plots(performances_df_nn_subset,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="batch size",
summary_performances=summary_performances_nn_subset)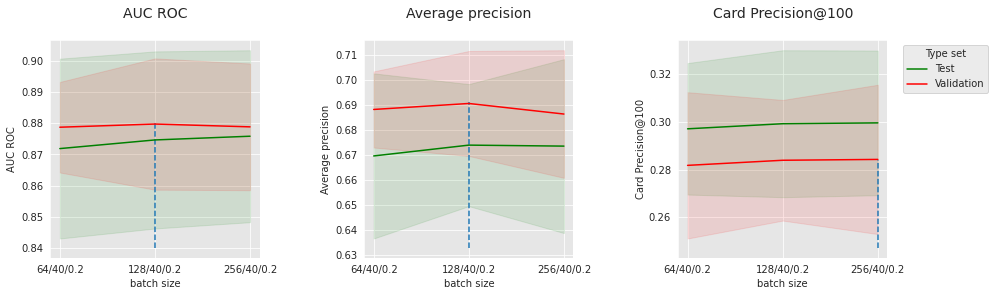
Com esse número maior de épocas, o tamanho de lote ótimo é agora globalmente maior. Vamos agora fazer o contrário, ou seja, fixar o tamanho do lote em algum valor (ex.: 64) e visualizar o impacto do número de épocas.
performances_df_nn_subset = performances_df_nn[performances_df_nn['Parameters'].apply(lambda x:x['clf__lr']== 0.001 and x['clf__module__hidden_size']==500 and x['clf__module__num_layers']==2 and x['clf__module__p']==0.2 and x['clf__batch_size']==64).values]
summary_performances_nn_subset=get_summary_performances(performances_df_nn_subset, parameter_column_name="Parameters summary")
indexes_summary = summary_performances_nn_subset.index.values
indexes_summary[0] = 'Best estimated parameters'
summary_performances_nn_subset.rename(index = dict(zip(np.arange(len(indexes_summary)),indexes_summary)))
get_performances_plots(performances_df_nn_subset,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="Epochs",
summary_performances=summary_performances_nn_subset)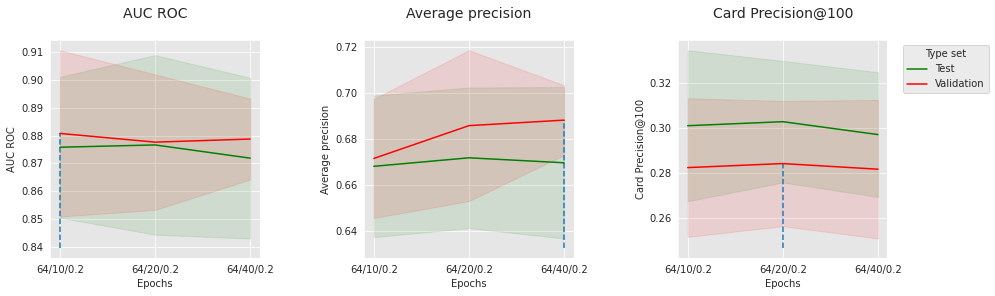
O número ótimo de épocas também depende da métrica e tem um ponto ótimo fortemente conectado à escolha de outros hiperparâmetros.
performances_df_nn_subset = performances_df_nn[performances_df_nn['Parameters'].apply(lambda x:x['clf__lr']== 0.001 and x['clf__module__hidden_size']==500 and x['clf__module__num_layers']==2 and x['clf__max_epochs']==20 and x['clf__batch_size']==64).values]
summary_performances_nn_subset=get_summary_performances(performances_df_nn_subset, parameter_column_name="Parameters summary")
indexes_summary = summary_performances_nn_subset.index.values
indexes_summary[0] = 'Best estimated parameters'
summary_performances_nn_subset.rename(index = dict(zip(np.arange(len(indexes_summary)),indexes_summary)))
get_performances_plots(performances_df_nn_subset,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="Dropout",
summary_performances=summary_performances_nn_subset)
parameters_dict=dict(performances_df_nn['Parameters'])
performances_df_nn['Parameters summary']=[str(parameters_dict[i]['clf__lr'])+
'/'+
str(parameters_dict[i]['clf__batch_size'])+
'/'+
str(parameters_dict[i]['clf__max_epochs'])+
'/'+
str(parameters_dict[i]['clf__module__p'])+
'/'+
str(parameters_dict[i]['clf__module__num_layers'])
for i in range(len(parameters_dict))]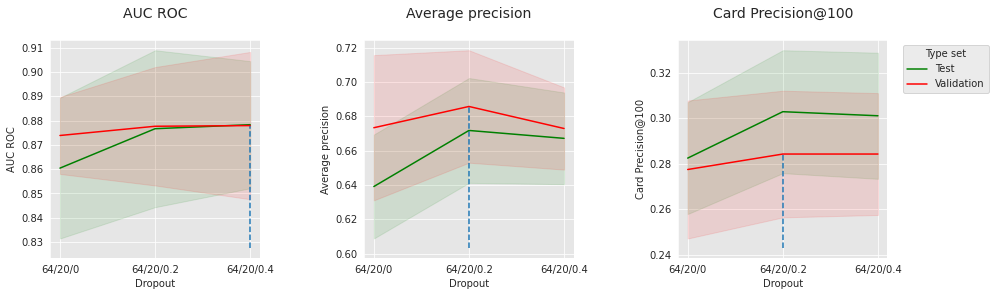
Quanto ao dropout, ele ajuda a generalizar e melhorar as métricas de validação/teste. No entanto, quando o valor de dropout é muito alto (0,4), ele pode deteriorar os resultados, por exemplo, limitando o poder de ajuste ou exigindo um número maior de épocas.
Salvamento dos resultados¶
Vamos salvar os resultados de desempenho e os tempos de execução dos modelos de rede neural no formato pickle do Python.
performances_df_dictionary={
"Neural Network": performances_df_nn
}
execution_times=[execution_time_nn]
filehandler = open('performances_model_selection_nn.pkl', 'wb')
pickle.dump((performances_df_dictionary, execution_times), filehandler)
filehandler.close()Resumo do benchmark¶
Vamos finalmente recuperar os resultados de desempenho obtidos no Capítulo 5 com árvore de decisão, regressão logística, floresta aleatória e XGBoost, e compará-los com os obtidos com uma rede neural feed-forward. Os resultados podem ser recuperados carregando os arquivos pickle performances_model_selection.pkl e performances_model_selection_nn.pkl, e resumidos com a função get_summary_performances.
Notebook Cell
# Load performance results for decision tree, logistic regression, random forest and XGBoost
filehandler = open('../Chapter_5_ModelValidationAndSelection/performances_model_selection.pkl', 'rb')
(performances_df_dictionary, execution_times) = pickle.load(filehandler)
# Load performance results for feed-forward neural network
filehandler = open('performances_model_selection_nn.pkl', 'rb')
(performances_df_dictionary_nn, execution_times_nn) = pickle.load(filehandler)
Notebook Cell
performances_df_dt=performances_df_dictionary['Decision Tree']
summary_performances_dt=get_summary_performances(performances_df_dt, parameter_column_name="Parameters summary")
performances_df_lr=performances_df_dictionary['Logistic Regression']
summary_performances_lr=get_summary_performances(performances_df_lr, parameter_column_name="Parameters summary")
performances_df_rf=performances_df_dictionary['Random Forest']
summary_performances_rf=get_summary_performances(performances_df_rf, parameter_column_name="Parameters summary")
performances_df_xgboost=performances_df_dictionary['XGBoost']
summary_performances_xgboost=get_summary_performances(performances_df_xgboost, parameter_column_name="Parameters summary")
performances_df_nn=performances_df_dictionary_nn['Neural Network']
summary_performances_nn=get_summary_performances(performances_df_nn, parameter_column_name="Parameters summary")
summary_test_performances = pd.concat([summary_performances_dt.iloc[2,:],
summary_performances_lr.iloc[2,:],
summary_performances_rf.iloc[2,:],
summary_performances_xgboost.iloc[2,:],
summary_performances_nn.iloc[2,:],
],axis=1)
summary_test_performances.columns=['Decision Tree', 'Logistic Regression', 'Random Forest', 'XGBoost', 'Neural Network']
Os resultados são resumidos em uma tabela summary_test_performances. As linhas fornecem os resultados médios de desempenho nos conjuntos de teste em termos de AUC ROC, Precisão Média e CP@100.
summary_test_performancesNo geral, parece que nossa rede neural feed-forward simples é uma boa concorrente em termos de desempenho preditivo para o problema de detecção de fraude, fornecendo os melhores desempenhos em termos de AUC ROC e CP@100, e desempenhos competitivos em termos de Precisão Média. Além disso, ela se beneficia de muitas vantagens (por exemplo, sua capacidade de aprendizado incremental), como mencionado na seção anterior.
Conclusão¶
Esta seção forneceu uma visão geral de como projetar uma rede neural feed-forward para detecção de fraude. Em comparação com os modelos clássicos de aprendizado de máquina, as redes neurais têm um conjunto infinito de hiperparâmetros. Essa modularidade no design tem muitas vantagens em termos de expressividade, mas tem o custo de uma otimização de hiperparâmetros da arquitetura, das ativações, da perda, dos otimizadores, do pré-processamento, etc. que consome muito tempo. No entanto, há muitas maneiras de automatizar a otimização de hiperparâmetros e o design de arquitetura, por exemplo, com AutoML, incluindo Busca de Arquitetura Neural (ou NAS) Elsken et al. (2019).
Aqui, apenas a ponta do iceberg é coberta. Há muitos outros aspectos a considerar mesmo com uma rede neural tão simples. Muitos deles podem ser encontrados em guias de boas práticas e geralmente também se aplicam à detecção de fraude. Alguns são até específicos para problemas como este. Um importante é gerenciar o desequilíbrio (consulte o Capítulo 6 para mais detalhes): isso pode ser feito com redes neurais substituindo a entropia cruzada binária por uma BCE ponderada (colocando mais importância nos termos de perda associados a amostras de fraude) ou com focal loss, uma variante da entropia cruzada especificamente projetada para focar automaticamente em amostras sub-representadas. Outra forma é implementar um Dataloader personalizado com um balanced sampler.
O restante do capítulo foca em diferentes tipos de modelos de redes neurais como autoencoders ou modelos sequenciais e a forma como podem ser usados no contexto de detecção de fraude.
- Ghosh, S., & Reilly, D. L. (1994). Credit card fraud detection with a neural-network. System Sciences, 1994. Proceedings of the Twenty-Seventh Hawaii International Conference On, 3, 621–630.
- Aleskerov, E., Freisleben, B., & Rao, B. (1997). Cardwatch: A neural network based database mining system for credit card fraud detection. Proceedings of the IEEE/IAFE 1997 Computational Intelligence for Financial Engineering (CIFEr), 220–226.
- Hecht-Nielsen, R. (1992). Theory of the backpropagation neural network. In Neural networks for perception (pp. 65–93). Elsevier.
- Paszke, A., Gross, S., Chintala, S., Chanan, G., Yang, E., DeVito, Z., Lin, Z., Desmaison, A., Antiga, L., & Lerer, A. (2017). Automatic differentiation in PyTorch. NIPS-W.
- Ruder, S. (2016). An overview of gradient descent optimization algorithms. arXiv Preprint arXiv:1609.04747.
- Nair, V., & Hinton, G. E. (2010). Rectified linear units improve restricted boltzmann machines. Proceedings of the 27th International Conference on International Conference on Machine Learning, 807–814.
- Cybenko, G. (1989). Approximation by superpositions of a sigmoidal function. Mathematics of Control, Signals and Systems, 2(4), 303–314.
- Le, Q. V., Ngiam, J., Coates, A., Lahiri, A., Prochnow, B., & Ng, A. Y. (2011). On optimization methods for deep learning. ICML.
- Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: a simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research, 15(1), 1929–1958.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep learning. MIT press.
- Zhou, Z.-H. (2021). Ensemble learning. In Machine Learning (pp. 181–210). Springer.
- Breiman, L. (1996). Bagging predictors. Machine Learning, 24(2), 123–140.
- Lebichot, B., Paldino, G. M., Siblini, W., He-Guelton, L., Oblé, F., & Bontempi, G. (2021). Incremental learning strategies for credit cards fraud detection. International Journal of Data Science and Analytics, 1–10.
- Elsken, T., Metzen, J. H., & Hutter, F. (2019). Neural architecture search: A survey. The Journal of Machine Learning Research, 20(1), 1997–2017.