O aprendizado sensível ao custo é uma subárea do aprendizado de máquina que aborda problemas de classificação onde os custos de classificação incorreta não são iguais Fernández et al. (2018)Elkan (2001)Ling & Sheng (2008). Problemas sensíveis ao custo ocorrem em muitas disciplinas, como medicina (por exemplo, detecção de doenças), engenharia (por exemplo, detecção de falhas em máquinas), transporte (por exemplo, detecção de congestionamentos), finanças (por exemplo, detecção de fraudes) e assim por diante. Eles frequentemente estão relacionados ao problema de desequilíbrio de classes, pois na maioria desses problemas, o objetivo é detectar eventos raros. Os conjuntos de dados de treinamento, portanto, tipicamente contêm menos exemplos do evento de interesse.
Já abordamos a detecção de fraude como um problema sensível ao custo no Capítulo 4, Matriz de Custos. A seção apontou a matriz de custos como a forma padrão de quantificar os custos de classificação incorreta. Denotando por a matriz de custos, suas entradas quantificam o custo de prever a classe quando a classe verdadeira é Elkan (2001). Para um problema de classificação binária, a matriz de custos é uma matriz , conforme ilustrado na Fig. 1.
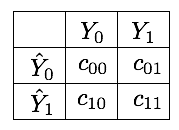
Classificações corretas têm custo zero, ou seja, . Os custos de classificação incorreta são, no entanto, difíceis de estimar na prática. Como discutido no Capítulo 4, Matriz de Custos, perder uma transação fraudulenta (falso negativo) envolve uma perda diretamente relacionada ao valor da transação, mas também a usos fraudulentos posteriores do cartão e à reputação da empresa. Ao mesmo tempo, o bloqueio de transações legítimas (falso positivo) causa inconveniência aos clientes, gera custos de investigação desnecessários e também impacta a reputação da empresa.
Em problemas desequilibrados sensíveis ao custo, a abordagem heurística mais popular para estimar os custos consiste em utilizar a razão de desequilíbrio (RD). Denotemos por o conjunto de dados desequilibrado, com e sendo os subconjuntos de amostras pertencentes à classe majoritária e minoritária, respectivamente. A RD do conjunto de dados é definida como Lemaître et al. (2017):
onde denota a cardinalidade de um conjunto. Neste cenário, e , onde a classe minoritária é a classe , e a classe majoritária é a classe . Vale observar que usar a RD como custo para a classe majoritária equilibra o custo total das duas classes, ou seja, . A matriz de custos resultante para um problema de 2 classes é dada na Fig. 2.
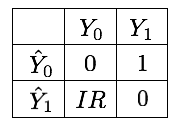
Usar a RD para definir os custos de classificação incorreta é geralmente uma boa heurística. No entanto, tem algumas limitações, particularmente relacionadas ao tamanho pequeno da amostra, sobreposição de classes e instâncias ruidosas ou limítrofes Fernández et al. (2018). Uma prática complementar comum consiste em considerar os custos de classificação incorreta como um hiperparâmetro a ser identificado por meio da seleção de modelos.
O sklearn do Python oferece suporte para aprendizado sensível ao custo para a maioria dos classificadores de linha de base graças ao parâmetro class_weight. O parâmetro permite especificar custos de três maneiras diferentes:
None: Os custos de classificação incorreta são definidos como 1 (padrão)balanced: Os custos são definidos de acordo com a razão de desequilíbrio (como na Fig. 2){0:c10, 1:c01}: Os custos de classificação incorreta são explicitamente definidos para as duas classes por meio de um dicionário.
O uso de pesos de classe geralmente implica uma modificação na função de perda do algoritmo de aprendizado. A modificação depende do tipo de algoritmo. Ao penalizar fortemente erros na classe minoritária, o aprendizado sensível ao custo melhora sua importância durante a etapa de treinamento do classificador. Isso empurra a fronteira de decisão para longe dessas instâncias, permitindo melhorar a generalização na classe minoritária Fernández et al. (2018)Gupta et al. (2020).
Esta seção apresenta como o aprendizado sensível ao custo pode ser usado com a biblioteca Python sklearn. Para melhor visualização, primeiro utilizamos um conjunto de dados desequilibrado simples com duas variáveis para ilustrar como diferentes custos de classificação incorreta alteram as fronteiras de decisão. Em seguida, aplicamos a abordagem ao maior conjunto de dados simulado de dados de transações.
Notebook Cell
# Initialization: Load shared functions and simulated data
# Load shared functions
!curl -O https://raw.githubusercontent.com/Fraud-Detection-Handbook/fraud-detection-handbook/main/Chapter_References/shared_functions.py
%run shared_functions.py
#%run ../Chapter_References/shared_functions.ipynb
# Get simulated data from Github repository
if not os.path.exists("simulated-data-transformed"):
!git clone https://github.com/Fraud-Detection-Handbook/simulated-data-transformed
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 63060 100 63060 0 0 221k 0 --:--:-- --:--:-- --:--:-- 220k
Exemplo ilustrativo¶
Para fins ilustrativos, vamos primeiro considerar uma tarefa de classificação simples. Usamos a função make_classification da biblioteca sklearn para gerar um conjunto de dados desequilibrado de duas classes com 5000 exemplos. O conjunto de dados contém 95% de exemplos da classe 0 e 5% de exemplos da classe 1.
X, y = sklearn.datasets.make_classification(n_samples=5000, n_features=2, n_informative=2,
n_redundant=0, n_repeated=0, n_classes=2,
n_clusters_per_class=1,
weights=[0.95, 0.05],
class_sep=0.5, random_state=0)
dataset_df = pd.DataFrame({'X1':X[:,0],'X2':X[:,1], 'Y':y})
A distribuição das duas classes se sobrepõe ligeiramente, como ilustrado abaixo.
Notebook Cell
%%capture
fig_distribution, ax = plt.subplots(1, 1, figsize=(5,5))
groups = dataset_df.groupby('Y')
for name, group in groups:
ax.scatter(group.X1, group.X2, edgecolors='k', label=name,alpha=1,marker='o')
ax.legend(loc='upper left',
bbox_to_anchor=(1.05, 1),
title="Class")fig_distribution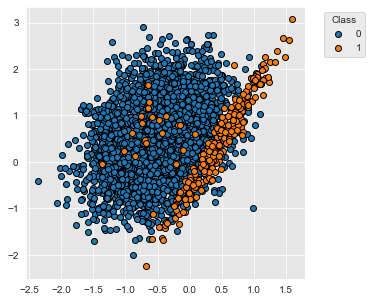
Árvore de decisão¶
Vamos agora treinar uma árvore de decisão para separar as duas classes. Usamos uma árvore de decisão de profundidade 5 e uma validação cruzada estratificada de 5 folds para avaliar os desempenhos do classificador. Os desempenhos são avaliados em termos de AUC ROC, Precisão Média e acurácia balanceada. Os pesos de classe são definidos como 1 para ambas as classes.
classifier = sklearn.tree.DecisionTreeClassifier(max_depth=5,class_weight={0:1,1:1},random_state=0)
cv = sklearn.model_selection.StratifiedKFold(n_splits=5, shuffle=True, random_state=0)cv_results_ = sklearn.model_selection.cross_validate(classifier, X, y, cv=cv,
scoring=['roc_auc',
'average_precision',
'balanced_accuracy'],
return_estimator=True)Os desempenhos de cada fold são retornados no dicionário cv_results_, que é melhor visualizado como um DataFrame.
results = round(pd.DataFrame(cv_results_),3)
resultsVamos calcular a média e o desvio padrão dos desempenhos em todos os folds.
results_mean = list(results.mean().values)
results_std = list(results.std().values)
pd.DataFrame([[str(round(results_mean[i],3))+'+/-'+str(round(results_std[i],3)) for i in range(len(results))]],
columns=['Fit time (s)','Score time (s)','AUC ROC','Average Precision','Balanced accuracy'])Os desempenhos são bastante bons, pois o AUC ROC está bem acima de e a precisão média acima de . A acurácia balanceada, no entanto, não é tão alta, sugerindo que a fronteira de decisão classifica incorretamente muitas amostras da classe minoritária.
Vamos finalmente plotar a fronteira de decisão fornecida por uma das árvores de decisão. Usamos a árvore de decisão obtida do primeiro fold da validação cruzada.
Notebook Cell
def plot_decision_boundary_classifier(ax,
classifier,
train_df,
input_features=['X1','X2'],
output_feature='Y',
title="",
fs=14,
plot_training_data=True):
plot_colors = ["tab:blue","tab:orange"]
x1_min, x1_max = train_df[input_features[0]].min() - 1, train_df[input_features[0]].max() + 1
x2_min, x2_max = train_df[input_features[1]].min() - 1, train_df[input_features[1]].max() + 1
plot_step=0.1
xx, yy = np.meshgrid(np.arange(x1_min, x1_max, plot_step),
np.arange(x2_min, x2_max, plot_step))
Z = classifier.predict_proba(np.c_[xx.ravel(), yy.ravel()])[:,1]
Z = Z.reshape(xx.shape)
ax.contourf(xx, yy, Z, cmap=plt.cm.RdYlBu_r,alpha=0.3)
if plot_training_data:
# Plot the training points
groups = train_df.groupby(output_feature)
for name, group in groups:
ax.scatter(group[input_features[0]], group[input_features[1]], edgecolors='black', label=name)
ax.set_title(title, fontsize=fs)
ax.set_xlabel(input_features[0], fontsize=fs)
ax.set_ylabel(input_features[1], fontsize=fs)
# Retrieve the decision tree from the first fold of the cross-validation
classifier_0 = cv_results_['estimator'][0]# Retrieve the indices used for the training and testing of the first fold of the cross-validation
(train_index, test_index) = next(cv.split(X, y))
# Recreate the train and test DafaFrames from these indices
train_df = pd.DataFrame({'X1':X[train_index,0], 'X2':X[train_index,1], 'Y':y[train_index]})
test_df = pd.DataFrame({'X1':X[test_index,0], 'X2':X[test_index,1], 'Y':y[test_index]})
input_features = ['X1','X2']
output_feature = 'Y'Notebook Cell
%%capture
fig_decision_boundary, ax = plt.subplots(1, 3, figsize=(5*3,5))
plot_decision_boundary_classifier(ax[0], classifier_0,
train_df,
title="Decision surface of the decision tree\n With training data",
plot_training_data=True)
plot_decision_boundary_classifier(ax[1], classifier_0,
train_df,
title="Decision surface of the decision tree\n",
plot_training_data=False)
plot_decision_boundary_classifier(ax[2], classifier_0,
test_df,
title="Decision surface of the decision tree\n With test data",
plot_training_data=True)
ax[-1].legend(loc='upper left',
bbox_to_anchor=(1.05, 1),
title="Class")
sm = plt.cm.ScalarMappable(cmap=plt.cm.RdYlBu_r, norm=plt.Normalize(vmin=0, vmax=1))
cax = fig_decision_boundary.add_axes([0.93, 0.15, 0.02, 0.5])
fig_decision_boundary.colorbar(sm, cax=cax, alpha=0.3, boundaries=np.linspace(0, 1, 11))fig_decision_boundary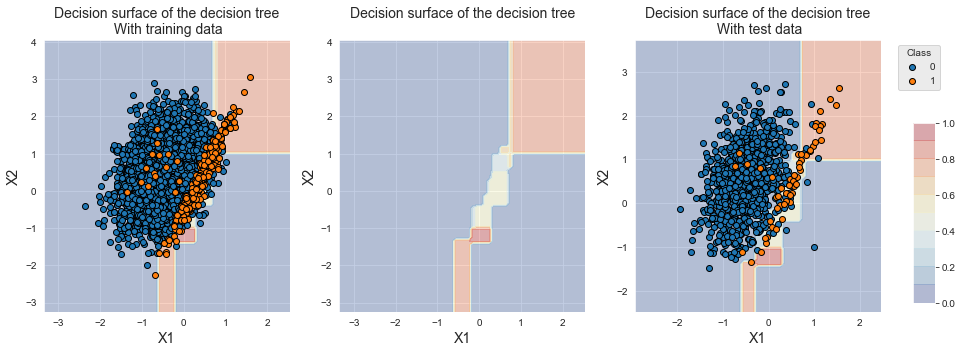
Para melhor visualização, reportamos as fronteiras de decisão isoladas (centro), com os dados de treinamento (esquerda) e com os dados de teste (direita). Os gráficos mostram que a árvore de decisão identifica corretamente a região onde as amostras da classe minoritária estão. A árvore de decisão, no entanto, classifica principalmente amostras da região de sobreposição na classe majoritária (gradiente de cor amarelo/azul).
Reutilizaremos as funções acima para calcular os desempenhos e para plotar as fronteiras de decisão. Para concisão do código, implementamos duas funções para calcular os resultados da validação cruzada (kfold_cv_with_classifier) e para plotar as fronteiras de decisão (plot_decision_boundary).
Notebook Cell
def kfold_cv_with_classifier(classifier,
X,
y,
n_splits=5,
strategy_name="Basline classifier"):
cv = sklearn.model_selection.StratifiedKFold(n_splits=n_splits, shuffle=True, random_state=0)
cv_results_ = sklearn.model_selection.cross_validate(classifier,X,y,cv=cv,
scoring=['roc_auc',
'average_precision',
'balanced_accuracy'],
return_estimator=True)
results = round(pd.DataFrame(cv_results_),3)
results_mean = list(results.mean().values)
results_std = list(results.std().values)
results_df = pd.DataFrame([[str(round(results_mean[i],3))+'+/-'+
str(round(results_std[i],3)) for i in range(len(results))]],
columns=['Fit time (s)','Score time (s)',
'AUC ROC','Average Precision','Balanced accuracy'])
results_df.rename(index={0:strategy_name}, inplace=True)
classifier_0 = cv_results_['estimator'][0]
(train_index, test_index) = next(cv.split(X, y))
train_df = pd.DataFrame({'X1':X[train_index,0], 'X2':X[train_index,1], 'Y':y[train_index]})
test_df = pd.DataFrame({'X1':X[test_index,0], 'X2':X[test_index,1], 'Y':y[test_index]})
return (results_df, classifier_0, train_df, test_df)Notebook Cell
def plot_decision_boundary(classifier_0,
train_df,
test_df):
fig_decision_boundary, ax = plt.subplots(1, 3, figsize=(5*3,5))
plot_decision_boundary_classifier(ax[0], classifier_0,
train_df,
title="Decision surface of the decision tree\n With training data",
plot_training_data=True)
plot_decision_boundary_classifier(ax[1], classifier_0,
train_df,
title="Decision surface of the decision tree\n",
plot_training_data=False)
plot_decision_boundary_classifier(ax[2], classifier_0,
test_df,
title="Decision surface of the decision tree\n With test data",
plot_training_data=True)
ax[-1].legend(loc='upper left',
bbox_to_anchor=(1.05, 1),
title="Class")
sm = plt.cm.ScalarMappable(cmap=plt.cm.RdYlBu_r, norm=plt.Normalize(vmin=0, vmax=1))
cax = fig_decision_boundary.add_axes([0.93, 0.15, 0.02, 0.5])
fig_decision_boundary.colorbar(sm, cax=cax, alpha=0.3, boundaries=np.linspace(0, 1, 11))
return fig_decision_boundaryVamos recalcular os desempenhos e as fronteiras de decisão com essas duas funções.
%%capture
classifier = sklearn.tree.DecisionTreeClassifier(max_depth=5,class_weight={0:1,1:1},random_state=0)
(results_df_dt_baseline, classifier_0, train_df, test_df) = kfold_cv_with_classifier(classifier,
X, y,
n_splits=5,
strategy_name="Decision tree - Baseline")
fig_decision_boundary = plot_decision_boundary(classifier_0, train_df, test_df)
results_df_dt_baselinefig_decision_boundaryVamos agora definir os pesos de classe para que falsos positivos tenham um peso igual à razão de desequilíbrio.
IR=0.05/0.95class_weight={0:IR,1:1}%%capture
classifier = sklearn.tree.DecisionTreeClassifier(max_depth=5,class_weight=class_weight,random_state=0)
(results_df_dt_cost_sensitive, classifier_0, train_df, test_df) = kfold_cv_with_classifier(classifier,
X, y,
n_splits=5,
strategy_name="Decision tree - Cost-sensitive")
fig_decision_boundary = plot_decision_boundary(classifier_0, train_df, test_df)
pd.concat([results_df_dt_baseline,
results_df_dt_cost_sensitive])fig_decision_boundary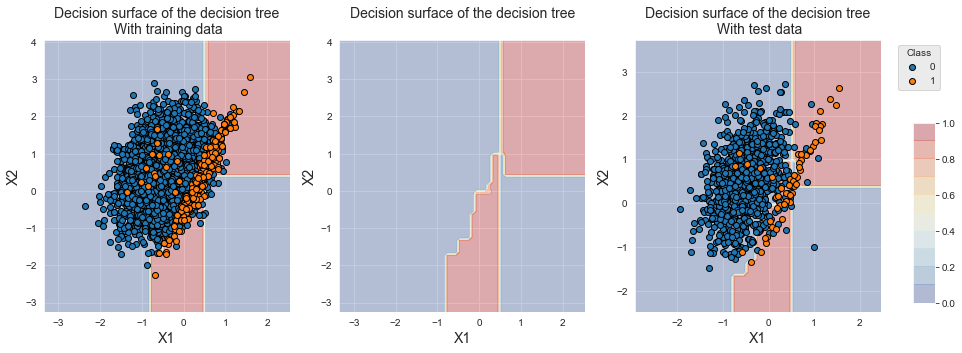
Observamos que a fronteira de decisão foi deslocada em direção às amostras da classe minoritária. Esse deslocamento permitiu aumentar o desempenho em termos de acurácia balanceada, que aumentou de 0,786+/-0,046 para 0,898+/-0,021. Observamos, no entanto, que os desempenhos em termos de AUC ROC e Precisão Média diminuíram.
Regressão logística¶
Vamos agora aplicar a mesma metodologia com um classificador de regressão logística. Primeiro construímos um classificador com pesos iguais para as duas classes e executamos uma validação cruzada estratificada de 5 folds.
%%capture
classifier = sklearn.linear_model.LogisticRegression(C=1,class_weight={0:1,1:1},random_state=0)
(results_df_lr_baseline, classifier_0, train_df, test_df) = kfold_cv_with_classifier(classifier,
X, y,
n_splits=5,
strategy_name="Logistic regression - Baseline")
fig_decision_boundary = plot_decision_boundary(classifier_0, train_df, test_df)
results_df_lr_baselineOs desempenhos em termos de AUC ROC e Precisão Média são maiores do que com uma árvore de decisão, mas menores em termos de acurácia balanceada.
fig_decision_boundary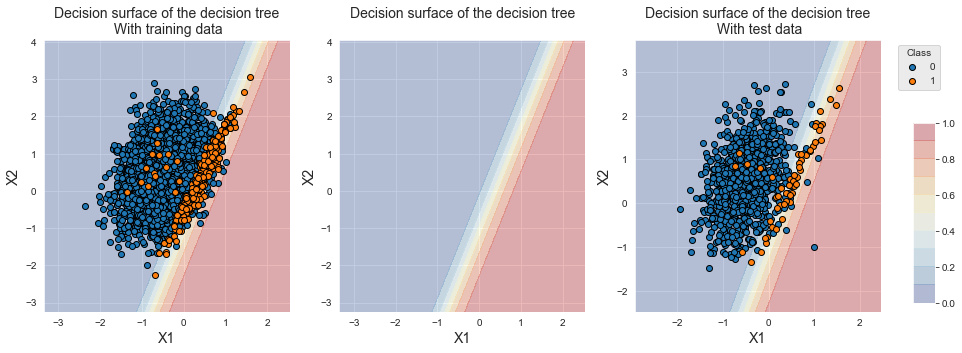
A fronteira de decisão ilustra a separação linear resultante da regressão logística. Devido ao desequilíbrio de classes, observamos que a fronteira de decisão favorece ligeiramente a classe majoritária.
Assim como para a árvore de decisão, vamos alterar os pesos de classe, usando a razão de desequilíbrio como peso para a classe majoritária.
%%capture
classifier = sklearn.linear_model.LogisticRegression(C=1,class_weight={0:IR,1:1},random_state=0)
(results_df_lr_cost_sensitive, classifier_0, train_df, test_df) = kfold_cv_with_classifier(classifier,
X, y,
n_splits=5,
strategy_name="Logistic regression - Cost-sensitive")
fig_decision_boundary = plot_decision_boundary(classifier_0, train_df, test_df)
pd.concat([results_df_lr_baseline, results_df_lr_cost_sensitive])fig_decision_boundary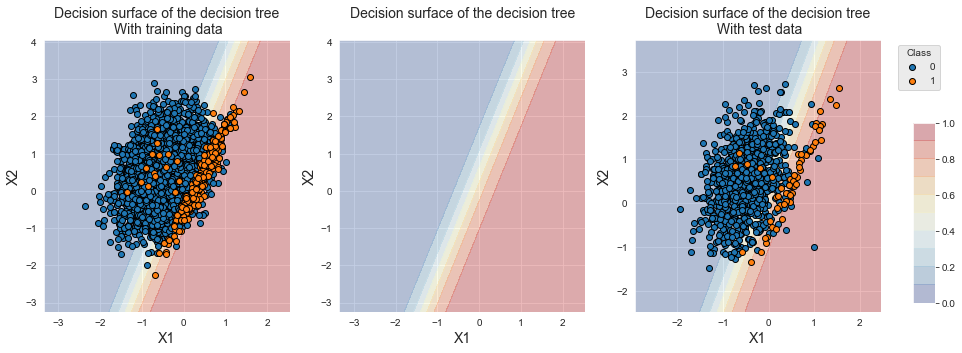
Observamos que a fronteira de decisão se moveu para a esquerda, favorecendo a classificação da classe minoritária. Notamos um forte aumento da acurácia balanceada, de 0,641+/-0,048 para 0,899+/-0,01. O AUC ROC e a Precisão Média permanecem tão bons quanto o classificador com pesos iguais.
Os exemplos acima mostram que ajustar os pesos de classe pode melhorar os desempenhos de classificação. Vale notar, no entanto, que as melhorias de desempenho dependem da métrica de desempenho. Para ambos os classificadores, reduzir o peso de classe da classe majoritária permitiu aumentar a acurácia balanceada. A acurácia em termos de AUC ROC e Precisão Média, no entanto, permaneceu inalterada para regressão logística e diminuiu para árvores de decisão.
results_df = pd.concat([results_df_dt_baseline,
results_df_dt_cost_sensitive,
results_df_lr_baseline,
results_df_lr_cost_sensitive])
results_dfDados de transações¶
Vamos agora explorar se alterar os pesos de classe pode melhorar os desempenhos de classificação no conjunto de dados simulado de dados de transações. Reutilizamos a metodologia do Capítulo 5, Seleção de Modelos, usando a validação prequencial como estratégia de validação.
Carregamento dos dados¶
O carregamento dos dados e a inicialização dos parâmetros seguem o mesmo modelo do Capítulo 5, Seleção de Modelos.
Notebook Cell
# Load data from the 2018-07-11 to the 2018-09-14
DIR_INPUT = 'simulated-data-transformed/data/'
BEGIN_DATE = "2018-06-11"
END_DATE = "2018-09-14"
print("Load files")
%time transactions_df = read_from_files(DIR_INPUT, BEGIN_DATE, END_DATE)
print("{0} transactions loaded, containing {1} fraudulent transactions".format(len(transactions_df),transactions_df.TX_FRAUD.sum()))
# Number of folds for the prequential validation
n_folds = 4
# Set the starting day for the training period, and the deltas
start_date_training = datetime.datetime.strptime("2018-07-25", "%Y-%m-%d")
delta_train = delta_delay = delta_test = delta_valid = delta_assessment = 7
start_date_training_for_valid = start_date_training+datetime.timedelta(days=-(delta_delay+delta_valid))
start_date_training_for_test = start_date_training+datetime.timedelta(days=(n_folds-1)*delta_test)
output_feature = "TX_FRAUD"
input_features = ['TX_AMOUNT','TX_DURING_WEEKEND', 'TX_DURING_NIGHT', 'CUSTOMER_ID_NB_TX_1DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_1DAY_WINDOW', 'CUSTOMER_ID_NB_TX_7DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_7DAY_WINDOW', 'CUSTOMER_ID_NB_TX_30DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_30DAY_WINDOW', 'TERMINAL_ID_NB_TX_1DAY_WINDOW',
'TERMINAL_ID_RISK_1DAY_WINDOW', 'TERMINAL_ID_NB_TX_7DAY_WINDOW',
'TERMINAL_ID_RISK_7DAY_WINDOW', 'TERMINAL_ID_NB_TX_30DAY_WINDOW',
'TERMINAL_ID_RISK_30DAY_WINDOW']
# Only keep columns that are needed as argument to the custom scoring function
# (in order to reduce the serialization time of transaction dataset)
transactions_df_scorer = transactions_df[['CUSTOMER_ID', 'TX_FRAUD','TX_TIME_DAYS']]
card_precision_top_100 = sklearn.metrics.make_scorer(card_precision_top_k_custom,
needs_proba=True,
top_k=100,
transactions_df=transactions_df_scorer)
performance_metrics_list_grid = ['roc_auc', 'average_precision', 'card_precision@100']
performance_metrics_list = ['AUC ROC', 'Average precision', 'Card Precision@100']
scoring = {'roc_auc':'roc_auc',
'average_precision': 'average_precision',
'card_precision@100': card_precision_top_100,
}
Load files
CPU times: user 724 ms, sys: 569 ms, total: 1.29 s
Wall time: 1.41 s
919767 transactions loaded, containing 8195 fraudulent transactions
Árvore de decisão¶
O conjunto de dados de transações contém cerca de 0,7% de transações fraudulentas. A razão de desequilíbrio é portanto de cerca de 1/100. Para avaliar o impacto do parâmetro de peso de classe no desempenho da classificação, variamos o peso de classe na faixa de 0,01 a 1, com o seguinte conjunto de valores possíveis: .
A implementação é a mesma do Capítulo 5. A única modificação consiste em variar o parâmetro de peso de classe (clf__class_weight) em vez da profundidade da árvore de decisão. Usamos uma profundidade de árvore de decisão de 5 (clf__max_depth).
# Define classifier
classifier = sklearn.tree.DecisionTreeClassifier()
# Set of parameters for which to assess model performances
parameters = {'clf__max_depth':[5], 'clf__random_state':[0],
'clf__class_weight':[{0: w} for w in [0.01, 0.05, 0.1, 0.5, 1]]}
start_time = time.time()
# Fit models and assess performances for all parameters
performances_df = model_selection_wrapper(transactions_df, classifier,
input_features, output_feature,
parameters, scoring,
start_date_training_for_valid,
start_date_training_for_test,
n_folds=n_folds,
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list,
n_jobs=1)
execution_time_dt = time.time()-start_time
Vamos usar o peso de classe como parâmetro variável e resumir os desempenhos em função do peso de classe.
# Select parameter of interest (class_weight)
parameters_dict = dict(performances_df['Parameters'])
performances_df['Parameters summary'] = [parameters_dict[i]['clf__class_weight'][0] for i in range(len(parameters_dict))]
# Rename to performances_df_dt for model performance comparison at the end of this notebook
performances_df_dt = performances_df
Notebook Cell
performances_df_dtsummary_performances_dt = get_summary_performances(performances_df_dt, parameter_column_name="Parameters summary")
summary_performances_dtObservamos que o peso de classe ótimo para a classe majoritária depende da métrica de desempenho. Para melhor visualização, vamos plotar os desempenhos em função do peso de classe para as três métricas de desempenho.
get_performances_plots(performances_df_dt,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="Class weight for the majority class",
summary_performances=summary_performances_dt)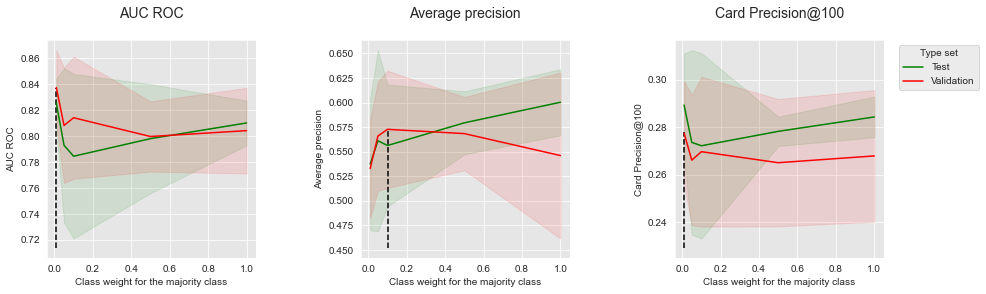
Os resultados são mistos, mostrando tendências conflitantes entre o peso de classe da classe majoritária e os ganhos de desempenho. Para AUC ROC e CP@100, um peso de classe próximo à razão de desequilíbrio (0,01) fornece o maior desempenho tanto para o conjunto de teste quanto para o conjunto de validação, mas o menor desempenho em termos de Precisão Média.
Regressão logística¶
Vamos seguir a mesma metodologia acima, usando regressão logística como algoritmo de classificação.
# Define classifier
classifier = sklearn.linear_model.LogisticRegression()
# Set of parameters for which to assess model performances
parameters = {'clf__C':[1], 'clf__random_state':[0],
'clf__class_weight':[{0: w} for w in [0.01, 0.05, 0.1, 0.5, 1]]}
start_time = time.time()
# Fit models and assess performances for all parameters
performances_df = model_selection_wrapper(transactions_df, classifier,
input_features, output_feature,
parameters, scoring,
start_date_training_for_valid,
start_date_training_for_test,
n_folds=n_folds,
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list,
n_jobs=1)
execution_time_lr = time.time()-start_time
# Select parameter of interest (class_weight)
parameters_dict=dict(performances_df['Parameters'])
performances_df['Parameters summary']=[parameters_dict[i]['clf__class_weight'][0] for i in range(len(parameters_dict))]
# Rename to performances_df_dt for model performance comparison at the end of this notebook
performances_df_lr=performances_df
Notebook Cell
performances_df_lrsummary_performances_lr = get_summary_performances(performances_df_lr, parameter_column_name="Parameters summary")
summary_performances_lrget_performances_plots(performances_df_lr,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="Class weight for the majority class",
summary_performances=summary_performances_lr)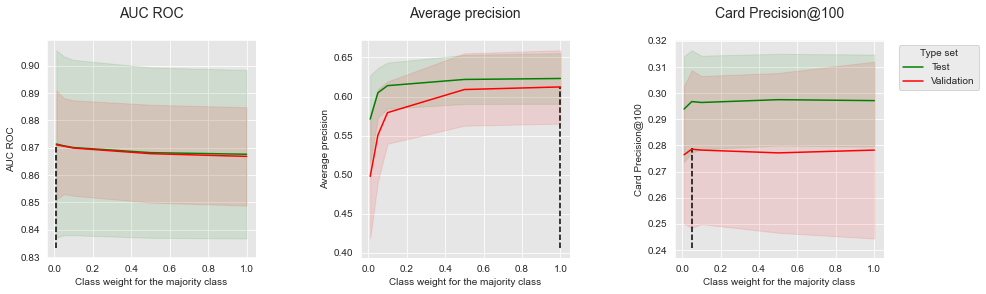
Semelhante às árvores de decisão, os resultados são mistos. Desempenhos ligeiramente maiores são obtidos para AUC ROC com um peso de classe baixo para a classe majoritária. Os desempenhos em termos de Precisão Média e CP@100, no entanto, seguem a tendência oposta.
Resumo¶
Os benefícios de usar custos de classificação incorreta no procedimento de treinamento parecem, portanto, ser fortemente dependentes das características de um conjunto de dados e da métrica de desempenho a otimizar. Os experimentos fornecidos nesta seção mostraram que o aprendizado sensível ao custo efetivamente permite deslocar a fronteira de decisão de um classificador e favorecer a classificação da classe minoritária. Seus benefícios em termos de AUC ROC e Precisão Média parecem, no entanto, conflitantes. Em particular, o deslocamento da fronteira de decisão parece levar a muitos falsos positivos, que impactam negativamente a precisão e, portanto, o desempenho em termos de Precisão Média.
Salvamento dos resultados¶
Vamos finalmente salvar os resultados de desempenho e os tempos de execução.
performances_df_dictionary = {
"Decision Tree": performances_df_dt,
"Logistic Regression": performances_df_lr
}
execution_times = [execution_time_dt,
execution_time_lr
]
Ambas as estruturas de dados são salvas como arquivo Pickle.
filehandler = open('performances_cost_sensitive.pkl', 'wb')
pickle.dump((performances_df_dictionary, execution_times), filehandler)
filehandler.close()- Fernández, A., Garcı́a, S., Galar, M., Prati, R. C., Krawczyk, B., & Herrera, F. (2018). Learning from imbalanced data sets. Springer.
- Elkan, C. (2001). The foundations of cost-sensitive learning. International Joint Conference on Artificial Intelligence, 17(1), 973–978.
- Ling, C. X., & Sheng, V. S. (2008). Cost-sensitive learning and the class imbalance problem. Encyclopedia of Machine Learning, 2011, 231–235.
- Lemaître, G., Nogueira, F., & Aridas, C. K. (2017). Imbalanced-learn: A Python Toolbox to Tackle the Curse of Imbalanced Datasets in Machine Learning. Journal of Machine Learning Research, 18(17), 1–5. http://jmlr.org/papers/v18/16-365.html
- Gupta, A., Tatbul, N., Marcus, R., Zhou, S., Lee, I., & Gottschlich, J. (2020). Class-Weighted Evaluation Metrics for Imbalanced Data Classification. arXiv Preprint arXiv:2010.05995.