As estratégias de reamostragem abordam o desequilíbrio de classes no nível dos dados, reamostrandoo conjunto de dados para reduzir a razão de desequilíbrio. A reamostragem de um conjunto de dados desequilibrado ocorre antes do treinamento do modelo de predição e pode ser vista como uma etapa de pré-processamento de dados. Numerosos métodos foram propostos para reamostrar conjuntos de dados desequilibrados, que podem ser categorizados em três estratégias principais: sobreamostragem, subamostragem e estratégias híbridas Fernández et al. (2018)Lemaître et al. (2017)Chawla (2009).
A sobreamostragem consiste em aumentar artificialmente a proporção de amostras da classe minoritária. A abordagem mais simples é a sobreamostragem aleatória (ROS), na qual as amostras da classe minoritária são duplicadas aleatoriamente Fernández et al. (2018). Abordagens mais sofisticadas consistem em gerar dados sintéticos interpolando amostras da classe minoritária. Dois métodos padrão baseados em interpolação são o SMOTE (Técnica de Sobreamostragem de Minoria Sintética) Chawla et al. (2002) e o ADASYN (Amostragem Sintética Adaptativa) He et al. (2008).
A subamostragem, pelo contrário, consiste em reduzir a razão de desequilíbrio removendo amostras da classe majoritária. As amostras podem ser simplesmente removidas aleatoriamente, como na subamostragem aleatória (RUS) Fernández et al. (2018). A RUS é uma maneira rápida e fácil de equilibrar um conjunto de dados e, portanto, é amplamente utilizada. Uma desvantagem significativa do método é que amostras úteis para o processo de aprendizado podem ser descartadas Ali et al. (2019). Estratégias mais avançadas visam remover amostras de regiões de sobreposição (como NearMiss Mani & Zhang (2003), Tomek Links Tomek & others (1976) ou Vizinhos Mais Próximos Editados (ENN) Wilson (1972)), ou substituindo subconjuntos de amostras por seus centroides Yen & Lee (2009).
A capacidade das técnicas de sobreamostragem ou subamostragem de melhorar os desempenhos de classificação depende em grande medida das características de um conjunto de dados. Como resumido em Haixiang et al. (2017), as técnicas de sobreamostragem tendem a ser particularmente eficazes quando o número de amostras da classe minoritária é muito baixo. As técnicas de subamostragem, por outro lado, são adequadas para grandes conjuntos de dados. Em particular, permitem acelerar os tempos de treinamento ao reduzir o tamanho do conjunto de dados.
As técnicas de sobreamostragem e subamostragem também podem ser combinadas, resultando em técnicas de reamostragem híbridas. A hibridização de subamostragem e sobreamostragem demonstrou melhorar quase sempre os desempenhos de classificação (Capítulo 5, Seção 6 em Fernández et al. (2018)). Combinações populares envolvem SMOTE, juntamente com técnicas de subamostragem baseadas em vizinhos mais próximos, como Tomek Links Tomek & others (1976)Batista et al. (2004) ou Vizinhos Mais Próximos Editados (ENN) Wilson (1972)Batista et al. (2003).
Esta seção explora o uso de algumas técnicas populares de reamostragem e discute seus benefícios e limitações. A implementação proposta baseia-se na biblioteca Python imblearn, que é a biblioteca Python mais completa e atualizada para aprendizado com dados desequilibrados. A biblioteca fornece uma ampla gama de técnicas de reamostragem que podem ser facilmente integradas com a biblioteca sklearn Imblearn (2021).
Notebook Cell
# Initialization: Load shared functions and simulated data
# Load shared functions
!curl -O https://raw.githubusercontent.com/Fraud-Detection-Handbook/fraud-detection-handbook/main/Chapter_References/shared_functions.py
%run shared_functions.py
#%run ../Chapter_References/shared_functions.ipynb
# Get simulated data from Github repository
if not os.path.exists("simulated-data-transformed"):
!git clone https://github.com/Fraud-Detection-Handbook/simulated-data-transformed
Exemplo ilustrativo¶
Para fins ilustrativos, reutilizamos a mesma tarefa de classificação simples da seção de aprendizado sensível ao custo.
Notebook Cell
X, y = sklearn.datasets.make_classification(n_samples=5000, n_features=2, n_informative=2,
n_redundant=0, n_repeated=0, n_classes=2,
n_clusters_per_class=1,
weights=[0.95, 0.05],
class_sep=0.5, random_state=0)
dataset_df = pd.DataFrame({'X1':X[:,0],'X2':X[:,1], 'Y':y})
Notebook Cell
%%capture
fig_distribution, ax = plt.subplots(1, 1, figsize=(5,5))
groups = dataset_df.groupby('Y')
for name, group in groups:
ax.scatter(group.X1, group.X2, edgecolors='k', label=name,alpha=1,marker='o')
ax.legend(loc='upper left',
bbox_to_anchor=(1.05, 1),
title="Class")O conjunto de dados contém 5000 amostras com duas classes, rotuladas 0 e 1. 95% das amostras estão associadas à classe 0 e 5% das amostras à classe 1.
fig_distribution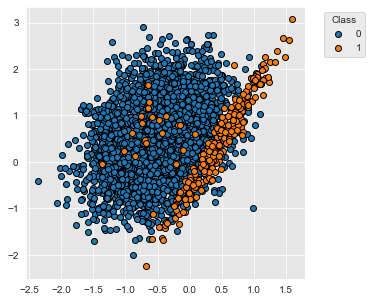
Seguindo a mesma metodologia da seção de aprendizado sensível ao custo, os desempenhos de um classificador de linha de base sem reamostragem são obtidos com a função kfold_cv_with_classifier. Uma árvore de decisão de profundidade cinco e uma validação cruzada estratificada de 5 folds nos fornecem os seguintes desempenhos de classificação de linha de base.
%%capture
classifier = sklearn.tree.DecisionTreeClassifier(max_depth=5, random_state=0)
(results_df_dt_baseline, classifier_0, train_df, test_df) = kfold_cv_with_classifier(classifier,
X, y,
n_splits=5,
strategy_name="Decision tree - Baseline")
fig_decision_boundary = plot_decision_boundary(classifier_0, train_df, test_df)
results_df_dt_baselineA fronteira de decisão do primeiro classificador da validação cruzada é reportada abaixo. Devido ao desequilíbrio de classes, o classificador tende a retornar probabilidades iguais para as duas classes na região de sobreposição.
fig_decision_boundary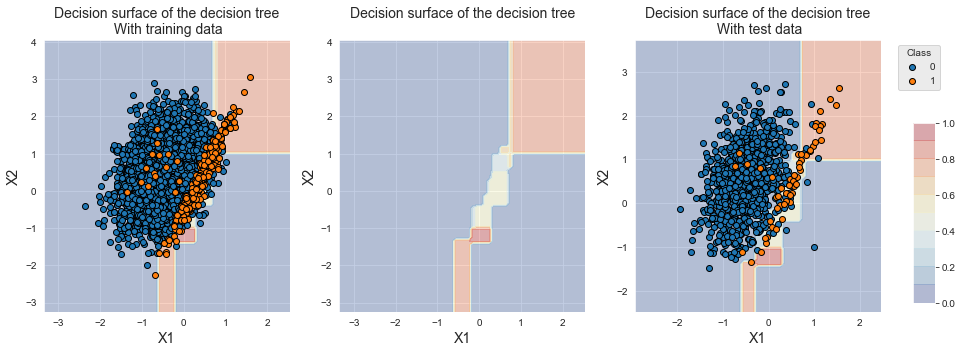
Sobreamostragem¶
As técnicas de sobreamostragem visam reequilibrar o conjunto de dados criando novas amostras para a classe minoritária. Os dois métodos mais utilizados são a sobreamostragem aleatória e o SMOTE Fernández et al. (2018)Haixiang et al. (2017)Chawla et al. (2002). As duas próximas subseções mostram como esses métodos podem ser implementados e ilustram sua capacidade de mover as fronteiras de decisão em direção à classe minoritária.
Sobreamostragem aleatória¶
Vamos primeiro apresentar brevemente como a biblioteca imblearn permite reamostrar conjuntos de dados. Uma introdução mais completa pode ser encontrada no site da biblioteca, em https://
A biblioteca imblearn fornece objetos chamados samplers, que recebem como entrada um conjunto de dados e um conjunto de parâmetros específicos do sampler, e retornam um conjunto de dados reamostrado.
Por exemplo, o sampler imblearn para sobreamostragem aleatória é chamado RandomOverSampler. Seu principal parâmetro é o sampling_strategy, que determina a razão de desequilíbrio desejada após a sobreamostragem aleatória.
Vamos, por exemplo, criar um sampler para sobreamostragem aleatória, onde o conjunto de dados reamostrado deve ter uma razão de desequilíbrio de 1 (ou seja, onde as amostras da classe minoritária são duplicadas até que seu número seja igual ao número de amostras na classe majoritária).
# random_state is set to 0 for reproducibility
ROS = imblearn.over_sampling.RandomOverSampler(sampling_strategy=1, random_state=0)Vamos aplicar este sampler no DataFrame train_df, que é o conjunto de dados de treinamento no primeiro fold da validação cruzada realizada acima. O DataFrame contém 3784 amostras da classe 0 e 216 amostras da classe 1.
train_df['Y'].value_counts()0 3784
1 216
Name: Y, dtype: int64A reamostragem do conjunto de dados é realizada chamando o método fit do objeto sampler. Seja train_df_ROS o DataFrame reamostrado.
X_resampled, Y_resampled = ROS.fit_resample(train_df[['X1','X2']], train_df['Y'])
train_df_ROS = pd.DataFrame({'X1':X_resampled['X1'],'X2':X_resampled['X2'], 'Y':Y_resampled})O DataFrame reamostrado agora contém tantas amostras da classe 1 quanto da classe 0.
train_df_ROS['Y'].value_counts()0 3784
1 3784
Name: Y, dtype: int64Os samplers podem ser combinados com estimadores sklearn usando pipelines. A adição de uma etapa de amostragem no procedimento de validação cruzada é, portanto, simples e consiste em criar um pipeline composto por um sampler e um estimador.
A implementação é fornecida abaixo, na função kfold_cv_with_sampler_and_classifier.
Notebook Cell
def kfold_cv_with_sampler_and_classifier(classifier,
sampler_list,
X,
y,
n_splits=5,
strategy_name="Baseline classifier"):
# Create a pipeline with the list of samplers, and the estimator
estimators = sampler_list.copy()
estimators.extend([('clf', classifier)])
pipe = imblearn.pipeline.Pipeline(estimators)
cv = sklearn.model_selection.StratifiedKFold(n_splits=n_splits, shuffle=True, random_state=0)
cv_results_ = sklearn.model_selection.cross_validate(pipe,X,y,cv=cv,
scoring=['roc_auc',
'average_precision',
'balanced_accuracy'],
return_estimator=True)
results = round(pd.DataFrame(cv_results_),3)
results_mean = list(results.mean().values)
results_std = list(results.std().values)
results_df = pd.DataFrame([[str(round(results_mean[i],3))+'+/-'+
str(round(results_std[i],3)) for i in range(len(results))]],
columns=['Fit time (s)','Score time (s)',
'AUC ROC','Average Precision','Balanced accuracy'])
results_df.rename(index={0:strategy_name}, inplace=True)
classifier_0 = cv_results_['estimator'][0]
(train_index, test_index) = next(cv.split(X, y))
X_resampled, Y_resampled = X[train_index,:], y[train_index]
for i in range(len(sampler_list)):
X_resampled, Y_resampled = sampler_list[i][1].fit_resample(X_resampled, Y_resampled)
test_df = pd.DataFrame({'X1':X[test_index,0],'X2':X[test_index,1], 'Y':y[test_index]})
train_df = pd.DataFrame({'X1':X_resampled[:,0],'X2':X_resampled[:,1], 'Y':Y_resampled})
return (results_df, classifier_0, train_df, test_df)Vamos avaliar os desempenhos do classificador de linha de base combinado com sobreamostragem aleatória.
%%capture
sampler_list = [('sampler',imblearn.over_sampling.RandomOverSampler(sampling_strategy=1, random_state=0))]
classifier = sklearn.tree.DecisionTreeClassifier(max_depth=5, random_state=0)
(results_df_ROS, classifier_0, train_df, test_df) = kfold_cv_with_sampler_and_classifier(classifier,
sampler_list,
X, y,
n_splits=5,
strategy_name="Decision tree - ROS")
fig_decision_boundary = plot_decision_boundary(classifier_0, train_df, test_df)Como verificação de sanidade, podemos verificar que o tamanho do conjunto de treinamento contém o mesmo número de amostras para as duas classes.
train_df['Y'].value_counts()0 3784
1 3784
Name: Y, dtype: int64A reamostragem permitiu deslocar a fronteira de decisão em direção à classe minoritária, como pode ser visto na figura abaixo. Observe que os dados de treinamento para a classe minoritária parecem os mesmos que no classificador de linha de base. A maioria das instâncias, no entanto, foi duplicada muitas vezes para atingir uma razão de desequilíbrio de um.
fig_decision_boundary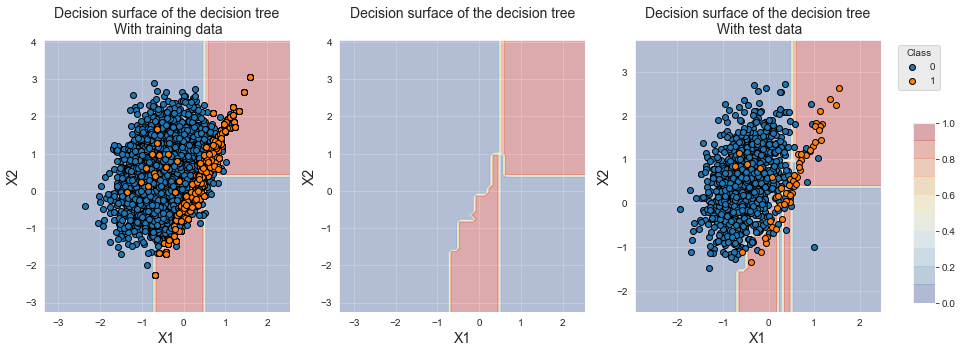
Os desempenhos de classificação mostram um aumento em termos de acurácia balanceada. Observamos, no entanto, uma diminuição em termos de AUC ROC e Precisão Média, devido ao deslocamento da fronteira de decisão que aumentou significativamente o número de falsos positivos.
pd.concat([results_df_dt_baseline,
results_df_ROS])SMOTE¶
O SMOTE Chawla et al. (2002) sobreamostra a classe minoritária gerando exemplos sintéticos na vizinhança dos observados. A ideia é formar novos exemplos da minoria interpolando amostras da mesma classe. Isso tem o efeito de criar agrupamentos em torno de cada observação minoritária. Ao criar observações sintéticas, o classificador constrói regiões de decisão maiores que contêm instâncias próximas da classe minoritária. O SMOTE demonstrou melhorar os desempenhos de um classificador base em muitas aplicações Dal Pozzolo (2015)Chawla et al. (2002).
O sampler imblearn para SMOTE é imblearn.over_sampling.SMOTE. Vamos ilustrar o uso do SMOTE e seu impacto na fronteira de decisão do classificador e nos desempenhos de classificação.
A implementação segue a mesma estrutura da sobreamostragem aleatória. A única diferença é mudar o sampler para SMOTE.
%%capture
sampler_list = [('sampler', imblearn.over_sampling.SMOTE(sampling_strategy=1, random_state=0))]
classifier = sklearn.tree.DecisionTreeClassifier(max_depth=5, random_state=0)
(results_df_SMOTE, classifier_0, train_df, test_df) = kfold_cv_with_sampler_and_classifier(classifier,
sampler_list,
X, y,
n_splits=5,
strategy_name="Decision tree - SMOTE")
fig_decision_boundary = plot_decision_boundary(classifier_0, train_df, test_df)Assim como na sobreamostragem aleatória, o número de amostras na classe minoritária é aumentado para corresponder ao número de amostras na classe majoritária (sampling_strategy=1).
train_df['Y'].value_counts()0 3784
1 3784
Name: Y, dtype: int64A fronteira de decisão também é deslocada em direção à classe minoritária. Observamos que, ao contrário da sobreamostragem aleatória, novos exemplos foram gerados para a classe minoritária.
fig_decision_boundary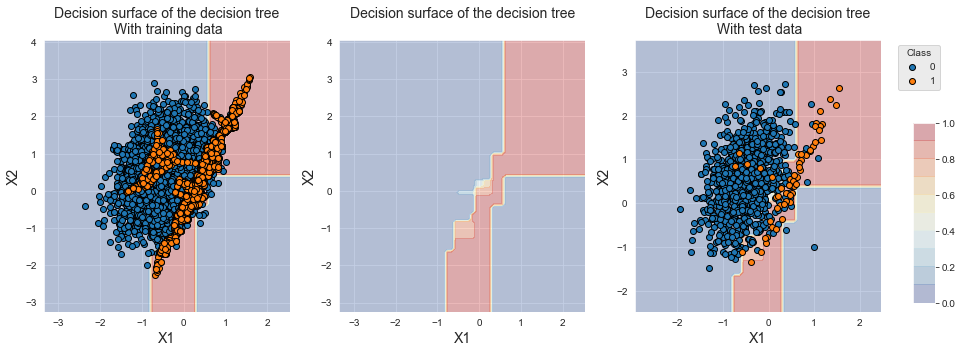
O SMOTE fornece desempenhos maiores do que a sobreamostragem aleatória para as três métricas. A Precisão Média, no entanto, permanece menor do que o classificador de linha de base.
pd.concat([results_df_dt_baseline,
results_df_ROS,
results_df_SMOTE])Outras estratégias de sobreamostragem¶
Existe uma gama de estratégias mais sofisticadas para sobreamostragem, cujos detalhes vão além do escopo deste livro. Remetemos o leitor a Fernández et al. (2018) para uma revisão e à página imblearn sobre métodos de sobreamostragem para suas implementações em Python. Em particular, a biblioteca imblearn fornece os seguintes métodos adicionais de sobreamostragem: SMOTENC Chawla et al. (2002), SMOTEN Chawla et al. (2002), ADASYN He et al. (2008), BorderlineSMOTE Han et al. (2005), KMeansSMOTE Last et al. (2017) e SVMSMOTE Nguyen et al. (2011). Esses métodos podem ser usados simplesmente substituindo o sampler pelo método desejado no código acima.
Subamostragem¶
A subamostragem refere-se ao processo de redução do número de amostras na classe majoritária. A abordagem simples, chamada de subamostragem aleatória (RUS), consiste em remover aleatoriamente amostras da classe majoritária até que a razão de desequilíbrio desejada seja alcançada.
A principal desvantagem da RUS é que o método pode descartar amostras que são importantes para identificar a fronteira de decisão. Uma série de técnicas mais avançadas foi proposta visando remover amostras de forma mais principiada Fernández et al. (2018). Além da RUS, o pacote imblearn propõe não menos de dez métodos diferentes de subamostragem Imblearn (2021). A maioria desses métodos baseia-se em heurísticas de vizinhos mais próximos que removem amostras quando estão próximas ou distantes de outras amostras. Remetemos o leitor a Fernández et al. (2018)Imblearn (2021) para os algoritmos detalhados subjacentes a métodos de subamostragem mais avançados.
As duas próximas subseções mostram como dois desses métodos podem ser implementados e ilustram sua capacidade de mover a fronteira de decisão em direção à classe minoritária. Como exemplos, utilizamos RUS e Vizinhos Mais Próximos Editados (ENN).
Subamostragem aleatória¶
O sampler imblearn para RUS é imblearn.under_sampling.RandomUnderSampler. Vamos ilustrar seu uso e seu impacto na fronteira de decisão do classificador e nos desempenhos de classificação.
%%capture
sampler_list = [('sampler', imblearn.under_sampling.RandomUnderSampler(sampling_strategy=1, random_state=0))]
classifier = sklearn.tree.DecisionTreeClassifier(max_depth=5, random_state=0)
(results_df_RUS, classifier_0, train_df, test_df) = kfold_cv_with_sampler_and_classifier(classifier,
sampler_list,
X, y,
n_splits=5,
strategy_name="Decision tree - RUS")
fig_decision_boundary = plot_decision_boundary(classifier_0, train_df, test_df)Com sampling_strategy definido como um, a RUS remove aleatoriamente amostras da classe majoritária até que seu número atinja o da classe minoritária. Após a reamostragem, cada classe contém 216 amostras.
train_df['Y'].value_counts()0 216
1 216
Name: Y, dtype: int64O gráfico das amostras de treinamento mostra que o número de amostras da classe majoritária foi significativamente reduzido, permitindo um deslocamento da fronteira de decisão em direção à classe minoritária. Ao contrário das técnicas de sobreamostragem, a região localizada no canto inferior direito agora está associada à classe minoritária, pois todas as amostras da classe 0 dessa região foram removidas.
fig_decision_boundary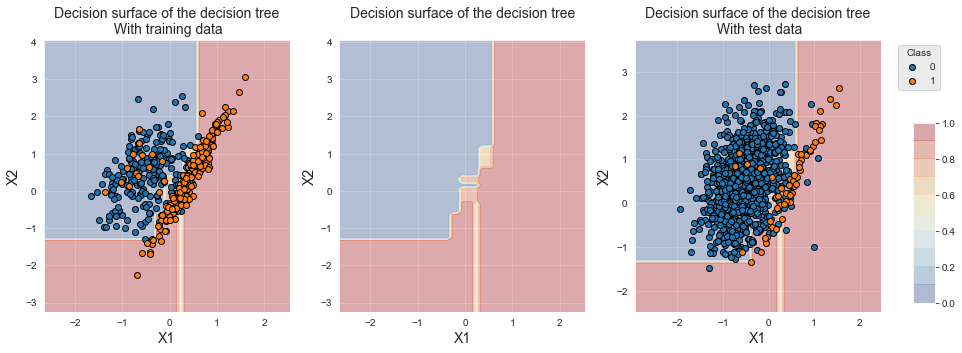
Os desempenhos em termos de AUC ROC e acurácia balanceada são equivalentes às técnicas de sobreamostragem. Observamos, no entanto, uma perda de desempenho em termos de Precisão Média.
pd.concat([results_df_dt_baseline,
results_df_ROS,
results_df_SMOTE,
results_df_RUS])Vale notar que o tempo de treinamento com RUS é mais rápido. Isso resulta do procedimento de subamostragem simples e do menor tamanho do conjunto de treinamento. O método é, portanto, útil não apenas para reduzir a razão de desequilíbrio, mas também para acelerar o tempo de execução do procedimento de modelagem.
Vizinhos Mais Próximos Editados¶
A regra de Vizinhos Mais Próximos Editados é uma técnica de subamostragem que remove amostras da classe majoritária em regiões de sobreposição do conjunto de dados Laurikkala (2001)Wilson (1972). É baseada em uma regra de vizinhos mais próximos, que remove amostras da classe majoritária da seguinte forma Fernández et al. (2018) (Capítulo 5, Página 84):
Para cada amostra da classe majoritária, os k-vizinhos mais próximos são encontrados. Se a maioria dessas amostras for da classe minoritária, a amostra da classe majoritária é removida.
Para cada amostra da classe minoritária, os k-vizinhos mais próximos são encontrados. Se a maioria dessas amostras for da classe majoritária, a(s) amostra(s) da classe majoritária é (são) removida(s).
O número de vizinhos é por padrão definido como . Vale notar que, ao contrário da RUS, o número de amostras da classe majoritária que são removidas depende do grau de sobreposição entre as duas classes. O método não permite especificar uma razão de desequilíbrio.
O sampler imblearn para ENN é imblearn.under_sampling.EditedNearestNeighbours. Vamos ilustrar seu uso e seu impacto na fronteira de decisão do classificador e nos desempenhos de classificação.
%%capture
sampler_list = [('sampler', imblearn.under_sampling.EditedNearestNeighbours(sampling_strategy='majority',n_neighbors=3))]
classifier = sklearn.tree.DecisionTreeClassifier(max_depth=5, random_state=0)
(results_df_ENN, classifier_0, train_df, test_df) = kfold_cv_with_sampler_and_classifier(classifier,
sampler_list,
X, y,
n_splits=5,
strategy_name="Decision tree - ENN")
fig_decision_boundary = plot_decision_boundary(classifier_0, train_df, test_df)Com um número de vizinhos n_neighbors definido como três, o ENN remove apenas cerca de 200 amostras das 3784 amostras da classe majoritária. O número de amostras da classe minoritária é inalterado.
train_df['Y'].value_counts()0 3572
1 216
Name: Y, dtype: int64O gráfico das amostras de treinamento mostra que as distribuições das duas classes são semelhantes às distribuições originais. As amostras que foram removidas estavam na região de sobreposição e sua remoção não é visível devido à grande quantidade de amostras restantes. Observamos, no entanto, um deslocamento na fronteira de decisão, pois a árvore de decisão agora classifica amostras da região de sobreposição na classe minoritária.
fig_decision_boundary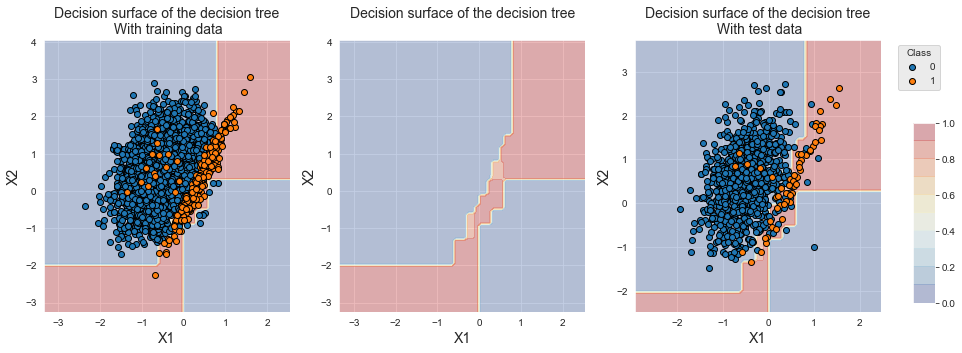
Neste conjunto de dados, os desempenhos do ENN são fracos em comparação com as técnicas testadas anteriormente. A acurácia balanceada foi ligeiramente melhorada em relação ao classificador de linha de base. O desempenho em termos de AP é, no entanto, menor do que a linha de base, e o AUC ROC é o pior de todas as técnicas testadas (equivalente ao ROS).
pd.concat([results_df_dt_baseline,
results_df_ROS,
results_df_SMOTE,
results_df_RUS,
results_df_ENN])Outras estratégias de subamostragem¶
Assim como para as técnicas de sobreamostragem, remetemos o leitor a Fernández et al. (2018) para uma revisão de técnicas de subamostragem mais sofisticadas e à página imblearn sobre métodos de subamostragem para suas implementações em Python. Em particular, a biblioteca imblearn fornece dez outros métodos de subamostragem, que podem ser testados simplesmente substituindo o sampler pelo método desejado no código acima.
Combinando sobreamostragem e subamostragem¶
A sobreamostragem e a subamostragem são frequentemente complementares. Por um lado, as técnicas de sobreamostragem permitem gerar amostras sintéticas da classe minoritária e ajudam um classificador a identificar com mais precisão a fronteira de decisão entre as duas classes. Por outro lado, as técnicas de subamostragem reduzem o tamanho do conjunto de treinamento e permitem acelerar o tempo de treinamento do classificador. A combinação de técnicas de sobreamostragem e subamostragem foi frequentemente relatada como capaz de melhorar com sucesso os desempenhos do classificador (Capítulo 5, Seção 6 em Fernández et al. (2018)).
Em termos de implementação, a combinação de samplers é obtida encadeando os samplers em um pipeline. Os samplers podem então ser encadeados a um classificador. Ilustramos abaixo o encadeamento de uma sobreamostragem SMOTE a uma subamostragem aleatória a um classificador de árvore de decisão.
sampler_list = [('sampler1', imblearn.over_sampling.SMOTE(sampling_strategy=0.5,random_state=0)),
('sampler2', imblearn.under_sampling.RandomUnderSampler(sampling_strategy=1.0,random_state=0))
]
classifier = sklearn.tree.DecisionTreeClassifier(max_depth=5, random_state=0)
estimators = sampler_list.extend([('clf', classifier)])
pipe = imblearn.pipeline.Pipeline(estimators)A função kfold_cv_with_sampler_and_classifier recebe a sampler_list e o classifier como dois argumentos separados, e cuida do encadeamento dos samplers e do classificador. Podemos, portanto, seguir o mesmo modelo anterior para avaliar os desempenhos de um classificador baseado em uma cadeia de técnicas de reamostragem. Os samplers são fornecidos como uma lista com a variável sampler_list.
%%capture
sampler_list = [('sampler1', imblearn.over_sampling.SMOTE(sampling_strategy=0.5,random_state=0)),
('sampler2', imblearn.under_sampling.RandomUnderSampler(sampling_strategy=1.0,random_state=0))
]
classifier = sklearn.tree.DecisionTreeClassifier(max_depth=5, random_state=0)
(results_df_combined, classifier_0, train_df, test_df) = kfold_cv_with_sampler_and_classifier(classifier,
sampler_list,
X, y,
n_splits=5,
strategy_name='Decision tree - Combined SMOTE and RUS')
fig_decision_boundary = plot_decision_boundary(classifier_0, train_df, test_df)A sobreamostragem SMOTE visou uma razão de desequilíbrio de 0,5. Como o conjunto de dados original contém 3784 amostras da classe majoritária, o SMOTE criou novas amostras até que o número de amostras da classe minoritária atingisse amostras. A subamostragem aleatória visou uma razão de desequilíbrio de 1. Como o conjunto de dados reamostrado pelo SMOTE contém 1892 amostras da classe minoritária, as amostras da classe majoritária são removidas até que seu número atinja 1892 amostras.
train_df['Y'].value_counts()0 1892
1 1892
Name: Y, dtype: int64A fronteira de decisão resultante é próxima à obtida com o SMOTE, exceto que uma região ligeiramente maior é agora considerada de classe 1 pelo classificador. Isso é coerente, pois menos amostras da classe minoritária foram criadas.
fig_decision_boundary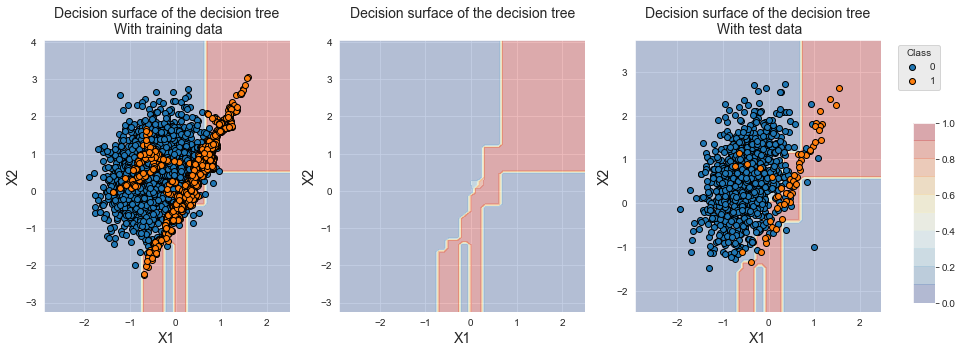
Os desempenhos resultantes são equivalentes aos do SMOTE. Para conjuntos de dados maiores, espera-se, no entanto, tempos de treinamento mais rápidos do que o SMOTE, pois o tamanho do conjunto de treinamento é reduzido graças à subamostragem.
pd.concat([results_df_dt_baseline,
results_df_ROS,
results_df_SMOTE,
results_df_RUS,
results_df_ENN,
results_df_combined])Dados de transações¶
Vamos agora aplicar técnicas de reamostragem ao conjunto de dados simulado de dados de transações. Reutilizamos a metodologia do Capítulo 5, Seleção de Modelos, usando a validação prequencial como estratégia de validação.
Carregamento dos dados¶
O carregamento dos dados e a inicialização dos parâmetros seguem o mesmo modelo do Capítulo 5, Seleção de Modelos.
Notebook Cell
# Load data from the 2018-07-11 to the 2018-09-14
DIR_INPUT = 'simulated-data-transformed/data/'
BEGIN_DATE = "2018-06-11"
END_DATE = "2018-09-14"
print("Load files")
%time transactions_df = read_from_files(DIR_INPUT, BEGIN_DATE, END_DATE)
print("{0} transactions loaded, containing {1} fraudulent transactions".format(len(transactions_df),transactions_df.TX_FRAUD.sum()))
# Number of folds for the prequential validation
n_folds = 4
# Set the starting day for the training period, and the deltas
start_date_training = datetime.datetime.strptime("2018-07-25", "%Y-%m-%d")
delta_train = delta_delay = delta_test = delta_valid = delta_assessment = 7
start_date_training_for_valid = start_date_training+datetime.timedelta(days=-(delta_delay+delta_valid))
start_date_training_for_test = start_date_training+datetime.timedelta(days=(n_folds-1)*delta_test)
output_feature = "TX_FRAUD"
input_features = ['TX_AMOUNT','TX_DURING_WEEKEND', 'TX_DURING_NIGHT', 'CUSTOMER_ID_NB_TX_1DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_1DAY_WINDOW', 'CUSTOMER_ID_NB_TX_7DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_7DAY_WINDOW', 'CUSTOMER_ID_NB_TX_30DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_30DAY_WINDOW', 'TERMINAL_ID_NB_TX_1DAY_WINDOW',
'TERMINAL_ID_RISK_1DAY_WINDOW', 'TERMINAL_ID_NB_TX_7DAY_WINDOW',
'TERMINAL_ID_RISK_7DAY_WINDOW', 'TERMINAL_ID_NB_TX_30DAY_WINDOW',
'TERMINAL_ID_RISK_30DAY_WINDOW']
# Only keep columns that are needed as argument to the custom scoring function
# (in order to reduce the serialization time of transaction dataset)
transactions_df_scorer = transactions_df[['CUSTOMER_ID', 'TX_FRAUD','TX_TIME_DAYS']]
card_precision_top_100 = sklearn.metrics.make_scorer(card_precision_top_k_custom,
needs_proba=True,
top_k=100,
transactions_df=transactions_df_scorer)
performance_metrics_list_grid = ['roc_auc', 'average_precision', 'card_precision@100']
performance_metrics_list = ['AUC ROC', 'Average precision', 'Card Precision@100']
scoring = {'roc_auc':'roc_auc',
'average_precision': 'average_precision',
'card_precision@100': card_precision_top_100,
}
Load files
CPU times: user 812 ms, sys: 580 ms, total: 1.39 s
Wall time: 1.63 s
919767 transactions loaded, containing 8195 fraudulent transactions
Como linha de base, vamos calcular os desempenhos de detecção de fraude com uma árvore de decisão de profundidade 5 sem nenhuma reamostragem.
Notebook Cell
# Define classifier
classifier = sklearn.tree.DecisionTreeClassifier()
# Set of parameters for which to assess model performances
parameters = {'clf__max_depth':[5], 'clf__random_state':[0]}
start_time = time.time()
# Fit models and assess performances for all parameters
performances_df=model_selection_wrapper(transactions_df, classifier,
input_features, output_feature,
parameters, scoring,
start_date_training_for_valid,
start_date_training_for_test,
n_folds=n_folds,
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list,
n_jobs=1)
execution_time_dt = time.time()-start_time
# Select parameter of interest (max_depth)
parameters_dict=dict(performances_df['Parameters'])
performances_df['Parameters summary']=[parameters_dict[i]['clf__max_depth'] for i in range(len(parameters_dict))]
# Rename to performances_df_dt for model performance comparison at the end of this notebook
performances_df_dt=performances_df
summary_performances_dt=get_summary_performances(performances_df_dt, parameter_column_name="Parameters summary")
summary_performances_dtEsta linha de base será usada ao final do notebook para avaliar os benefícios de diferentes técnicas de reamostragem.
Validação prequencial com reamostragem¶
A adição de reamostragem à validação prequencial consiste simplesmente em estender o pipeline definido no Capítulo 5, Estratégias de Validação com os objetos samplers. Adicionamos esta etapa no início da função prequential_grid_search e a renomeamos como prequential_grid_search_with_sampler. Observe que o pipeline é criado com o objeto Pipeline do módulo imblearn para que os samplers sejam processados adequadamente.
Notebook Cell
def prequential_grid_search_with_sampler(transactions_df,
classifier, sampler_list,
input_features, output_feature,
parameters, scoring,
start_date_training,
n_folds=4,
expe_type='Test',
delta_train=7,
delta_delay=7,
delta_assessment=7,
performance_metrics_list_grid=['roc_auc'],
performance_metrics_list=['AUC ROC'],
n_jobs=-1):
estimators = sampler_list.copy()
estimators.extend([('clf', classifier)])
pipe = imblearn.pipeline.Pipeline(estimators)
prequential_split_indices = prequentialSplit(transactions_df,
start_date_training=start_date_training,
n_folds=n_folds,
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment)
grid_search = sklearn.model_selection.GridSearchCV(pipe, parameters, scoring=scoring, cv=prequential_split_indices, refit=False, n_jobs=n_jobs)
X = transactions_df[input_features]
y = transactions_df[output_feature]
grid_search.fit(X, y)
performances_df = pd.DataFrame()
for i in range(len(performance_metrics_list_grid)):
performances_df[performance_metrics_list[i]+' '+expe_type]=grid_search.cv_results_['mean_test_'+performance_metrics_list_grid[i]]
performances_df[performance_metrics_list[i]+' '+expe_type+' Std']=grid_search.cv_results_['std_test_'+performance_metrics_list_grid[i]]
performances_df['Parameters'] = grid_search.cv_results_['params']
performances_df['Execution time'] = grid_search.cv_results_['mean_fit_time']
return performances_dfA função model_selection_wrapper também é modificada para uma função model_selection_wrapper_with_sampler, que chama a função prequential_grid_search_with_sampler para a busca em grade prequencial.
Notebook Cell
def model_selection_wrapper_with_sampler(transactions_df,
classifier,
sampler_list,
input_features, output_feature,
parameters,
scoring,
start_date_training_for_valid,
start_date_training_for_test,
n_folds=4,
delta_train=7,
delta_delay=7,
delta_assessment=7,
performance_metrics_list_grid=['roc_auc'],
performance_metrics_list=['AUC ROC'],
n_jobs=-1):
# Get performances on the validation set using prequential validation
performances_df_validation = prequential_grid_search_with_sampler(transactions_df, classifier, sampler_list,
input_features, output_feature,
parameters, scoring,
start_date_training=start_date_training_for_valid,
n_folds=n_folds,
expe_type='Validation',
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list,
n_jobs=n_jobs)
# Get performances on the test set using prequential validation
performances_df_test = prequential_grid_search_with_sampler(transactions_df, classifier, sampler_list,
input_features, output_feature,
parameters, scoring,
start_date_training=start_date_training_for_test,
n_folds=n_folds,
expe_type='Test',
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list,
n_jobs=n_jobs)
# Bind the two resulting DataFrames
performances_df_validation.drop(columns=['Parameters','Execution time'], inplace=True)
performances_df = pd.concat([performances_df_test,performances_df_validation],axis=1)
# And return as a single DataFrame
return performances_dfA seleção de modelos com reamostragem agora pode ser realizada chamando a função model_selection_wrapper_with_sampler, seguindo a mesma metodologia do Capítulo 5.
Sobreamostragem¶
Vamos ilustrar seu uso com sobreamostragem SMOTE. Criamos um objeto SMOTE e o armazenamos em uma lista sampler_list. A lista é passada como argumento para a função model_selection_wrapper_with_sampler. Adicionalmente, o parâmetro sampling_strategy do objeto SMOTE (razão de desequilíbrio) é parametrizado para assumir valores no conjunto para o procedimento de seleção de modelos.
# Define classifier
classifier = sklearn.tree.DecisionTreeClassifier()
# Define sampling strategy
sampler_list = [('sampler', imblearn.over_sampling.SMOTE(random_state=0))]
# Set of parameters for which to assess model performances
parameters = {'clf__max_depth':[5], 'clf__random_state':[0],
'sampler__sampling_strategy':[0.01, 0.05, 0.1, 0.5, 1], 'sampler__random_state':[0]}
start_time = time.time()
# Fit models and assess performances for all parameters
performances_df=model_selection_wrapper_with_sampler(transactions_df, classifier, sampler_list,
input_features, output_feature,
parameters, scoring,
start_date_training_for_valid,
start_date_training_for_test,
n_folds=n_folds,
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list,
n_jobs=1)
execution_time_dt_SMOTE = time.time()-start_time
Em seguida, recuperamos os desempenhos para cada uma das razões de desequilíbrio testadas (valor de sampling_strategy) e armazenamos os resultados em um DataFrame performances_df_SMOTE.
# Select parameter of interest (sampling_strategy)
parameters_dict=dict(performances_df['Parameters'])
performances_df['Parameters summary']=[parameters_dict[i]['sampler__sampling_strategy'] for i in range(len(parameters_dict))]
# Rename to performances_df_SMOTE for model performance comparison at the end of this notebook
performances_df_SMOTE = performances_dfperformances_df_SMOTEVamos resumir os desempenhos para destacar as razões de desequilíbrio ótimas.
summary_performances_SMOTE = get_summary_performances(performances_df_SMOTE, parameter_column_name="Parameters summary")
summary_performances_SMOTEObservamos resultados conflitantes, pois a razão de desequilíbrio ótima depende da métrica de desempenho. Para melhor visualização, vamos plotar os desempenhos em função da razão de desequilíbrio para as três métricas de desempenho.
get_performances_plots(performances_df_SMOTE,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="Imbalance ratio",
summary_performances=summary_performances_SMOTE)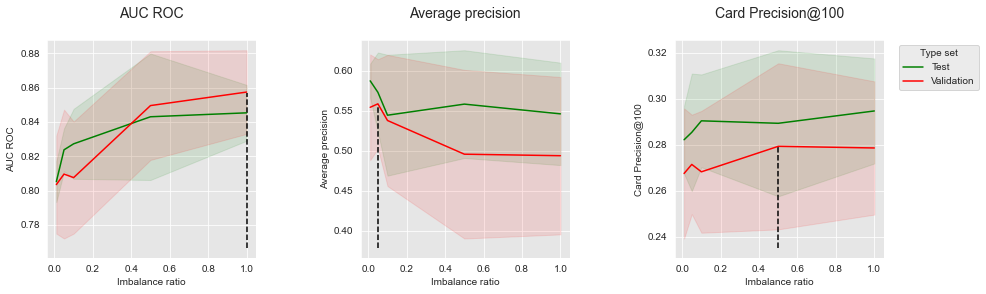
Os desempenhos tendem a aumentar com a razão de desequilíbrio para AUC ROC e CP@100. O oposto é observado, no entanto, para a Precisão Média. A criação de amostras sintéticas com SMOTE é, portanto, benéfica para AUC ROC e CP@100, mas prejudicial à Precisão Média.
Subamostragem¶
Vamos seguir a mesma metodologia usando subamostragem aleatória. O objeto RandomUnderSampler é usado, e os modelos são avaliados para razões de desequilíbrio assumindo valores no conjunto .
# Define classifier
classifier = sklearn.tree.DecisionTreeClassifier()
# Define sampling strategy
sampler_list = [('sampler', imblearn.under_sampling.RandomUnderSampler())]
# Set of parameters for which to assess model performances
parameters = {'clf__max_depth':[5], 'clf__random_state':[0],
'sampler__sampling_strategy':[0.01, 0.05, 0.1, 0.5, 1], 'sampler__random_state':[0]}
start_time = time.time()
# Fit models and assess performances for all parameters
performances_df=model_selection_wrapper_with_sampler(transactions_df, classifier, sampler_list,
input_features, output_feature,
parameters, scoring,
start_date_training_for_valid,
start_date_training_for_test,
n_folds=n_folds,
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list,
n_jobs=1)
execution_time_dt_RUS = time.time()-start_time
# Select parameter of interest (sampling_strategy)
parameters_dict=dict(performances_df['Parameters'])
performances_df['Parameters summary']=[parameters_dict[i]['sampler__sampling_strategy'] for i in range(len(parameters_dict))]
# Rename to performances_df_RUS for model performance comparison at the end of this notebook
performances_df_RUS = performances_df
Vamos resumir os desempenhos para destacar as razões de desequilíbrio ótimas e plotar os desempenhos em função da razão de desequilíbrio.
summary_performances_RUS=get_summary_performances(performances_df_RUS, parameter_column_name="Parameters summary")
summary_performances_RUSget_performances_plots(performances_df_RUS,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="Imbalance ratio",
summary_performances=summary_performances_RUS)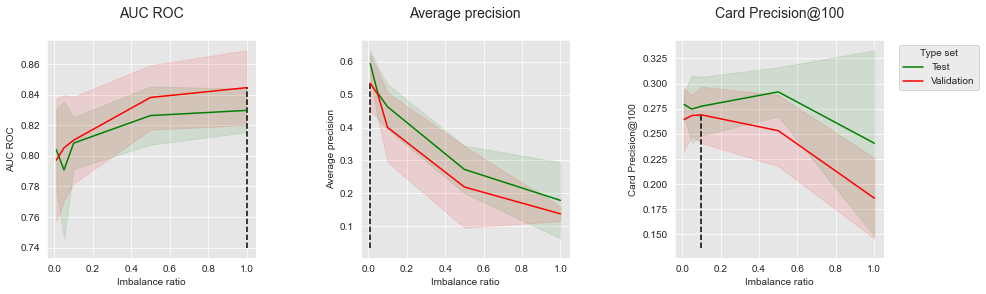
Assim como na sobreamostragem, reequilibrar o conjunto de dados leva a um aumento de desempenho em termos de AUC ROC, mas a uma forte diminuição de desempenho em termos de AP. Os resultados em termos de CP@100 seguem uma tendência intermediária: o desempenho primeiro aumenta ligeiramente com a razão de desequilíbrio, e depois diminui com uma subamostragem mais agressiva.
Combinação¶
Ilustramos finalmente a combinação de sobreamostragem e subamostragem com SMOTE e subamostragem aleatória. Os objetos SMOTE e RandomUnderSampler são instanciados e armazenados na lista sampler_list. Parametrizamos o sampler SMOTE com uma razão de desequilíbrio alvo de e o RandomUnderSampler para assumir valores no conjunto .
# Define classifier
classifier = sklearn.tree.DecisionTreeClassifier()
# Define sampling strategy
sampler_list = [('sampler1', imblearn.over_sampling.SMOTE()),
('sampler2', imblearn.under_sampling.RandomUnderSampler())
]
# Set of parameters for which to assess model performances
parameters = {'clf__max_depth':[5], 'clf__random_state':[0],
'sampler1__sampling_strategy':[0.1],
'sampler2__sampling_strategy':[0.1, 0.5, 1],
'sampler1__random_state':[0], 'sampler2__random_state':[0]}
start_time = time.time()
# Fit models and assess performances for all parameters
performances_df = model_selection_wrapper_with_sampler(transactions_df, classifier, sampler_list,
input_features, output_feature,
parameters, scoring,
start_date_training_for_valid,
start_date_training_for_test,
n_folds=n_folds,
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list,
n_jobs=1)
execution_time_dt_combined = time.time()-start_time
# Select parameter of interest (max_depth)
parameters_dict = dict(performances_df['Parameters'])
performances_df['Parameters summary']=[parameters_dict[i]['sampler2__sampling_strategy'] for i in range(len(parameters_dict))]
# Rename to performances_df_combined for model performance comparison at the end of this notebook
performances_df_combined = performances_df
performances_df_combinedVamos resumir os desempenhos para destacar as razões de desequilíbrio ótimas e plotar os desempenhos em função da razão de desequilíbrio.
summary_performances_combined = get_summary_performances(performances_df=performances_df_combined,
parameter_column_name="Parameters summary")
summary_performances_combinedget_performances_plots(performances_df_combined,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="Imbalance ratio",
summary_performances=summary_performances_combined)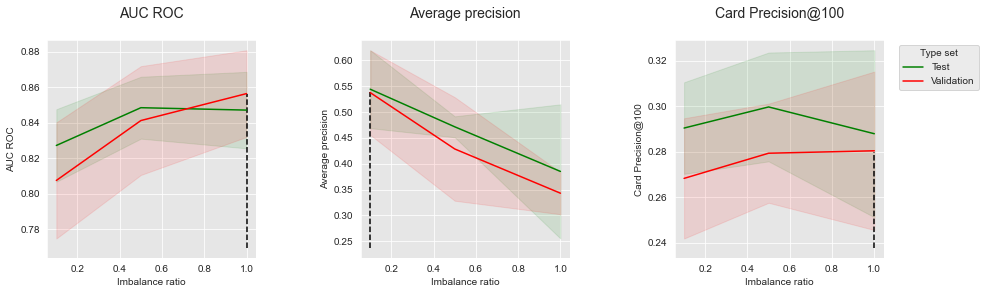
Os resultados seguem as mesmas tendências da sobreamostragem e subamostragem: o reequilíbrio melhora os desempenhos em termos de AUC ROC, mas diminui os desempenhos em termos de Precisão Média. O impacto do reequilíbrio no CP@100 é misto.
Vamos finalmente comparar os desempenhos de teste obtidos com sobreamostragem, subamostragem e reamostragem combinada, e compará-los ao classificador de linha de base.
summary_test_performances = pd.concat([summary_performances_dt.iloc[2,:],
summary_performances_SMOTE.iloc[2,:],
summary_performances_RUS.iloc[2,:],
summary_performances_combined.iloc[2,:],
],axis=1)
summary_test_performances.columns=['Baseline', 'SMOTE', 'RUS', 'Combined']
summary_test_performancesEm comparação com o classificador de linha de base, todas as técnicas de reamostragem conseguiram melhorar os desempenhos em termos de AUC ROC. Todas elas, no entanto, levaram a uma diminuição na Precisão Média. Ligeiras melhorias em termos de CP@100 puderam ser alcançadas com SMOTE e a abordagem combinada, mas não com subamostragem.
Resumo¶
Os experimentos realizados nesta seção ilustraram que os benefícios das técnicas de reamostragem dependem da métrica de desempenho utilizada. Embora a reamostragem possa geralmente ser benéfica para o AUC ROC, observamos que elas levaram, em quase todos os casos, a uma diminuição de desempenho em termos de Precisão Média. Vale notar que os resultados são coerentes com os obtidos usando técnicas sensíveis ao custo na seção anterior.
Salvamento dos resultados¶
Vamos finalmente salvar os resultados de desempenho e os tempos de execução.
performances_df_dictionary={
"SMOTE": performances_df_SMOTE,
"RUS": performances_df_RUS,
"Combined": performances_df_combined
}
execution_times=[execution_time_dt_SMOTE,
execution_time_dt_RUS,
execution_time_dt_combined,
]
filehandler = open('performances_resampling.pkl', 'wb')
pickle.dump((performances_df_dictionary, execution_times), filehandler)
filehandler.close()- Fernández, A., Garcı́a, S., Galar, M., Prati, R. C., Krawczyk, B., & Herrera, F. (2018). Learning from imbalanced data sets. Springer.
- Lemaître, G., Nogueira, F., & Aridas, C. K. (2017). Imbalanced-learn: A Python Toolbox to Tackle the Curse of Imbalanced Datasets in Machine Learning. Journal of Machine Learning Research, 18(17), 1–5. http://jmlr.org/papers/v18/16-365.html
- Chawla, N. V. (2009). Data mining for imbalanced datasets: An overview. In Data mining and knowledge discovery handbook (pp. 875–886). Springer.
- Chawla, N. V., Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P. (2002). SMOTE: synthetic minority over-sampling technique. Journal of Artificial Intelligence Research, 16, 321–357.
- He, H., Bai, Y., Garcia, E. A., & Li, S. (2008). ADASYN: Adaptive synthetic sampling approach for imbalanced learning. 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), 1322–1328.
- Ali, H., Salleh, M. N. M., Hussain, K., Ahmad, A., Ullah, A., Muhammad, A., Naseem, R., & Khan, M. (2019). A review on data preprocessing methods for class imbalance problem. International Journal of Engineering & Technology, 8, 390–397.
- Mani, I., & Zhang, I. (2003). kNN approach to unbalanced data distributions: a case study involving information extraction. Proceedings of Workshop on Learning from Imbalanced Datasets, 126.
- Tomek, I., & others. (1976). Two modifications of CNN. IEEE Trans. Syst. Man Commun, 1, 769–772.
- Wilson, D. L. (1972). Asymptotic properties of nearest neighbor rules using edited data. IEEE Transactions on Systems, Man, and Cybernetics, 3, 408–421.
- Yen, S.-J., & Lee, Y.-S. (2009). Cluster-based under-sampling approaches for imbalanced data distributions. Expert Systems with Applications, 36(3), 5718–5727.
- Haixiang, G., Yijing, L., Shang, J., Mingyun, G., Yuanyue, H., & Bing, G. (2017). Learning from class-imbalanced data: Review of methods and applications. Expert Systems with Applications, 73, 220–239.
- Batista, G. E., Prati, R. C., & Monard, M. C. (2004). A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explorations Newsletter, 6(1), 20–29.
- Batista, G. E., Bazzan, A. L., Monard, M. C., & others. (2003). Balancing Training Data for Automated Annotation of Keywords: a Case Study. WOB, 10–18.
- Imblearn. (2021). Imbalanced learning library for Python. %5Curl%7Bhttps://imbalanced-learn.org/%7D
- Dal Pozzolo, A. (2015). Adaptive machine learning for credit card fraud detection. Université libre de Bruxelles.