Os métodos de ensemble consistem em treinar múltiplos modelos de predição para a mesma tarefa de predição e combinar suas saídas para fazer a previsão final Fernández et al. (2018)Haixiang et al. (2017)Bontempi (2021). Ensembles de modelos frequentemente permitem fornecer melhores desempenhos de predição do que modelos individuais, pois combinar as previsões de múltiplos modelos geralmente permite reduzir o fenômeno de sobreajuste. Os modelos de predição que compõem um ensemble são chamados de aprendizes de base. Tanto a forma como os aprendizes de base são construídos quanto como suas previsões são combinadas são fatores-chave no design de um ensemble Fernández et al. (2018)Bontempi (2021)Friedman et al. (2001).
Os métodos de ensemble podem ser amplamente divididos em ensembles baseados em paralelo e baseados em iteração Haixiang et al. (2017). Nos ensembles baseados em paralelo, cada aprendiz de base é treinado em paralelo, usando um subconjunto dos dados de treinamento, um subconjunto das características de treinamento, ou uma combinação de ambos. As duas técnicas mais populares para ensembles baseados em paralelo são o bagging Breiman (1996) e a floresta aleatória Breiman (2001). Nos ensembles baseados em iteração, também chamados de boosting Friedman et al. (2001)Freund & Schapire (1997), os classificadores de base são treinados em sequência, com cada aprendiz na sequência visando minimizar os erros de predição do aprendiz anterior. As implementações mais amplamente usadas atualmente para boosting são XGBoost Chen & Guestrin (2016), CatBoost Dorogush et al. (2018) e LightGBM Ke et al. (2017).
A capacidade dos métodos de ensemble de melhorar os desempenhos de predição foi ilustrada no capítulo anterior (ver Seções Comparação de desempenhos de modelos e Comparação de desempenhos de modelos: Resumo). Em particular, nossa comparação experimental mostrou que florestas aleatórias e XGBoost permitiram melhorar significativamente o AUC ROC e a Precisão Média em comparação com árvores de decisão e regressão logística.
Esta seção faz uma análise mais específica dos métodos de ensemble no contexto de dados desequilibrados. Uma estratégia comum ao lidar com ensembles e dados desequilibrados é usar uma amostragem diferente do conjunto de treinamento para o treinamento dos aprendizes de base. O procedimento é ilustrado na Fig. 1 para ensembles baseados em paralelo. Uma primeira etapa de reamostragem pode visar reequilibrar amostras por meio de sobreamostragem da classe minoritária, subamostragem da classe majoritária, ou ambas. Em uma segunda etapa, o número de características também pode ser amostrado antes de prosseguir para o treinamento dos aprendizes de base Haixiang et al. (2017)Fernández et al. (2018).
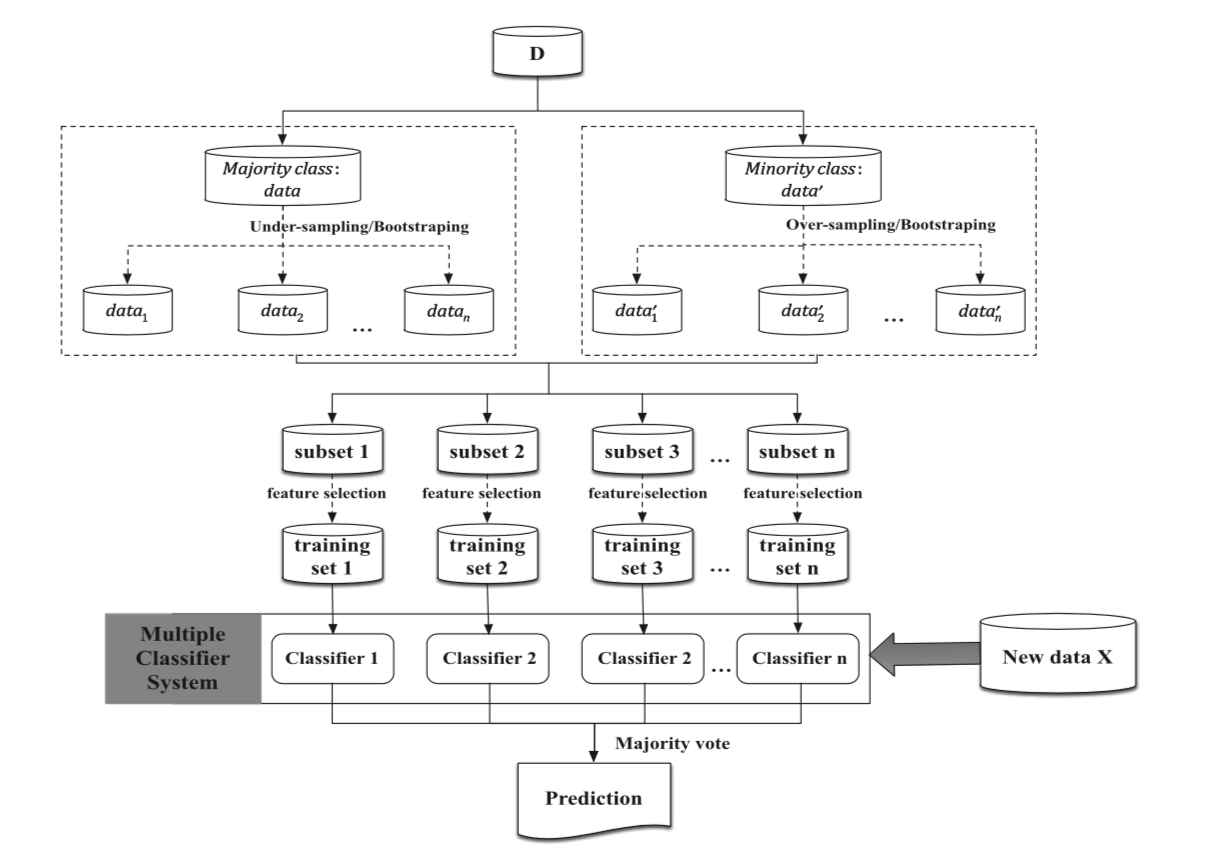
Fig. 1. Framework baseado em paralelo no contexto de dados desequilibrados. Estratégias de amostragem podem ser aplicadas no nível das amostras ou características (ou ambas) antes de treinar os classificadores de base Haixiang et al. (2017).
As técnicas de aprendizado sensível ao custo também podem ser usadas junto com técnicas de reamostragem ponderando as classes durante o treinamento dos aprendizes de base. Os métodos de ensemble, portanto, fornecem um framework muito flexível, onde todas as técnicas apresentadas nas duas seções anteriores podem ser usadas, mas também combinadas com diferentes tipos de aprendizes de base.
A diversidade de abordagens possíveis é ilustrada nesta seção discutindo três métodos de ensemble diferentes para aprendizado com dados desequilibrados: Bagging balanceado Maclin & Opitz (1997), floresta aleatória balanceada Chen et al. (2004) e XGBoost ponderado Chen & Guestrin (2016).
Notebook Cell
# Initialization: Load shared functions and simulated data
# Load shared functions
!curl -O https://raw.githubusercontent.com/Fraud-Detection-Handbook/fraud-detection-handbook/main/Chapter_References/shared_functions.py
%run shared_functions.py
#%run ../Chapter_References/shared_functions.ipynb
# Get simulated data from Github repository
if not os.path.exists("simulated-data-transformed"):
!git clone https://github.com/Fraud-Detection-Handbook/simulated-data-transformed
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 63060 100 63060 0 0 144k 0 --:--:-- --:--:-- --:--:-- 145k
Exemplo ilustrativo¶
Vamos primeiro considerar a tarefa de classificação simples apresentada na seção anterior.
Notebook Cell
X, y = sklearn.datasets.make_classification(n_samples=5000, n_features=2, n_informative=2,
n_redundant=0, n_repeated=0, n_classes=2,
n_clusters_per_class=1,
weights=[0.95, 0.05],
class_sep=0.5, random_state=0)
dataset_df = pd.DataFrame({'X1':X[:,0],'X2':X[:,1], 'Y':y})
Notebook Cell
%%capture
fig_distribution, ax = plt.subplots(1, 1, figsize=(5,5))
groups = dataset_df.groupby('Y')
for name, group in groups:
ax.scatter(group.X1, group.X2, edgecolors='k', label=name,alpha=1,marker='o')
ax.legend(loc='upper left',
bbox_to_anchor=(1.05, 1),
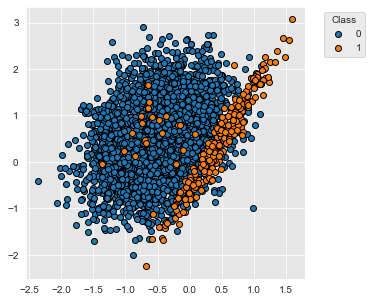
title="Class")O conjunto de dados contém 5000 amostras com duas classes, rotuladas 0 e 1. 95% das amostras estão associadas à classe 0 e 5% das amostras à classe 1.
fig_distribution
Bagging¶
O bagging baseia-se no conceito de agregação bootstrap, que consiste em treinar vários aprendizes de base com diferentes réplicas do conjunto de dados de treinamento original Breiman (1996). A prática mais usual é extrair aleatoriamente, com reposição, instâncias do conjunto de dados original. O tamanho do conjunto de dados é mantido, o que significa que aproximadamente 63,2% das instâncias estão presentes em cada amostra (e algumas instâncias aparecem mais de uma vez) Fernández et al. (2018).
A implementação Python padrão para bagging é fornecida como parte da biblioteca sklearn, com o objeto BaggingClassifier. Seguindo a mesma metodologia das seções anteriores, vamos treinar um classificador de bagging, avaliar seus desempenhos e plotar a fronteira de decisão resultante. Usamos neste exemplo árvores de decisão de profundidade 5 como aprendizes de base e construímos um ensemble de 100 árvores.
%%capture
classifier = sklearn.ensemble.BaggingClassifier(base_estimator=sklearn.tree.DecisionTreeClassifier(max_depth=5,random_state=0),
n_estimators=100,
bootstrap=True,
random_state=0)
(results_df_bagging, classifier_0, train_df, test_df) = kfold_cv_with_classifier(classifier,
X, y,
n_splits=5,
strategy_name="Bagging")
fig_decision_boundary = plot_decision_boundary(classifier_0, train_df, test_df)
results_df_baggingOs desempenhos de classificação deste classificador de bagging são melhores do que os de uma única árvore de decisão (ver resultados de linha de base no aprendizado sensível ao custo) para AUC ROC e Precisão Média, mas menores em termos de acurácia balanceada.
fig_decision_boundary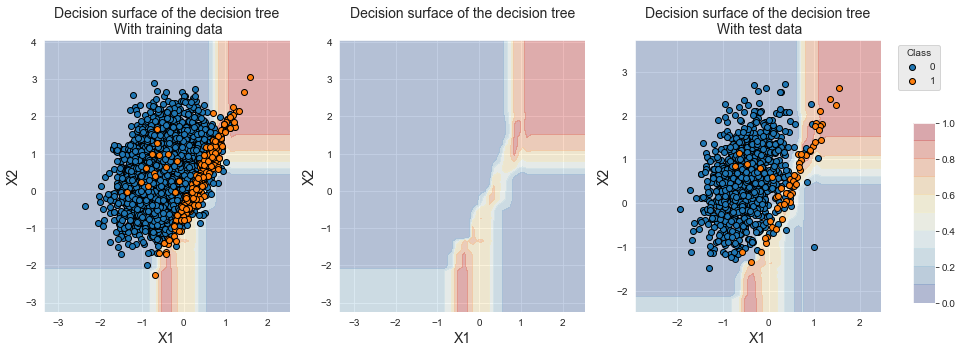
Em comparação com uma única árvore de decisão, a fronteira de decisão é mais refinada. A maioria das amostras na região de sobreposição é, no entanto, classificada na classe majoritária devido à natureza desequilibrada do conjunto de dados.
Bagging balanceado¶
O bagging balanceado Maclin & Opitz (1997) segue a mesma estratégia do bagging, exceto que os dados de treinamento são reamostrados usando técnicas de aprendizado com dados desequilibrados. Uma implementação de bagging balanceado é fornecida pelo objeto BalancedBaggingClassifier da biblioteca imblearn. O tipo de sampler e a razão de desequilíbrio desejada são definidos com os parâmetros sampler e sampling_strategy, respectivamente. Os parâmetros padrão consistem em usar um subamostrador aleatório e uma razão de desequilíbrio de 1, o que significa que as amostras da classe majoritária são removidas aleatoriamente até que seu número seja igual ao da classe minoritária (ver Seção Subamostragem).
Vamos treinar um ensemble de árvores de decisão usando um BalancedBaggingClassifier com seus parâmetros padrão e avaliar seus desempenhos e fronteira de decisão.
%%capture
classifier = imblearn.ensemble.BalancedBaggingClassifier(base_estimator=sklearn.tree.DecisionTreeClassifier(max_depth=5,random_state=0),
n_estimators=100,
sampling_strategy=1,
bootstrap=True,
sampler=imblearn.under_sampling.RandomUnderSampler(),
random_state=0)
(results_df_balanced_bagging, classifier_0, train_df, test_df) = kfold_cv_with_classifier(classifier,
X, y,
n_splits=5,
strategy_name="Balanced bagging")
fig_decision_boundary = plot_decision_boundary(classifier_0, train_df, test_df)
pd.concat([results_df_bagging,
results_df_balanced_bagging])
Os desempenhos resultantes são similares ao bagging em termos de AUC ROC e Precisão Média. A acurácia balanceada é, no entanto, muito maior com o bagging balanceado. Isso resulta do deslocamento da fronteira de decisão em direção à região que contém a classe minoritária, como é ilustrado abaixo.
fig_decision_boundary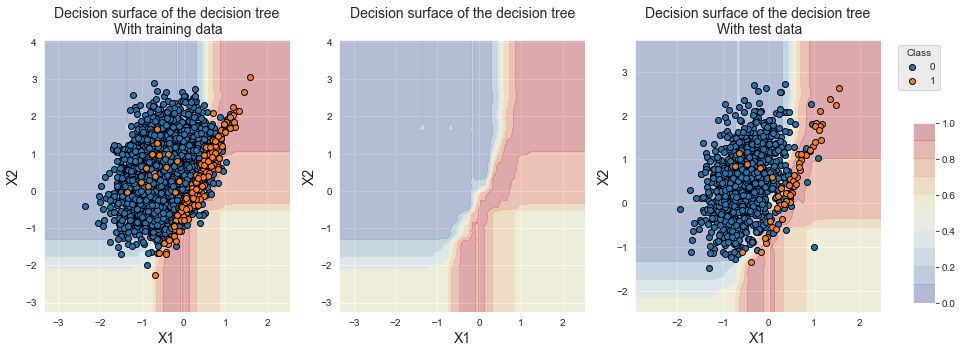
Vale notar que a região no canto inferior direito agora está associada à classe minoritária. Isso se deve à subamostragem aleatória, como já foi observado na seção anterior com uma única árvore de decisão.
Floresta aleatória¶
As florestas aleatórias foram introduzidas por Breiman em 2001 Breiman (2001). Tornaram-se uma das técnicas de AM mais populares para uma ampla gama de tarefas de predição, entre as quais a detecção de fraudes Priscilla & Prabha (2019)Haixiang et al. (2017).
Uma floresta aleatória é um ensemble de árvores de decisão, onde cada árvore é construída usando um subconjunto aleatório dos dados de treinamento. O método está, portanto, intimamente relacionado ao bagging. A principal diferença está na construção das árvores de decisão, onde a divisão é feita usando apenas um subconjunto aleatório das características. Essa variação aleatória adicional tem consequências benéficas. Primeiro, geralmente leva a melhores desempenhos preditivos graças a uma maior diversidade nas estruturas das árvores, menor sobreajuste e maior robustez a ruídos e outliers. Segundo, também acelera os tempos de computação, pois menos características são consideradas na construção das árvores Breiman (2001).
O procedimento de floresta aleatória é fornecido no Python sklearn pelo objeto RandomForestClassifier. Os principais parâmetros são a profundidade máxima da árvore e o número de árvores, definidos com os parâmetros max_depth e n_estimators, respectivamente.
Vamos treinar um classificador de floresta aleatória com 100 árvores e profundidade máxima de 5 e avaliar seus desempenhos e fronteira de decisão.
%%capture
classifier = sklearn.ensemble.RandomForestClassifier(n_estimators=100,
max_depth=5,
random_state=0)
(results_df_rf, classifier_0, train_df, test_df) = kfold_cv_with_classifier(classifier,
X, y,
n_splits=5,
strategy_name="Random forest")
fig_decision_boundary = plot_decision_boundary(classifier_0, train_df, test_df)
pd.concat([results_df_bagging,
results_df_balanced_bagging,
results_df_rf])
Os desempenhos em termos de AUC ROC e Precisão Média são similares ao bagging, e a acurácia balanceada ligeiramente menor. O tempo de treinamento é significativamente reduzido.
fig_decision_boundary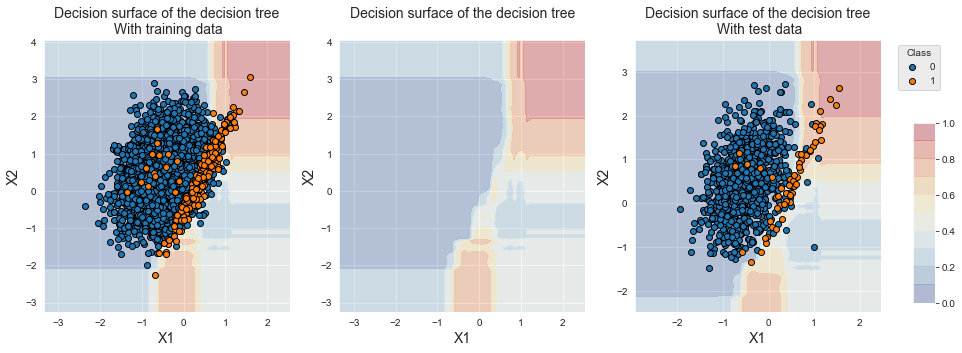
A fronteira de decisão também é similar ao que foi obtido com o bagging, o que reflete a similaridade entre os dois procedimentos.
Floresta aleatória balanceada¶
A floresta aleatória balanceada foi introduzida em Chen et al. (2004) para lidar com dados desequilibrados. O procedimento segue o mesmo raciocínio do bagging balanceado e consiste em construir os aprendizes de base com conjuntos de treinamento balanceados. O procedimento é implementado com o objeto BalancedRandomForestClassifier da biblioteca Python imblearn.
O parâmetro sampling_strategy determina a razão de desequilíbrio dos conjuntos de treinamento usados para construir as árvores de decisão. Vamos treinar um classificador de floresta aleatória balanceada com 100 árvores, profundidade máxima de 5 e razão de desequilíbrio de 1, e avaliar seus desempenhos e fronteira de decisão.
%%capture
classifier = imblearn.ensemble.BalancedRandomForestClassifier(n_estimators=100,
sampling_strategy=1,
max_depth=5,
random_state=0)
(results_df_rf_balanced, classifier_0, train_df, test_df) = kfold_cv_with_classifier(classifier,
X, y,
n_splits=5,
strategy_name="Balanced random forest")
fig_decision_boundary = plot_decision_boundary(classifier_0, train_df, test_df)
Os desempenhos resultantes são equivalentes ao bagging balanceado.
pd.concat([results_df_bagging,
results_df_balanced_bagging,
results_df_rf,
results_df_rf_balanced])
Observamos que o procedimento de treinamento é mais rápido do que o bagging balanceado.
fig_decision_boundary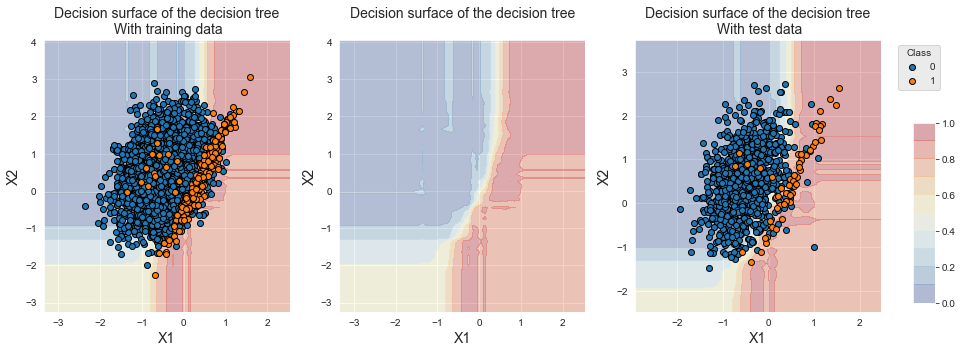
Semelhante ao bagging balanceado, também observamos que a fronteira de decisão é deslocada em direção à classe minoritária e que a região no canto inferior direito está associada à classe minoritária.
XGBoost¶
XGBoost significa extreme gradient boosting (gradiente boosting extremo) e é uma das técnicas de ensemble mais eficientes em aprendizado de máquina. Demonstrou fornecer resultados de ponta em uma série de benchmarks de aprendizado de máquina, bem como em competições Kaggle Bentéjac et al. (2021)Chen & Guestrin (2016).
O XGBoost fornece uma implementação escalável de gradient tree boosting Friedman (2001). Os detalhes da implementação vão além do escopo deste livro, e remetemos o leitor a Chen & Guestrin (2016) para a descrição do algoritmo e sua otimização.
A implementação Python é fornecida pelo objeto XGBClassifier da biblioteca XGBoost. O XGBoost tem muitos parâmetros de ajuste, sendo os mais importantes o número de rodadas de boosting n_estimators, a profundidade máxima da árvore dos aprendizes de base max_depth e a taxa de aprendizado learning_rate.
Vamos treinar um classificador XGBoost e avaliar seus desempenhos e fronteira de decisão. Usamos a seguir os parâmetros padrão, que consistem em 100 rodadas de boosting, uma profundidade máxima de árvore de 6 e uma taxa de aprendizado de 0,3.
%%capture
classifier = xgboost.XGBClassifier(n_estimators=100,
max_depth=6,
learning_rate=0.3,
random_state=0)
(results_df_xgboost, classifier_0, train_df, test_df) = kfold_cv_with_classifier(classifier,
X, y,
n_splits=5,
strategy_name="XGBoost")
fig_decision_boundary = plot_decision_boundary(classifier_0, train_df, test_df)
O classificador resultante fornece desempenhos competitivos com os obtidos com bagging e floresta aleatória.
pd.concat([results_df_bagging,
results_df_balanced_bagging,
results_df_rf,
results_df_rf_balanced,
results_df_xgboost])
Vamos plotar a fronteira de decisão resultante.
fig_decision_boundary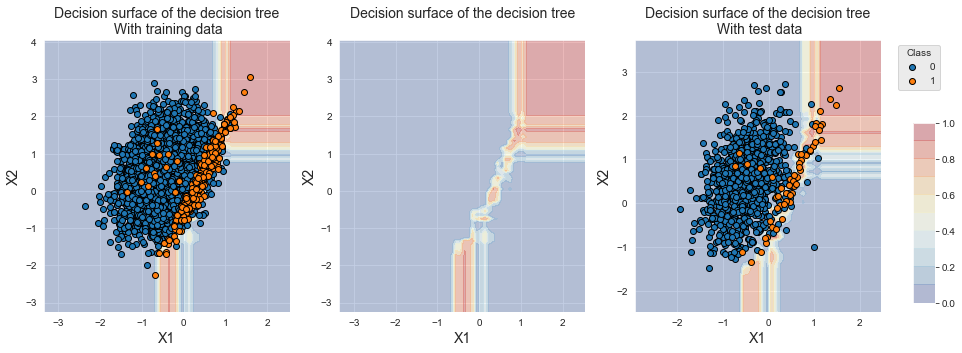
A fronteira de decisão difere ligeiramente do bagging e da floresta aleatória. O XGBoost isola com mais precisão a região contendo amostras da classe minoritária.
XGBoost ponderado¶
O aprendizado sensível ao custo pode ser aplicado ao XGBoost por meio do parâmetro scale_pos_weight. Assumindo que o custo de um falso positivo é 1, o parâmetro determina o custo de um falso negativo. Vale notar que este parâmetro é o único para lidar com dados desequilibrados usando XGBoost: ao contrário do bagging e da floresta aleatória, o XGBoost não pode ser combinado com técnicas de reamostragem.
Vamos usar a razão de desequilíbrio para definir o peso de classe. Como há 5% de amostras da classe minoritária e 95% de amostras da classe majoritária, a razão de desequilíbrio RD é:
IR=0.05/0.95
IR0.052631578947368425Como scale_pos_weight quantifica o custo de um falso negativo, definimos seu valor como o inverso da razão de desequilíbrio.
%%capture
classifier = xgboost.XGBClassifier(n_estimators=100,
max_depth=6,
learning_rate=0.3,
scale_pos_weight=1/IR,
random_state=0)
(results_df_weighted_xgboost, classifier_0, train_df, test_df) = kfold_cv_with_classifier(classifier,
X, y,
n_splits=5,
strategy_name="Weighted XGBoost")
fig_decision_boundary = plot_decision_boundary(classifier_0, train_df, test_df)
Em comparação com o XGBoost, a ponderação de falsos negativos permite um ligeiro aumento em termos de Precisão Média e acurácia balanceada e desempenho similar em termos de AUC ROC. Observamos que a acurácia balanceada é menor do que as obtidas com bagging balanceado e floresta aleatória balanceada.
pd.concat([results_df_bagging,
results_df_balanced_bagging,
results_df_rf,
results_df_rf_balanced,
results_df_xgboost,
results_df_weighted_xgboost])
fig_decision_boundary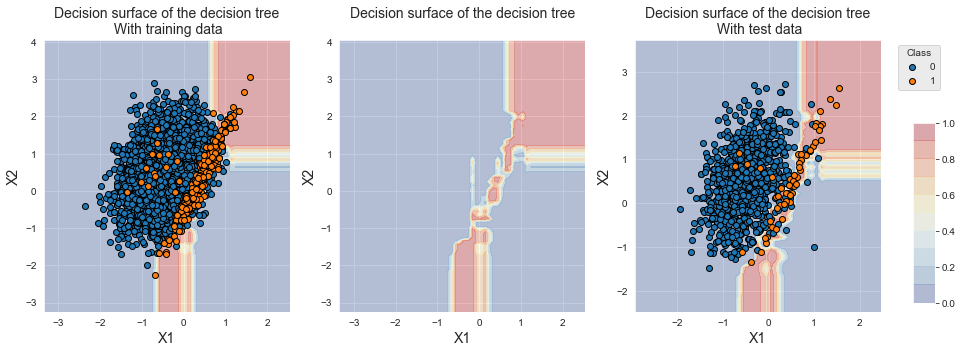
A fronteira de decisão mostra que uma região maior agora está associada à classe minoritária. Curiosamente, o XGBoost não sobrajusta tanto quanto o bagging balanceado e a floresta aleatória balanceada. Em particular, a região no canto inferior direito permanece associada à classe majoritária.
Dados de transações¶
Vamos agora aplicar essas três técnicas de ensemble ao conjunto de dados simulado de dados de transações. Reutilizamos a metodologia do Capítulo 5, Seleção de Modelos, usando a validação prequencial como estratégia de validação.
Carregamento dos dados¶
O carregamento dos dados e a inicialização dos parâmetros seguem o mesmo modelo do Capítulo 5, Seleção de Modelos.
Notebook Cell
# Load data from the 2018-07-11 to the 2018-09-14
DIR_INPUT = 'simulated-data-transformed/data/'
BEGIN_DATE = "2018-06-11"
END_DATE = "2018-09-14"
print("Load files")
%time transactions_df = read_from_files(DIR_INPUT, BEGIN_DATE, END_DATE)
print("{0} transactions loaded, containing {1} fraudulent transactions".format(len(transactions_df),transactions_df.TX_FRAUD.sum()))
# Number of folds for the prequential validation
n_folds = 4
# Set the starting day for the training period, and the deltas
start_date_training = datetime.datetime.strptime("2018-07-25", "%Y-%m-%d")
delta_train = delta_delay = delta_test = delta_valid = delta_assessment = 7
start_date_training_for_valid = start_date_training+datetime.timedelta(days=-(delta_delay+delta_valid))
start_date_training_for_test = start_date_training+datetime.timedelta(days=(n_folds-1)*delta_test)
output_feature = "TX_FRAUD"
input_features = ['TX_AMOUNT','TX_DURING_WEEKEND', 'TX_DURING_NIGHT', 'CUSTOMER_ID_NB_TX_1DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_1DAY_WINDOW', 'CUSTOMER_ID_NB_TX_7DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_7DAY_WINDOW', 'CUSTOMER_ID_NB_TX_30DAY_WINDOW',
'CUSTOMER_ID_AVG_AMOUNT_30DAY_WINDOW', 'TERMINAL_ID_NB_TX_1DAY_WINDOW',
'TERMINAL_ID_RISK_1DAY_WINDOW', 'TERMINAL_ID_NB_TX_7DAY_WINDOW',
'TERMINAL_ID_RISK_7DAY_WINDOW', 'TERMINAL_ID_NB_TX_30DAY_WINDOW',
'TERMINAL_ID_RISK_30DAY_WINDOW']
# Only keep columns that are needed as argument to the custom scoring function
# (in order to reduce the serialization time of transaction dataset)
transactions_df_scorer = transactions_df[['CUSTOMER_ID', 'TX_FRAUD','TX_TIME_DAYS']]
card_precision_top_100 = sklearn.metrics.make_scorer(card_precision_top_k_custom,
needs_proba=True,
top_k=100,
transactions_df=transactions_df_scorer)
performance_metrics_list_grid = ['roc_auc', 'average_precision', 'card_precision@100']
performance_metrics_list = ['AUC ROC', 'Average precision', 'Card Precision@100']
scoring = {'roc_auc':'roc_auc',
'average_precision': 'average_precision',
'card_precision@100': card_precision_top_100,
}
Load files
CPU times: user 731 ms, sys: 526 ms, total: 1.26 s
Wall time: 1.31 s
919767 transactions loaded, containing 8195 fraudulent transactions
Linha de base¶
Vamos primeiro avaliar os desempenhos de bagging, floresta aleatória e XGBoost sem técnicas de aprendizado com dados desequilibrados. Nos referimos a esses desempenhos como desempenhos de linha de base.
Os hiperparâmetros são escolhidos da seguinte forma:
Bagging e floresta aleatória: 100 árvores, com profundidade máxima de 20. Foi demonstrado que esses valores fornecem os melhores desempenhos para florestas aleatórias no Capítulo 5, Seleção de Modelos - Floresta aleatória.
XGBoost: 50 árvores, com profundidade máxima de 3 e taxa de aprendizado de 0,3. Foi demonstrado que esses valores fornecem o melhor equilíbrio em termos de desempenho no Capítulo 5, Seleção de Modelos - XGBoost.
Notebook Cell
#### Bagging
# Define classifier
classifier = sklearn.ensemble.BaggingClassifier()
# Set of parameters for which to assess model performances
parameters = {'clf__base_estimator':[sklearn.tree.DecisionTreeClassifier(max_depth=20,random_state=0)],
'clf__bootstrap':[True],
'clf__n_estimators':[100],
'clf__random_state':[0],
'clf__n_jobs':[-1]}
start_time = time.time()
# Fit models and assess performances for all parameters
performances_df=model_selection_wrapper(transactions_df, classifier,
input_features, output_feature,
parameters, scoring,
start_date_training_for_valid,
start_date_training_for_test,
n_folds=n_folds,
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list,
n_jobs=-1)
execution_time_baseline_bagging = time.time()-start_time
# Select parameter of interest (n_estimators)
parameters_dict=dict(performances_df['Parameters'])
performances_df['Parameters summary']=[parameters_dict[i]['clf__n_estimators'] for i in range(len(parameters_dict))]
# Rename to performances_df_baseline_bagging for model performance comparison later in this section
performances_df_baseline_bagging=performances_dfNotebook Cell
summary_performances_baseline_bagging=get_summary_performances(performances_df_baseline_bagging, parameter_column_name="Parameters summary")
summary_performances_baseline_baggingNotebook Cell
#### Random forest
# Define classifier
classifier = sklearn.ensemble.RandomForestClassifier()
parameters = {'clf__max_depth':[20],
'clf__n_estimators':[100],
'clf__random_state':[0],
'clf__n_jobs':[-1]}
start_time = time.time()
# Fit models and assess performances for all parameters
performances_df=model_selection_wrapper(transactions_df, classifier,
input_features, output_feature,
parameters, scoring,
start_date_training_for_valid,
start_date_training_for_test,
n_folds=n_folds,
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list,
n_jobs=-1)
execution_time_baseline_rf = time.time()-start_time
# Select parameter of interest (n_estimators)
parameters_dict=dict(performances_df['Parameters'])
performances_df['Parameters summary']=[parameters_dict[i]['clf__n_estimators'] for i in range(len(parameters_dict))]
# Rename to performances_df_baseline_rf for model performance comparison later in this section
performances_df_baseline_rf=performances_dfNotebook Cell
summary_performances_baseline_rf=get_summary_performances(performances_df_baseline_rf, parameter_column_name="Parameters summary")
summary_performances_baseline_rfNotebook Cell
#### XGBoost
# Define classifier
classifier = xgboost.XGBClassifier()
parameters = {'clf__max_depth':[3],
'clf__n_estimators':[50],
'clf__learning_rate':[0.3],
'clf__random_state':[0],
'clf__n_jobs':[-1]}
start_time = time.time()
# Fit models and assess performances for all parameters
performances_df=model_selection_wrapper(transactions_df, classifier,
input_features, output_feature,
parameters, scoring,
start_date_training_for_valid,
start_date_training_for_test,
n_folds=n_folds,
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list,
n_jobs=-1)
execution_time_baseline_xgboost = time.time()-start_time
# Select parameter of interest (n_estimators)
parameters_dict=dict(performances_df['Parameters'])
performances_df['Parameters summary']=[parameters_dict[i]['clf__n_estimators'] for i in range(len(parameters_dict))]
# Rename to performances_df_baseline_xgboost for model performance comparison later in this section
performances_df_baseline_xgboost=performances_dfNotebook Cell
summary_performances_baseline_xgboost=get_summary_performances(performances_df_baseline_xgboost, parameter_column_name="Parameters summary")
summary_performances_baseline_xgboostOs desempenhos de linha de base são reportados na tabela abaixo. Vale notar que os desempenhos para floresta aleatória e XGBoost são os mesmos reportados no Capítulo 5, Seleção de Modelos - Floresta aleatória e Capítulo 5, Seleção de Modelos - XGBoost, respectivamente.
summary_test_performances = pd.concat([summary_performances_baseline_bagging.iloc[2,:],
summary_performances_baseline_rf.iloc[2,:],
summary_performances_baseline_xgboost.iloc[2,:],
],axis=1)
summary_test_performances.columns=['Baseline Bagging', 'Baseline RF', 'Baseline XGBoost']
summary_test_performancesO XGBoost fornece Precisão Média ligeiramente maior do que floresta aleatória e bagging. O bagging fornece AUC ROC e CP@100 ligeiramente menores do que floresta aleatória e XGBoost. No geral, as três estratégias de ensemble alcançam desempenhos similares.
Bagging balanceado¶
Mantendo os mesmos hiperparâmetros acima (100 árvores com profundidade máxima de 20), vamos avaliar a capacidade do bagging balanceado de melhorar os desempenhos de classificação. Utilizamos subamostragem aleatória, que é o sampler padrão. A razão de desequilíbrio (parâmetro sampling_strategy) é parametrizada para assumir valores no conjunto para o procedimento de seleção de modelos.
Notebook Cell
# Define classifier
classifier = imblearn.ensemble.BalancedBaggingClassifier()
# Set of parameters for which to assess model performances
parameters = {'clf__base_estimator':[sklearn.tree.DecisionTreeClassifier(max_depth=20,random_state=0)],
'clf__n_estimators':[100],
'clf__sampling_strategy':[0.02, 0.05, 0.1, 0.5, 1],
'clf__bootstrap':[True],
'clf__sampler':[imblearn.under_sampling.RandomUnderSampler()],
'clf__random_state':[0],
'clf__n_jobs':[-1]}
start_time = time.time()
# Fit models and assess performances for all parameters
performances_df=model_selection_wrapper(transactions_df, classifier,
input_features, output_feature,
parameters, scoring,
start_date_training_for_valid,
start_date_training_for_test,
n_folds=n_folds,
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list,
n_jobs=1)
execution_time_balanced_bagging = time.time()-start_time
Notebook Cell
# Select parameter of interest (sampling_strategy)
parameters_dict=dict(performances_df['Parameters'])
performances_df['Parameters summary']=[parameters_dict[i]['clf__sampling_strategy'] for i in range(len(parameters_dict))]
# Rename to performances_df_balanced_bagging for model performance comparison later in this section
performances_df_balanced_bagging=performances_dfNotebook Cell
performances_df_balanced_baggingVamos resumir os desempenhos para destacar as razões de desequilíbrio ótimas.
summary_performances_balanced_bagging = get_summary_performances(performances_df_balanced_bagging, parameter_column_name="Parameters summary")
summary_performances_balanced_baggingObservamos resultados conflitantes, pois a razão de desequilíbrio ótima depende da métrica de desempenho. Para melhor visualização, vamos plotar os desempenhos em função da razão de desequilíbrio para as três métricas de desempenho.
get_performances_plots(performances_df_balanced_bagging,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="Imbalance ratio",
summary_performances=summary_performances_balanced_bagging)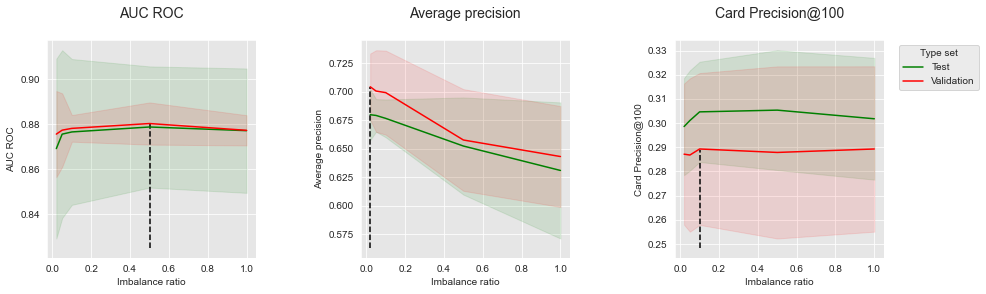
A subamostragem é claramente prejudicial à Precisão Média, onde aumentar a razão de desequilíbrio leva a uma diminuição de desempenho. A maior Precisão Média é obtida para uma razão de desequilíbrio de 0,02, que é a razão de desequilíbrio do conjunto de dados de transações. Uma tendência diferente é observada para AUC ROC e CP@100, onde aumentar a razão de desequilíbrio primeiro leva a melhores desempenhos, antes de atingir algum ótimo após o qual os desempenhos diminuem. Neste experimento, uma razão de desequilíbrio de 0,5 é encontrada como ótima para AUC ROC, enquanto uma razão de desequilíbrio de 0,1 fornece o melhor resultado em termos de CP@100.
Vamos finalmente comparar os desempenhos alcançados com bagging e bagging balanceado.
summary_test_performances = pd.concat([summary_performances_baseline_bagging.iloc[2,:],
summary_performances_balanced_bagging.iloc[2,:]
],axis=1)
summary_test_performances.columns=['Baseline Bagging', 'Balanced Bagging']
summary_test_performancesComo observado acima, o bagging balanceado permite melhorar tanto o AUC ROC quanto o CP@100, mas não parece melhorar a Precisão Média.
Floresta aleatória balanceada¶
A mesma metodologia é aplicada com floresta aleatória balanceada. A razão de desequilíbrio (parâmetro sampling_strategy) é parametrizada para assumir valores no conjunto para o procedimento de seleção de modelos.
Notebook Cell
# Define classifier
classifier = imblearn.ensemble.BalancedRandomForestClassifier()
parameters = {'clf__max_depth':[20],
'clf__n_estimators':[100],
'clf__sampling_strategy':[0.01, 0.05, 0.1, 0.5, 1],
'clf__random_state':[0],
'clf__n_jobs':[-1]}
start_time = time.time()
# Fit models and assess performances for all parameters
performances_df=model_selection_wrapper(transactions_df, classifier,
input_features, output_feature,
parameters, scoring,
start_date_training_for_valid,
start_date_training_for_test,
n_folds=n_folds,
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list,
n_jobs=-1)
execution_time_rf_balanced = time.time()-start_time
Notebook Cell
# Select parameter of interest (sampling_strategy)
parameters_dict = dict(performances_df['Parameters'])
performances_df['Parameters summary'] = [parameters_dict[i]['clf__sampling_strategy'] for i in range(len(parameters_dict))]
# Rename to performances_df_balanced_rf for model performance comparison later in this section
performances_df_balanced_rf=performances_dfNotebook Cell
performances_df_balanced_rfVamos resumir os desempenhos para destacar a razão de desequilíbrio ótima e plotar os desempenhos em função da razão de desequilíbrio para as três métricas de desempenho.
summary_performances_balanced_rf=get_summary_performances(performances_df=performances_df_balanced_rf, parameter_column_name="Parameters summary")
summary_performances_balanced_rfget_performances_plots(performances_df_balanced_rf,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="Imbalance ratio",
summary_performances=summary_performances_balanced_rf)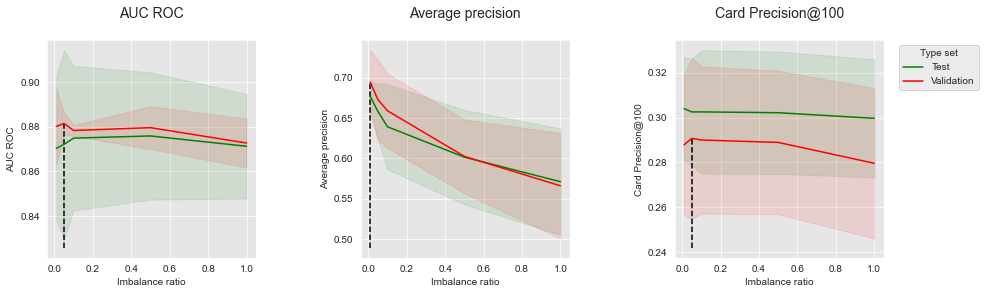
Os resultados são qualitativamente similares ao bagging balanceado. Aumentar a razão de desequilíbrio é prejudicial à Precisão Média, mas pode levar a melhorias marginais de desempenho para AUC ROC e CP@100. O ótimo é encontrado para uma razão de desequilíbrio de 0,05.
Vamos finalmente comparar os desempenhos alcançados com floresta aleatória e floresta aleatória balanceada.
summary_test_performances = pd.concat([summary_performances_baseline_rf.iloc[2,:],
summary_performances_balanced_rf.iloc[2,:]
],axis=1)
summary_test_performances.columns=['Baseline RF', 'Balanced RF']
summary_test_performancesO aumento de desempenho em termos de AUC ROC e CP@100 é apenas marginal. No geral, a floresta aleatória balanceada não permitiu melhorar os desempenhos.
XGBoost ponderado¶
Para o XGBoost ponderado, o peso de classe é definido com o parâmetro scale_pos_weight. Mantendo os mesmos hiperparâmetros do XGBoost de linha de base (50 árvores com profundidade máxima de 3 e taxa de aprendizado de 0,3), variamos o parâmetro scale_pos_weight para assumir valores no conjunto .
Notebook Cell
classifier = xgboost.XGBClassifier()
parameters = {'clf__max_depth':[3],
'clf__n_estimators':[50],
'clf__learning_rate':[0.3],
'clf__scale_pos_weight':[1,5,10,50,100],
'clf__random_state':[0],
'clf__n_jobs':[-1]}
start_time = time.time()
# Fit models and assess performances for all parameters
performances_df=model_selection_wrapper(transactions_df, classifier,
input_features, output_feature,
parameters, scoring,
start_date_training_for_valid,
start_date_training_for_test,
n_folds=n_folds,
delta_train=delta_train,
delta_delay=delta_delay,
delta_assessment=delta_assessment,
performance_metrics_list_grid=performance_metrics_list_grid,
performance_metrics_list=performance_metrics_list,
n_jobs=-1)
execution_time_weighted_xgboost = time.time()-start_time
Notebook Cell
# Select parameter of interest (scale_pos_weight)
parameters_dict = dict(performances_df['Parameters'])
performances_df['Parameters summary'] = [parameters_dict[i]['clf__scale_pos_weight'] for i in range(len(parameters_dict))]
# Rename to performances_df_weighted_xgboost for model performance comparison later in this section
performances_df_weighted_xgboost=performances_dfNotebook Cell
performances_df_weighted_xgboostVamos resumir os desempenhos para destacar os pesos de classe ótimos e plotar os desempenhos em função do peso de classe para as três métricas de desempenho.
summary_performances_weighted_xgboost=get_summary_performances(performances_df=performances_df_weighted_xgboost, parameter_column_name="Parameters summary")
summary_performances_weighted_xgboostget_performances_plots(performances_df_weighted_xgboost,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="Class weight",
summary_performances=summary_performances_weighted_xgboost)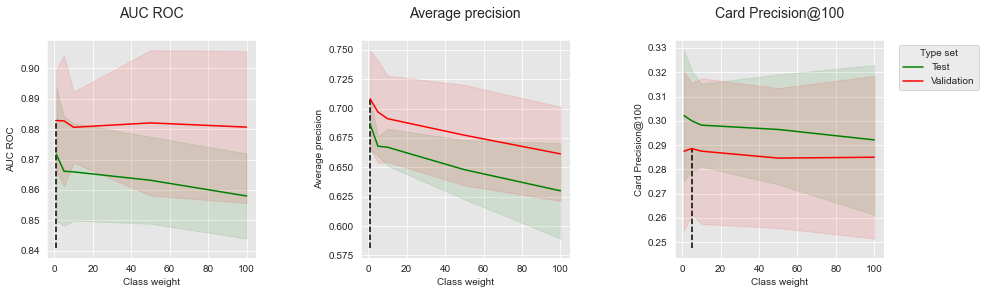
Os resultados mostram que, para todas as métricas, aumentar o peso de classe leva a uma diminuição de desempenho no conjunto de teste. O melhor peso de classe é, portanto, 1, ou seja, um peso igual para a classe minoritária e majoritária.
summary_test_performances = pd.concat([summary_performances_baseline_xgboost.iloc[2,:],
summary_performances_weighted_xgboost.iloc[2,:]
],axis=1)
summary_test_performances.columns=['Baseline XGBoost', 'Weighted XGBoost']
summary_test_performancesOs desempenhos obtidos com o XGBoost ponderado são, portanto, os mesmos obtidos com nossa linha de base.
Resumo¶
Vamos finalmente resumir em uma única tabela os resultados no conjunto de dados de transações simuladas. As métricas de desempenho são reportadas por linhas, enquanto os métodos de ensemble são reportados por colunas.
Notebook Cell
summary_test_performances = pd.concat([summary_performances_baseline_bagging.iloc[2,:],
summary_performances_balanced_bagging.iloc[2,:],
summary_performances_baseline_rf.iloc[2,:],
summary_performances_balanced_rf.iloc[2,:],
summary_performances_baseline_xgboost.iloc[2,:],
summary_performances_weighted_xgboost.iloc[2,:],
],axis=1)
summary_test_performances.columns=['Baseline Bagging', 'Balanced Bagging',
'Baseline RF', 'Balanced RF',
'Baseline XGBoost', 'Weighted XGBoost']
summary_test_performancesAs melhores melhorias foram obtidas para o bagging balanceado, que permitiu melhorar os desempenhos do bagging tanto em termos de AUC ROC quanto de CP@100. Essas melhorias provavelmente se devem a uma maior diversidade de árvores no bagging balanceado, derivada da amostragem aleatória do conjunto de treinamento, levando a menos sobreajuste no ensemble resultante.
Pouca ou nenhuma melhoria foi observada, no entanto, para floresta aleatória balanceada e XGBoost ponderado. Esses resultados ilustram que floresta aleatória e XGBoost são particularmente robustos a dados desequilibrados e sobreajuste.
No geral, os resultados experimentais reportados nesta seção não fornecem melhorias notáveis sobre os ensembles de linha de base. Esses resultados não devem, no entanto, levar à conclusão de que combinar métodos de ensemble com técnicas de aprendizado com dados desequilibrados tem pouco benefício. Em vez disso, eles mostram que (i) métodos de ensemble como floresta aleatória e XGBoost fornecem linhas de base difíceis de melhorar, (ii) técnicas de aprendizado com dados desequilibrados alteram a fronteira de decisão do classificador resultante, e (iii) técnicas de aprendizado com dados desequilibrados podem melhorar os desempenhos preditivos dependendo de qual métrica de desempenho é usada.
Salvamento dos resultados¶
Vamos finalmente salvar os resultados de desempenho e os tempos de execução.
performances_df_dictionary={
"Baseline Bagging": performances_df_baseline_bagging,
"Baseline RF": performances_df_baseline_rf,
"Baseline XGBoost": performances_df_baseline_xgboost,
"Balanced Bagging": performances_df_balanced_bagging,
"Balanced RF": performances_df_balanced_rf,
"Weighted XGBoost": performances_df_weighted_xgboost
}
execution_times=[execution_time_baseline_bagging,
execution_time_baseline_rf,
execution_time_baseline_xgboost,
execution_time_balanced_bagging,
execution_time_rf_balanced,
execution_time_weighted_xgboost
]filehandler = open('performances_ensembles.pkl', 'wb')
pickle.dump((performances_df_dictionary, execution_times), filehandler)
filehandler.close()- Fernández, A., Garcı́a, S., Galar, M., Prati, R. C., Krawczyk, B., & Herrera, F. (2018). Learning from imbalanced data sets. Springer.
- Haixiang, G., Yijing, L., Shang, J., Mingyun, G., Yuanyue, H., & Bing, G. (2017). Learning from class-imbalanced data: Review of methods and applications. Expert Systems with Applications, 73, 220–239.
- Bontempi, G. (2021). Statistical foundations of machine learning, 2nd edition. Université Libre de Bruxelles.
- Friedman, J., Hastie, T., & Tibshirani, R. (2001). The elements of statistical learning (Vol. 1). Springer series in statistics New York.
- Breiman, L. (1996). Bagging predictors. Machine Learning, 24(2), 123–140.
- Breiman, L. (2001). Random forests. Machine Learning, 45(1), 5–32.
- Freund, Y., & Schapire, R. E. (1997). A decision-theoretic generalization of on-line learning and an application to boosting. Journal of Computer and System Sciences, 55(1), 119–139.
- Chen, T., & Guestrin, C. (2016). Xgboost: A scalable tree boosting system. Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, 785–794.
- Dorogush, A. V., Ershov, V., & Gulin, A. (2018). CatBoost: gradient boosting with categorical features support. arXiv Preprint arXiv:1810.11363.
- Ke, G., Meng, Q., Finley, T., Wang, T., Chen, W., Ma, W., Ye, Q., & Liu, T.-Y. (2017). Lightgbm: A highly efficient gradient boosting decision tree. Advances in Neural Information Processing Systems, 30, 3146–3154.
- Maclin, R., & Opitz, D. (1997). An empirical evaluation of bagging and boosting. AAAI/IAAI, 1997, 546–551.
- Chen, C., Liaw, A., Breiman, L., & others. (2004). Using random forest to learn imbalanced data. University of California, Berkeley, 110(1–12), 24.
- Priscilla, C. V., & Prabha, D. P. (2019). Credit Card Fraud Detection: A Systematic Review. International Conference on Information, Communication and Computing Technology, 290–303.
- Bentéjac, C., Csörgo, A., & Martı́nez-Muñoz, G. (2021). A comparative analysis of gradient boosting algorithms. Artificial Intelligence Review, 54(3), 1937–1967.
- Friedman, J. H. (2001). Greedy function approximation: a gradient boosting machine. Annals of Statistics, 1189–1232.