Esta seção reporta os desempenhos obtidos em dados do mundo real usando técnicas de aprendizado com dados desequilibrados. O conjunto de dados é o mesmo do Capítulo 3, Seção 5. Os resultados são reportados seguindo a metodologia usada nas seções anteriores com dados simulados.
Primeiro reportamos os desempenhos para técnicas sensíveis ao custo, variando o peso de classe para modelos de árvores de decisão e regressão logística. Em seguida, reportamos os desempenhos para técnicas de reamostragem usando árvores de decisão, variando a razão de desequilíbrio com SMOTE, RUS e uma combinação de SMOTE e RUS. Finalmente, reportamos os resultados usando técnicas de ensemble, variando a razão de desequilíbrio com modelos de Bagging e Florestas Aleatórias, e variando o peso de classe com um modelo XGBoost.
Notebook Cell
# Initialization: Load shared functions
# Load shared functions
!curl -O https://raw.githubusercontent.com/Fraud-Detection-Handbook/fraud-detection-handbook/main/Chapter_References/shared_functions.py
%run shared_functions.py
#%run ../Chapter_References/shared_functions.ipynbSensível ao custo¶
Seguimos a metodologia reportada na Seção 6.2 (Dados de transações), salvando os resultados em um arquivo pickle performances_cost_sensitive_real_world_data.pkl. Os desempenhos e tempos de execução podem ser recuperados carregando o arquivo pickle.
filehandler = open('images/performances_cost_sensitive_real_world_data.pkl', 'rb')
(performances_df_dictionary, execution_times) = pickle.load(filehandler)Árvore de decisão¶
Os resultados para modelos de árvore de decisão são reportados abaixo. A profundidade da árvore foi definida como 6 (fornecendo os melhores desempenhos conforme reportado no Capítulo 5). Variamos o peso de classe na faixa de 0,01 a 1, com o seguinte conjunto de valores possíveis: .
performances_df_dt=performances_df_dictionary['Decision Tree']
summary_performances_dt=get_summary_performances(performances_df_dt, parameter_column_name="Parameters summary")
get_performances_plots(performances_df_dt,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="Class weight for the majority class",
summary_performances=summary_performances_dt)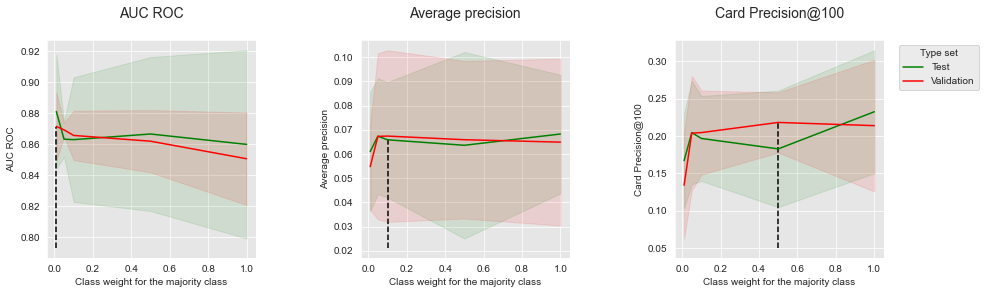
Lembremos que um peso de classe de 1 consiste em dar o mesmo peso às classes positiva e negativa, enquanto um peso de classe de 0,01 consiste em dar 100 vezes mais peso à classe positiva (favorecendo assim a detecção de instâncias de fraude). Observamos também que um peso de classe de 1 fornece os mesmos resultados do Capítulo 5.
Os resultados mostram que diminuir o peso de classe permite aumentar os desempenhos em termos de AUC ROC, mas diminui os desempenhos em termos de Precisão Média e CP@100, particularmente para valores muito baixos (próximos de 0,01).
Os desempenhos em função dos melhores parâmetros são resumidos abaixo.
summary_performances_dtEsses resultados seguem as mesmas tendências obtidas com os dados simulados: O aprendizado sensível ao custo é eficaz para melhorar os desempenhos de AUC ROC, mas prejudicial à Precisão Média.
Regressão logística¶
Os resultados para regressão logística são reportados abaixo. O parâmetro de regularização C foi definido como 0,1 (fornecendo os melhores desempenhos conforme reportado no Capítulo 5).
performances_df_lr=performances_df_dictionary['Logistic Regression']
summary_performances_lr=get_summary_performances(performances_df_lr, parameter_column_name="Parameters summary")
get_performances_plots(performances_df_lr,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="Class weight for the majority class",
summary_performances=summary_performances_lr)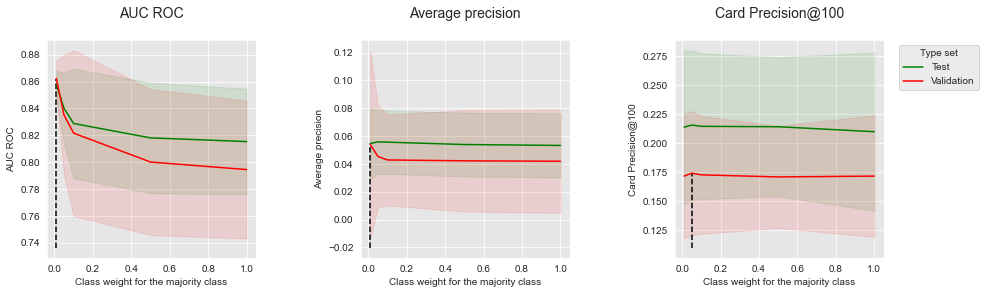
summary_performances_lrSemelhante às árvores de decisão, diminuir o peso de classe da classe majoritária fornece um aumento de desempenho em termos de AUC ROC. O impacto na Precisão Média e CP@100 é, no entanto, misto: o único impacto notável é uma melhoria da Precisão Média nos dados de validação, que, no entanto, tem um custo de maior variância (como é visível pelo grande intervalo de confiança).
Reamostragem¶
Seguimos a metodologia reportada na Seção 6.3 (Dados de transações), salvando os resultados no arquivo pickle performances_resampling_real_world_data.pkl. Os desempenhos e tempos de execução podem ser recuperados carregando o arquivo. Os desempenhos foram avaliados para SMOTE, RUS e uma reamostragem combinada com SMOTE e RUS. Todos os experimentos usaram modelos de árvore de decisão, cuja profundidade foi definida como 6 (fornecendo os melhores desempenhos conforme reportado no Capítulo 5).
filehandler = open('images/performances_resampling_real_world_data.pkl', 'rb')
(performances_df_dictionary, execution_times) = pickle.load(filehandler)SMOTE¶
Os resultados para SMOTE são reportados abaixo. A razão de desequilíbrio foi variada na faixa de 0,01 a 1, com o seguinte conjunto de valores possíveis: . Lembremos que quanto maior a razão de desequilíbrio, mais forte a reamostragem. Uma razão de desequilíbrio de 0,01 produz uma distribuição próxima à original (onde o percentual de fraudes é próximo de 0,25%). Uma razão de desequilíbrio de 1 produz uma distribuição que contém tantas instâncias positivas quanto negativas.
performances_df_SMOTE=performances_df_dictionary['SMOTE']
summary_performances_SMOTE=get_summary_performances(performances_df_SMOTE, parameter_column_name="Parameters summary")
get_performances_plots(performances_df_SMOTE,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="Imbalance ratio",
summary_performances=summary_performances_SMOTE)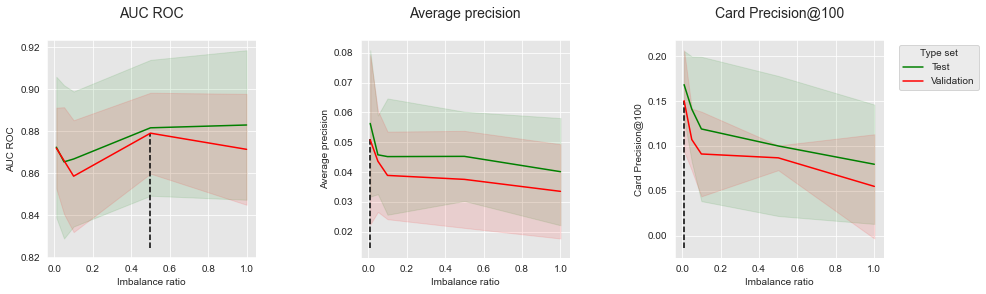
summary_performances_SMOTEOs resultados mostram que os benefícios do SMOTE são mistos. Criar novas instâncias sintéticas da classe positiva tende a aumentar os desempenhos de AUC ROC (gráfico à esquerda). No entanto, vem acompanhado de uma diminuição de desempenho para as métricas de Precisão Média e CP@100. Esses resultados estão alinhados com os observados nos dados simulados (Seção 6.3, Sobreamostragem).
Subamostragem aleatória¶
Os resultados para subamostragem aleatória (RUS) são reportados abaixo.
performances_df_RUS=performances_df_dictionary['RUS']
summary_performances_RUS=get_summary_performances(performances_df_RUS, parameter_column_name="Parameters summary")
get_performances_plots(performances_df_RUS,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="Imbalance ratio",
summary_performances=summary_performances_RUS)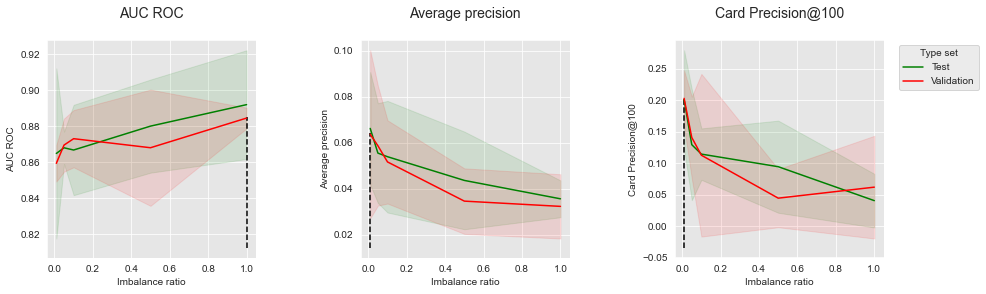
summary_performances_RUSDa mesma forma, a RUS permite melhorar os desempenhos em termos de AUC ROC, mas vem com uma diminuição notável de desempenho em termos de AP e CP@100. Esses resultados também estão alinhados com os observados nos dados simulados (Seção 6.3, Subamostragem).
Combinando SMOTE com subamostragem¶
Reportamos finalmente os resultados para reamostragem combinada (SMOTE seguido de RUS).
performances_df_combined=performances_df_dictionary['Combined']
summary_performances_combined=get_summary_performances(performances_df_combined, parameter_column_name="Parameters summary")
get_performances_plots(performances_df_combined,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="Imbalance ratio",
summary_performances=summary_performances_combined)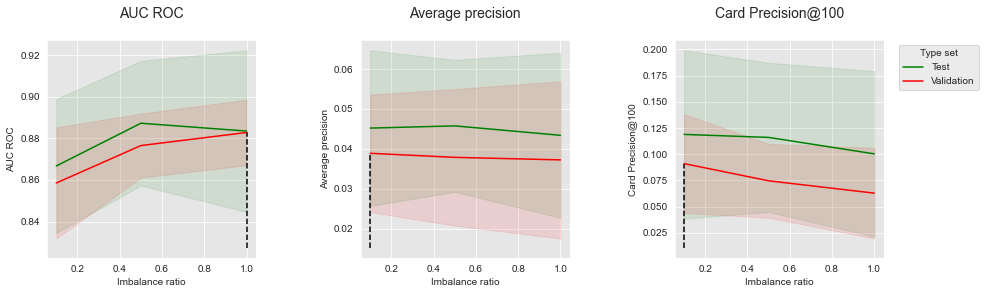
summary_performances_combinedNovamente, observamos que a reamostragem permite melhorar os desempenhos em termos de AUC ROC, mas diminui os desempenhos em termos de AP e CP@100. Os resultados estão alinhados com os observados nos dados simulados (Seção 6.3, Combinação).
Ensembling¶
Seguimos a metodologia reportada na Seção 6.4 (Dados de transações), salvando os resultados em um arquivo pickle performances_resampling_real_world_data.pkl. Os desempenhos e tempos de execução podem ser recuperados carregando o arquivo pickle.
filehandler = open('images/performances_ensembles_real_world_data.pkl', 'rb')
(performances_df_dictionary, execution_times) = pickle.load(filehandler)Os desempenhos foram avaliados para bagging balanceado, floresta aleatória balanceada e XGBoost ponderado.
Linha de base¶
Para a linha de base, os hiperparâmetros foram escolhidos da seguinte forma:
Bagging e floresta aleatória: 100 árvores, com profundidade máxima de 10. Foi demonstrado que esses valores fornecem os melhores desempenhos para florestas aleatórias no Capítulo 5, Seleção de Modelos - Floresta aleatória.
XGBoost: 100 árvores, com profundidade máxima de 6 e taxa de aprendizado de 0,1. Foi demonstrado que esses valores fornecem o melhor equilíbrio em termos de desempenho no Capítulo 5, Seleção de Modelos - XGBoost.
Os desempenhos de linha de base são reportados na tabela abaixo. Vale notar que os desempenhos para floresta aleatória e XGBoost são os mesmos reportados no Capítulo 5, Seleção de Modelos - Floresta aleatória e Capítulo 5, Seleção de Modelos - XGBoost, respectivamente.
Notebook Cell
performances_df_baseline_bagging=performances_df_dictionary['Baseline Bagging']
summary_performances_baseline_bagging=get_summary_performances(performances_df_baseline_bagging, parameter_column_name="Parameters summary")
performances_df_baseline_rf=performances_df_dictionary['Baseline RF']
summary_performances_baseline_rf=get_summary_performances(performances_df_baseline_rf, parameter_column_name="Parameters summary")
performances_df_baseline_xgboost=performances_df_dictionary['Baseline XGBoost']
summary_performances_baseline_xgboost=get_summary_performances(performances_df_baseline_xgboost, parameter_column_name="Parameters summary")
summary_test_performances = pd.concat([summary_performances_baseline_bagging.iloc[2,:],
summary_performances_baseline_rf.iloc[2,:],
summary_performances_baseline_xgboost.iloc[2,:],
],axis=1)
summary_test_performances.columns=['Baseline Bagging', 'Baseline RF', 'Baseline XGBoost']
summary_test_performancesObservou-se que o XGBoost fornece melhores desempenhos do que a floresta aleatória para todas as métricas de desempenho, como já reportado em Comparação de desempenhos de modelos: Resumo. Os desempenhos do bagging foram equivalentes à floresta aleatória em termos de AUC ROC, mas menores em termos de Precisão Média e CP@100.
Bagging balanceado¶
Semelhante a Bagging balanceado com dados simulados, a razão de desequilíbrio (parâmetro sampling_strategy) foi parametrizada para assumir valores no conjunto para o procedimento de seleção de modelos. O número de árvores e a profundidade máxima foram definidos como 100 e 10 (como com o bagging de linha de base).
Notebook Cell
performances_df_balanced_bagging=performances_df_dictionary['Balanced Bagging']
performances_df_balanced_baggingVamos resumir os desempenhos para destacar a razão de desequilíbrio ótima e plotar os desempenhos em função da razão de desequilíbrio para as três métricas de desempenho.
summary_performances_balanced_bagging=get_summary_performances(performances_df_balanced_bagging, parameter_column_name="Parameters summary")
summary_performances_balanced_baggingget_performances_plots(performances_df_balanced_bagging,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="Imbalance ratio",
summary_performances=summary_performances_balanced_bagging)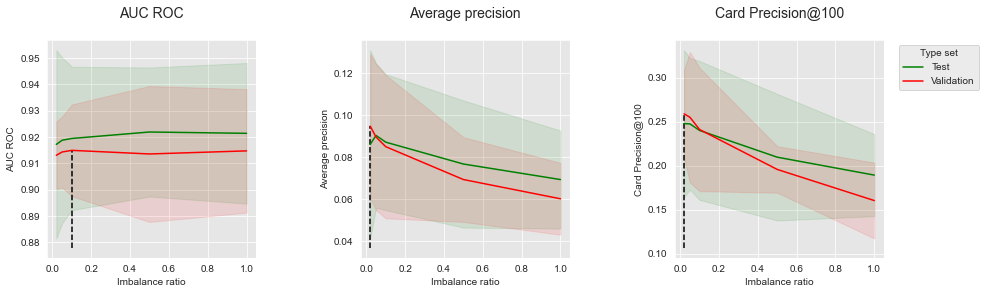
Os resultados mostram que aumentar a razão de desequilíbrio leva a uma diminuição tanto da Precisão Média quanto do CP@100. A tendência é diferente com o AUC ROC, onde aumentar a razão de desequilíbrio primeiro leva a uma ligeira melhoria da métrica, antes de atingir um platô. Vale notar que os resultados são qualitativamente similares a Bagging balanceado com dados simulados para AUC ROC e Precisão Média.
Floresta aleatória balanceada¶
Semelhante a Floresta aleatória balanceada com dados simulados, a razão de desequilíbrio (parâmetro sampling_strategy) foi parametrizada para assumir valores no conjunto para o procedimento de seleção de modelos. O número de árvores e a profundidade máxima foram definidos como 100 e 10 (como com a floresta aleatória de linha de base).
Notebook Cell
performances_df_balanced_rf=performances_df_dictionary['Balanced RF']
performances_df_balanced_rfVamos resumir os desempenhos para destacar a razão de desequilíbrio ótima e plotar os desempenhos em função da razão de desequilíbrio para as três métricas de desempenho.
summary_performances_balanced_rf=get_summary_performances(performances_df_balanced_rf, parameter_column_name="Parameters summary")
summary_performances_balanced_rf
get_performances_plots(performances_df_balanced_rf,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="Imbalance ratio",
summary_performances=summary_performances_balanced_rf)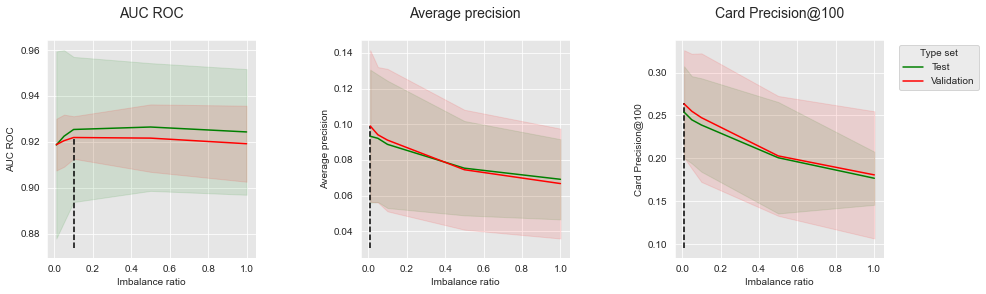
Os resultados seguem as mesmas tendências do bagging balanceado: aumentar a razão de desequilíbrio é prejudicial à Precisão Média e ao CP@100, mas pode ligeiramente aumentar o AUC ROC. Os resultados são qualitativamente similares a Floresta aleatória balanceada com dados simulados para AUC ROC e Precisão Média.
XGBoost ponderado¶
Finalmente, semelhante a XGBoost ponderado com dados simulados, variamos o parâmetro scale_pos_weight para assumir valores no conjunto . Os mesmos hiperparâmetros do XGBoost de linha de base foram mantidos (100 árvores com profundidade máxima de 6 e taxa de aprendizado de 0,1).
Notebook Cell
performances_df_weighted_xgboost=performances_df_dictionary['Weighted XGBoost']
performances_df_weighted_xgboost
Vamos resumir os desempenhos para destacar a razão de desequilíbrio ótima e plotar os desempenhos em função do peso de classe para as três métricas de desempenho.
summary_performances_weighted_xgboost=get_summary_performances(performances_df_weighted_xgboost, parameter_column_name="Parameters summary")
summary_performances_weighted_xgboost
get_performances_plots(performances_df_weighted_xgboost,
performance_metrics_list=['AUC ROC', 'Average precision', 'Card Precision@100'],
expe_type_list=['Test','Validation'], expe_type_color_list=['#008000','#FF0000'],
parameter_name="Class weight",
summary_performances=summary_performances_weighted_xgboost)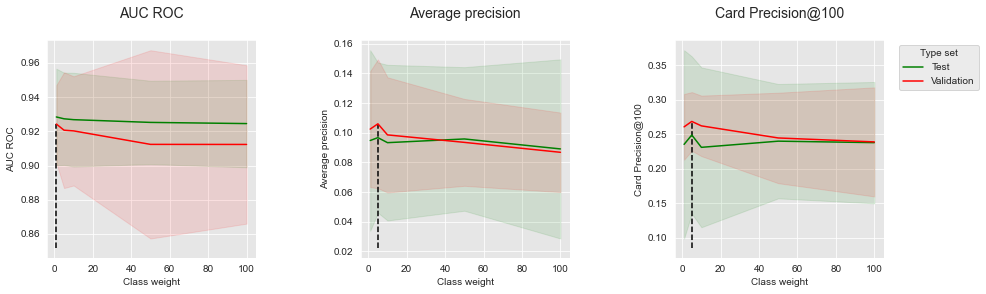
Ao contrário do bagging balanceado e da floresta aleatória balanceada, aumentar o peso de classe da classe minoritária permite melhorar ligeiramente os desempenhos em termos de Precisão Média e CP@100. As melhorias são observadas apenas para um ligeiro aumento do peso de classe (de 1 para 5). Valores mais altos levam a ligeiras diminuições de desempenho. Para o AUC ROC, o peso de classe ótimo é encontrado como 1 (custo igual para as classes minoritária e majoritária).
Resumo¶
Vamos finalmente resumir em uma única tabela os resultados no conjunto de dados do mundo real. As métricas de desempenho são reportadas por linhas, enquanto os métodos de ensemble são reportados por colunas.
Notebook Cell
summary_test_performances = pd.concat([summary_performances_baseline_bagging.iloc[2,:],
summary_performances_balanced_bagging.iloc[2,:],
summary_performances_baseline_rf.iloc[2,:],
summary_performances_balanced_rf.iloc[2,:],
summary_performances_baseline_xgboost.iloc[2,:],
summary_performances_weighted_xgboost.iloc[2,:],
],axis=1)
summary_test_performances.columns=['Baseline Bagging', 'Balanced Bagging',
'Baseline RF', 'Balanced RF',
'Baseline XGBoost', 'Weighted XGBoost']
summary_test_performancesAs melhores melhorias foram observadas para bagging balanceado e floresta aleatória balanceada, para os quais foram obtidos melhores desempenhos em comparação com bagging e floresta aleatória de linha de base. No entanto, como observamos para os dados simulados, os benefícios da reamostragem provavelmente se devem a uma maior diversidade das árvores que compõem os ensembles, levando a uma diminuição do fenômeno de sobreajuste. Em particular, a razão de desequilíbrio ótima para Precisão Média e CP@100 foi encontrada como a mais baixa (0,01), o que mostra que a melhor estratégia para essas métricas era evitar reequilibrar os conjuntos de treinamento.
Pelo contrário, observamos que reequilibrar os conjuntos de treinamento poderia melhorar ligeiramente os desempenhos em termos de AUC ROC. As melhorias foram observadas para razões de desequilíbrio variando de 0,1 a 0,5, levando a um ligeiro aumento de cerca de 1% do AUC ROC (de 0,91 para 0,92). Além de permitir um ligeiro aumento nos desempenhos, vale notar que reequilibrar o conjunto de dados com técnicas de subamostragem poderia acelerar os tempos de computação em até 20%.
Assim como para os resultados obtidos nos dados simulados, esses experimentos sugerem que o reequilíbrio pode ajudar a melhorar os desempenhos em termos de AUC ROC ou acelerar o tempo de treinamento de um ensemble. No entanto, pareceu que manter todos os dados de treinamento era a melhor estratégia se Precisão Média e CP@100 são as métricas de desempenho a otimizar.
No geral, os melhores desempenhos foram obtidos com o XGBoost para as três métricas. Assim como para os dados simulados, modificar o peso de classe por meio do XGBoost ponderado não permitiu melhorar significativamente os desempenhos, ilustrando a robustez do XGBoost em cenários de desequilíbrio de classes.